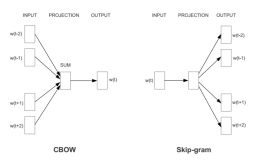
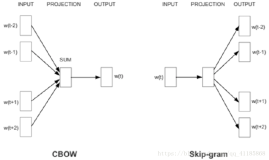
在word2vec原理篇中,我们对word2vec的两种模型CBOW和Skip-Gram,以及两种解法Hierarchical Softmax和Negative Sampling做了总结。这里我们就从实践的角度,使用gensim来学习word2vec。
1. gensim安装与概述
gensim是一个很好用的Python NLP的包,不光可以用于使用word2vec,还有很多其他的API可以用。它封装了google的C语言版的word2vec。当然我们可以可以直接使用C语言版的word2vec来学习,但是个人认为没有gensim的python版来的方便。
安装gensim是很容易的,使用"pip install gensim"即可。但是需要注意的是gensim对numpy的版本有要求,所以安装过程中可能会偷偷的升级你的numpy版本。而windows版的numpy直接装或者升级是有问题的。此时我们需要卸载numpy,并重新下载带mkl的符合gensim版本要求的numpy,下载地址在此:http://www.lfd.uci.edu/~gohlke/pythonlibs/#scipy。安装方法和scikit-learn 和pandas 基于windows单机机器学习环境的搭建这一篇第4步的方法一样。
安装成功的标志是你可以在代码里做下面的import而不出错:
from gensim.models import word2vec
2. gensim word2vec API概述
在gensim中,word2vec 相关的API都在包gensim.models.word2vec中。和算法有关的参数都在类gensim.models.word2vec.Word2Vec中。算法需要注意的参数有:
1) sentences: 我们要分析的语料,可以是一个列表,或者从文件中遍历读出。后面我们会有从文件读出的例子。
2) size: 词向量的维度,默认值是100。这个维度的取值一般与我们的语料的大小相关,如果是不大的语料,比如小于100M的文本语料,则使用默认值一般就可以了。如果是超大的语料,建议增大维度。
3) window:即词向量上下文最大距离,这个参数在我们的算法原理篇中标记为c,window越大,则和某一词较远的词也会产生上下文关系。默认值为5。在实际使用中,可以根据实际的需求来动态调整这个window的大小。如果是小语料则这个值可以设的更小。对于一般的语料这个值推荐在[5,10]之间。
4) sg: 即我们的word2vec两个模型的选择了。如果是0, 则是CBOW模型,是1则是Skip-Gram模型,默认是0即CBOW模型。
5) hs: 即我们的word2vec两个解法的选择了,如果是0, 则是Negative Sampling,是1的话并且负采样个数negative大于0, 则是Hierarchical Softmax。默认是0即Negative Sampling。
6) negative:即使用Negative Sampling时负采样的个数,默认是5。推荐在[3,10]之间。这个参数在我们的算法原理篇中标记为neg。
7) cbow_mean: 仅用于CBOW在做投影的时候,为0,则算法中的xw为上下文的词向量之和,为1则为上下文的词向量的平均值。在我们的原理篇中,是按照词向量的平均值来描述的。个人比较喜欢用平均值来表示xw,默认值也是1,不推荐修改默认值。
8) min_count:需要计算词向量的最小词频。这个值可以去掉一些很生僻的低频词,默认是5。如果是小语料,可以调低这个值。
9) iter: 随机梯度下降法中迭代的最大次数,默认是5。对于大语料,可以增大这个值。
10) alpha: 在随机梯度下降法中迭代的初始步长。算法原理篇中标记为η,默认是0.025。
11) min_alpha: 由于算法支持在迭代的过程中逐渐减小步长,min_alpha给出了最小的迭代步长值。随机梯度下降中每轮的迭代步长可以由iter,alpha, min_alpha一起得出。这部分由于不是word2vec算法的核心内容,因此在原理篇我们没有提到。对于大语料,需要对alpha, min_alpha,iter一起调参,来选择合适的三个值。
以上就是gensim word2vec的主要的参数,下面我们用一个实际的例子来学习word2vec。
3. gensim word2vec实战
我选择的《人民的名义》的小说原文作为语料,语料原文在这里。
拿到了原文,我们首先要进行分词,这里使用结巴分词完成。在中文文本挖掘预处理流程总结中,我们已经对分词的原理和实践做了总结。因此,这里直接给出分词的代码,分词的结果,我们放到另一个文件中。代码如下, 加入下面的一串人名是为了结巴分词能更准确的把人名分出来。

# -*- coding: utf-8 -*- import jieba import jieba.analyse jieba.suggest_freq('沙瑞金', True) jieba.suggest_freq('田国富', True) jieba.suggest_freq('高育良', True) jieba.suggest_freq('侯亮平', True) jieba.suggest_freq('钟小艾', True) jieba.suggest_freq('陈岩石', True) jieba.suggest_freq('欧阳菁', True) jieba.suggest_freq('易学习', True) jieba.suggest_freq('王大路', True) jieba.suggest_freq('蔡成功', True) jieba.suggest_freq('孙连城', True) jieba.suggest_freq('季昌明', True) jieba.suggest_freq('丁义珍', True) jieba.suggest_freq('郑西坡', True) jieba.suggest_freq('赵东来', True) jieba.suggest_freq('高小琴', True) jieba.suggest_freq('赵瑞龙', True) jieba.suggest_freq('林华华', True) jieba.suggest_freq('陆亦可', True) jieba.suggest_freq('刘新建', True) jieba.suggest_freq('刘庆祝', True) with open('./in_the_name_of_people.txt') as f: document = f.read() #document_decode = document.decode('GBK') document_cut = jieba.cut(document) #print ' '.join(jieba_cut) //如果打印结果,则分词效果消失,后面的result无法显示 result = ' '.join(document_cut) result = result.encode('utf-8') with open('./in_the_name_of_people_segment.txt', 'w') as f2: f2.write(result) f.close() f2.close()
拿到了分词后的文件,在一般的NLP处理中,会需要去停用词。由于word2vec的算法依赖于上下文,而上下文有可能就是停词。因此对于word2vec,我们可以不用去停词。
现在我们可以直接读分词后的文件到内存。这里使用了word2vec提供的LineSentence类来读文件,然后套用word2vec的模型。这里只是一个示例,因此省去了调参的步骤,实际使用的时候,你可能需要对我们上面提到一些参数进行调参。
# import modules & set up logging import logging import os from gensim.models import word2vec logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO) sentences = word2vec.LineSentence('./in_the_name_of_people_segment.txt') model = word2vec.Word2Vec(sentences, hs=1,min_count=1,window=3,size=100)
模型出来了,我们可以用来做什么呢?这里给出三个常用的应用。
第一个是最常用的,找出某一个词向量最相近的词集合,代码如下:
req_count = 5 for key in model.wv.similar_by_word('沙瑞金'.decode('utf-8'), topn =100): if len(key[0])==3: req_count -= 1 print key[0], key[1] if req_count == 0: break;
我们看看沙书记最相近的一些3个字的词(主要是人名)如下:
第二个应用是看两个词向量的相近程度,这里给出了书中两组人的相似程度:
print model.wv.similarity('沙瑞金'.decode('utf-8'), '高育良'.decode('utf-8')) print model.wv.similarity('李达康'.decode('utf-8'), '王大路'.decode('utf-8'))
输出如下:
第三个应用是找出不同类的词,这里给出了人物分类题:
print model.wv.doesnt_match(u"沙瑞金 高育良 李达康 刘庆祝".split())
word2vec也完成的很好,输出为"刘庆祝"。
以上就是用gensim学习word2vec实战的所有内容,希望对大家有所帮助。
本文转自刘建平Pinard博客园博客,原文链接:http://www.cnblogs.com/pinard/p/7278324.html,如需转载请自行联系原作者