热门
让你的文档从静态展示到一键部署可操作验证
一键生成视频!用 PAI-EAS 部署 AI 视频生成模型 SVD 工作流
01. 正则表达式概述
什么是jQuery?
03. Vue3 中的条件判断与循环
每天解析一个脚本(七)
02. Vue3 绑定事件的方式
什么是递归树状菜单
01. 5 分钟,Vue3 开发快速上手
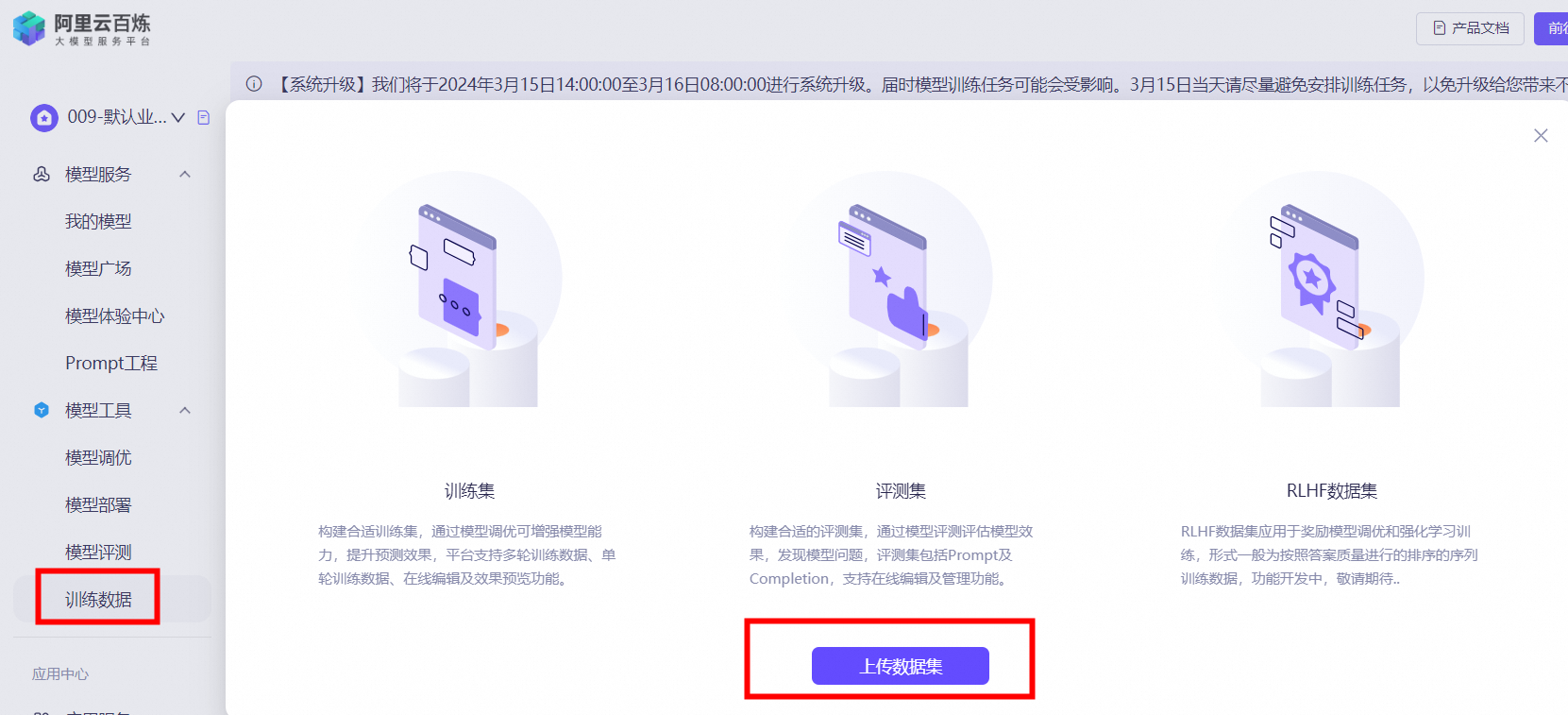
大模型服务平台百炼之模型训练与调优实践分享|快来围观~
分页功能制作
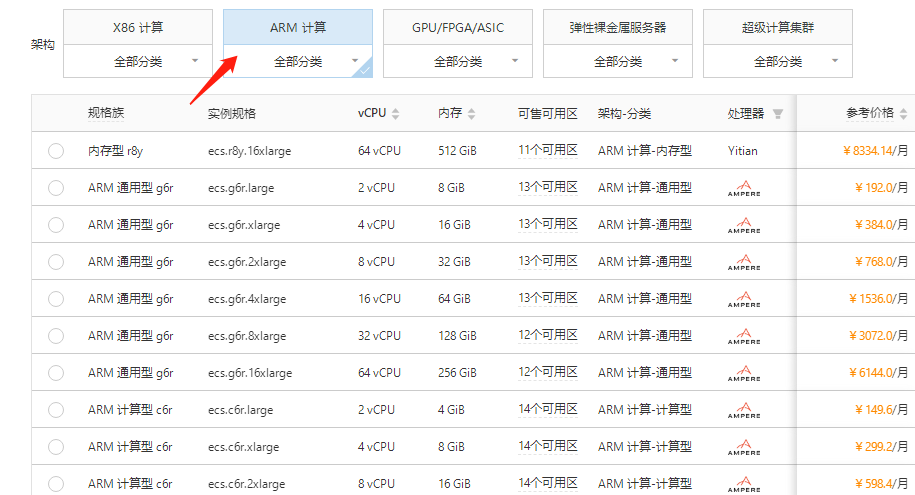
阿里云企业级ARM计算规格族特点、适用场景及收费标准与活动价格参考
终于被我搞掂了 Vue3 + Element 的正确打开方式(直接拿来就用)
超有意思的模糊搜索
java.lang.ClassNotFoundException: javax.xml.bind.DatatypeConverter 报错的解决办法
小小轮播图
Spring Security 5.7 最新配置细节(直接就能用),WebSecurityConfigurerAdapter 已废弃
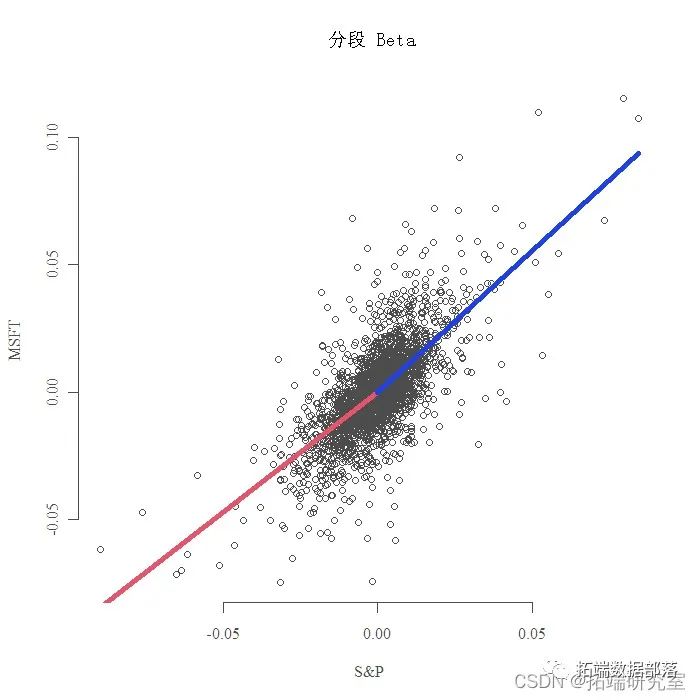
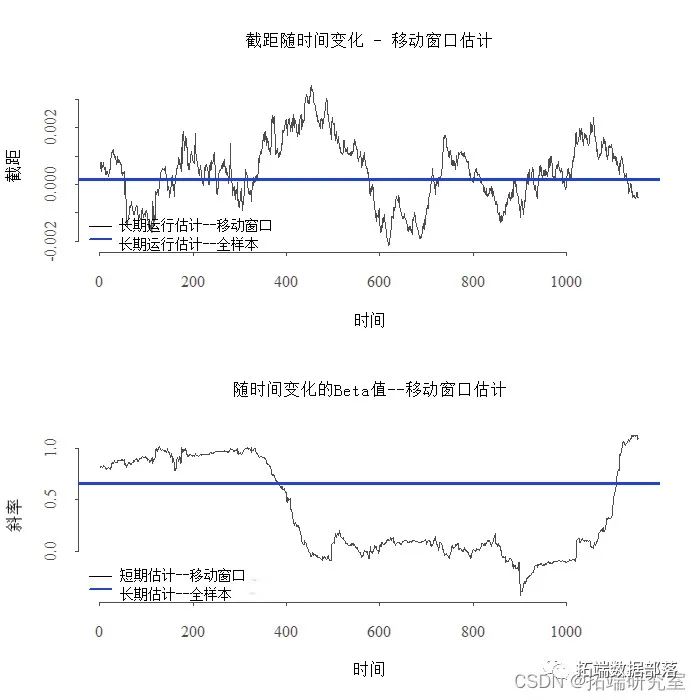
样条曲线分段线性回归模型piecewise regression估计个股beta值分析收益率数据
省、市、区三级联动
最新版 MyBatisPlus 分页插件(直接拿来就可以用)
什么是内置对象
MyBatisPlus 最新版代码生成器(直接拿来就能用,包含自动生成 Vue 模版)
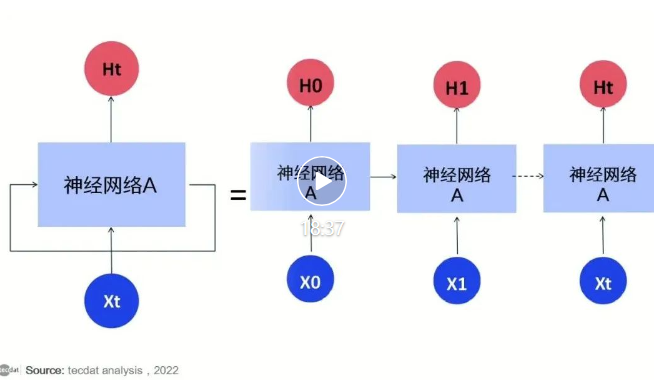
【视频】Python用LSTM长短期记忆神经网络对不稳定降雨量时间序列进行预测分析|数据分享
基础购物车功能
Python 模块与自定义模块
js字符串拼接
Python 的异常处理
Python 文件的读写操作
js的数组
Python 流程控制
Python 列表、元素、字典
阿里云ECS的使用心得
什么是冒泡排序
NumPy 系列教程 001:入门和使用数组
阿里云ECS使用体验
和为严格模式
css怎样设置下滑线?
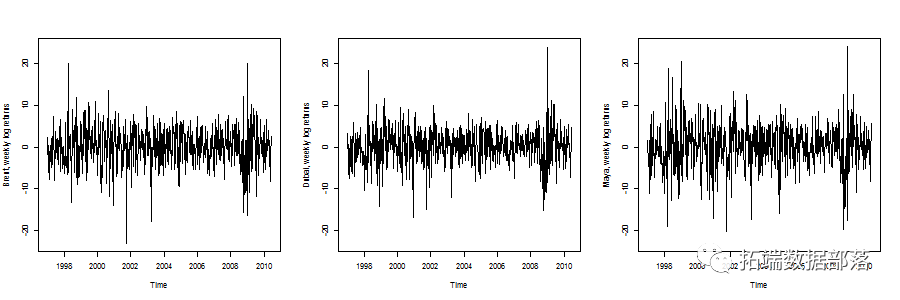
ARMA-GARCH-COPULA模型和金融时间序列案例
干货文:企业 IT 基础架构|(精华篇)
css基础
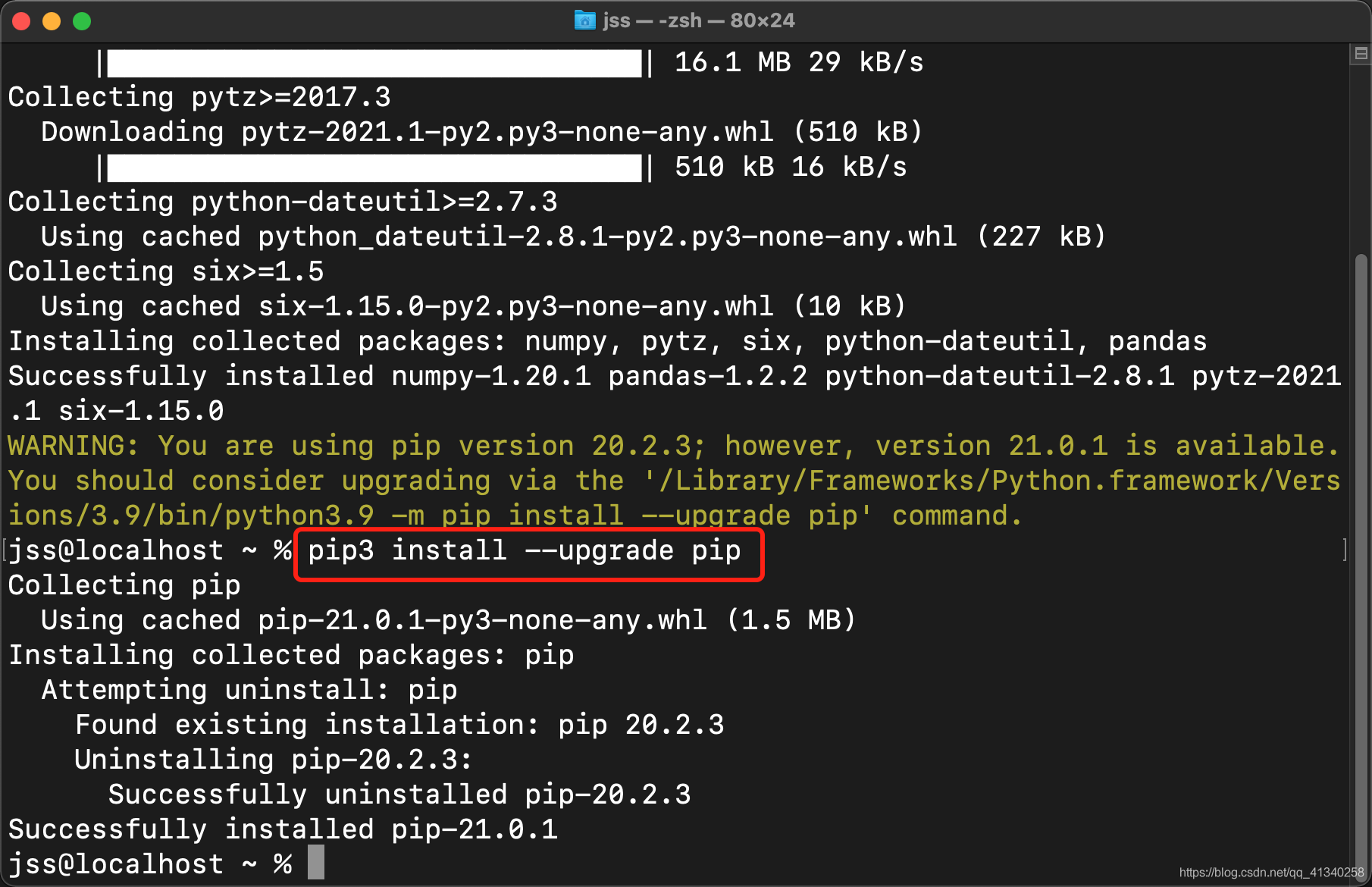
在 Mac 上升级 pip
精通 Spring Boot 系列 15
【视频】时间序列分析:ARIMA-ARCH / GARCH模型分析股票价格-2
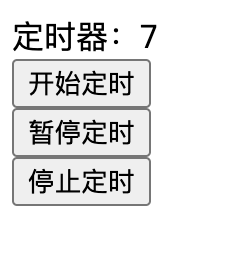
JavaScript 定时器
MQTT 5.0 报文(Packets)入门指南
用收缩估计股票beta系数回归分析Microsoft收益率风险
九宫格抽
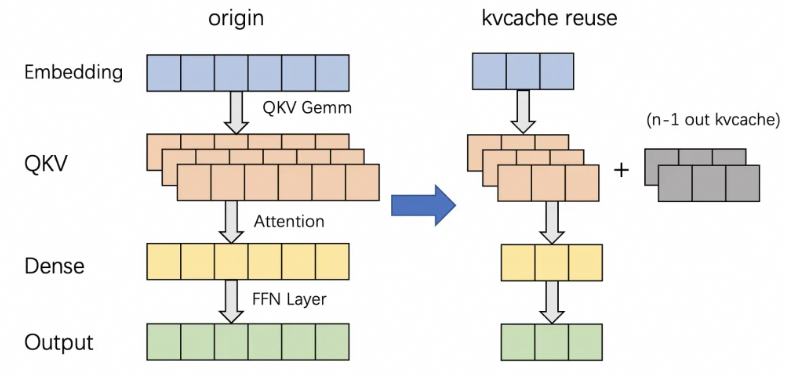
大模型推理优化实践:KV cache复用与投机采样
精通 Spring Boot 系列 14
js的一些注意事项