在大数据的HBase中与Hive中都有用到列(族)式存储,列式存储被广泛应用,有关于HBase讲解,请访问我的
https://yq.aliyun.com/articles/376750?spm=a2c4e.11155435.0.0.62bc19c8kgVjfV。
今天来说一下什么是列式存储。
首先行式存储大家都知道,就是一行一行的存储,传统的关系型数据库都是这样存储的,
列式存储简单的理解就是将一列数据单独存储在一个文件中,但是正真的存储并不是这样子。假如说有一张表,两个列
column1,column2,我们想象的可能会如下图所示
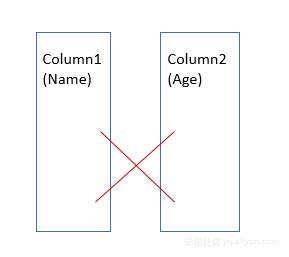
但是在分布式多线程,对进程访问数据的时候,是不会产生这种形式,因为在大数据的MapReduce或Spark中的任务中,
每一个子任务都会读取一部分的数据,假如我们现在有很多Map来并行读取,所有的Map task在逻辑上都必须是一样的,
假如现在两个Map,要分别读取两个文件,而在图中column1与column2数据类型都不一样,压缩算法也不一样,
读取方法不一样,所以没有办法将文件分配哪个Map task处理。
列式存储到底是怎么存储的呢,再看下面的图
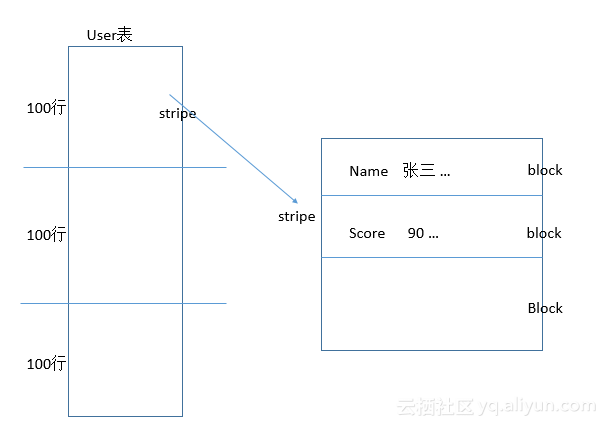
假如我们一个User表的文件,事实上一个表的所有数据都存在一个表中,我们User表中有很多行数据,首先我们先横向的切分,
每一百行切分,我们起个名字叫stripe,第一个stripe存前100行用户数据,再看右面部分的单个stripe,我们再次切分为多个
block块(block里才是列存),第一个block存前100行中Name列的数据,第二个存这100行中Score列的数据。讲到这里也就是说,
数据先安照行来切,然后针对行再做列存。
好处:
针对上面所说在执行MR或spark任务时候,有多个map task同时执行,那么我们每个stripe对应一个map task,
这样每个map task处理的逻辑都是一样的。
假如我们要读取Name是张三的数据,Map task内部只读存Name列的block就好了。
这里需要注意的是,在所有的查询分析器中,仍然需要将查询出的列的信息拼出成行,放在内存中做计算。
另外一个不得不提的是,列式存储天生就是适合压缩,因为同一列里面的数据类型基本是相同,笔者在之前使用普通的gzip压缩,200MB的字符串数据,经过压缩之后只剩下8MB。当然gzip并不属于增量压缩,我们可以选择增量压缩的方式来满足一些数据的随机查找。
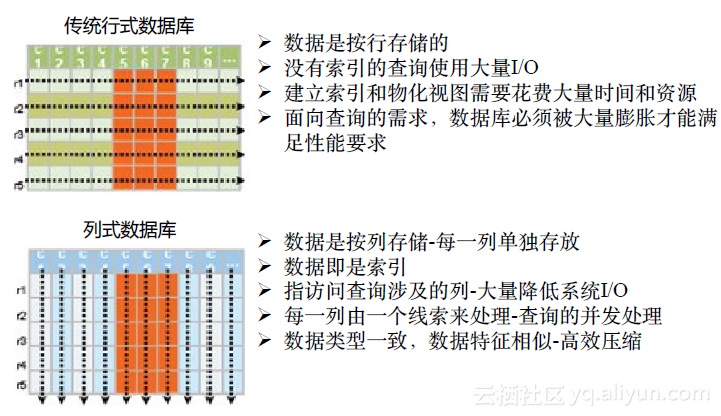
来看一下各自特点。
上述所写如有不对之处,还请各位前辈指出赐教。--五维空间