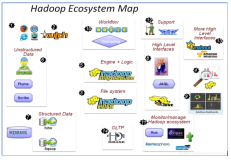
第1章 引言
1.1 编写目的
对关于hadoop的文档及资料进行进一步的整理。
1.2 相关网站
毋庸置疑 http://hadoop.apache.org/
国内 http://www.hadoopor.com/ 专门研究hadoop的,《hadoop开发者》由该站创办,已发4期
中国云计算论坛hadoop专区; http://bbs.chinacloud.cn/showforum-16.aspx
中科院计算所办的hadoop:http://www.hadooper.cn/
1.3 资料及研究成果
http://code.google.com/p/mycloub/
我会搜集更多更好的资料,方便交流。
第2章 hadoop基本命令
2.1 hadoop基本命令
直接输入hadoop得到的语法文档如下:
namenode -format format the DFS filesystem 格式化DFS文件系统
namenode -format format the DFS filesystem 运行第2个namenode
datanode run a DFS datanode 运行DFS的namenode
dfsadmin run a DFS admin client 运行一个DFS的admin客户端
mradmin run a Map-Reduce admin client 运行一个map-reduce文件系统的检查工具
fsck run a DFS filesystem checking utility 运行一个DFS文件系统的检查工具
fs run a generic filesystem user client 运行一个普通的文件系统用户客户端
balancer run a cluster balancing utility 运行MapReduce的jobTracker节点
fetchdt fetch a delegation token from the NameNode 运行一个代理的namenode
jobtracker run the MapReduce job Tracker node 运行一个MapReduce的taskTracker节点
pipes run a Pipes job 运行一个pipes作业
tasktracker run a MapReduce task Tracker node 运行一个MapReduce的taskTracker节点
historyserver run job history servers as a standalone daemon 运行历史服务作为一个单独的线程
job manipulate MapReduce jobs 处理mapReduce作业
queue get information regarding JobQueues
version print the version 版本
jar <jar> run a jar file 运行一个jar
distcp <srcurl> <desturl> copy file or directories recursively 递归地复制文件或者目录
archive -archiveName NAME -p <parent path> <src>* <dest> create a hadoop archive
生成一个hadoop档案
daemonlog get/set the log level for each daemon 获取或设置每个daemon的log级别
2.2 hadoop核心内容
Hadoop框架中最核心的设计就是:MapReduce和HDFS。
l MapReduce的思想是由Google的一篇论文所提及而被广为流传的,简单的一句话解释MapReduce就是“任务的分解与结果的汇总”。
l HDFS是Hadoop分布式文件系统(Hadoop Distributed File System)的缩写,为分布式计算存储提供了底层支持。
2.3 为什么选择hadoop
下面列举hadoop主要的一些特点:
1)扩容能力(Scalable):能可靠地(reliably)存储和处理千兆字节(PB)数据。
2)成本低(Economical):可以通过普通机器组成的服务器群来分发以及处理数据。这些服务器群总计可达数千个节点。
3)高效率(Efficient):通过分发数据,hadoop可以在数据所在的节点上并行地(parallel)处理它们,这使得处理非常的快速。
4)可靠性(Reliable):hadoop能自动地维护数据的多份复制,并且在任务失败后能自动地重新部署(redeploy)计算任务。
2.4 HDFS设计特点
下面说说HDFS的几个设计特点(对于框架设计值得借鉴):
1. Block的放置
默认不配置。一个Block会有三份备份,一份放在NameNode指定的DataNode,另一份放在与指定DataNode非同一Rack上的DataNode,最后一份放在与指定DataNode同一Rack上的DataNode上。
备份无非就是为了数据安全,考虑同一Rack的失败情况以及不同Rack之间数
据拷贝性能问题就采用这种配置方式。
2. 心跳检测
心跳检测DataNode的健康状况,如果发现问题就采取数据备份的方式来保证数据的安全性。
3. 数据复制
数据复制(场景为DataNode失败、需要平衡DataNode的存储利用率和需要平衡DataNode数据交互压力等情况) 这里先说一下,:使用HDFS的balancer命令,
可以配置一个Threshold来平衡每一个DataNode磁盘利用率。例如设置了Threshold为10%,那么执行balancer命令的时候,
首先统计所有DataNode的磁盘利用率的均值,然后判断如果某一个DataNode的磁盘利用率超过这个均值Threshold以上,那么将会把这个DataNode的block转移到磁盘利用率低的DataNode,这对于新节点的加入来说十分有用。
4. 数据校验:
采用CRC32作数据交验。在文件Block写入的时候除了写入数据还会写入交验信息,在读取的时候需要交验后再读入。
5. NameNode是单点
如果失败的话,任务处理信息将会记录在本地文件系统和远端的文件系统中。
6. 数据管道性的写入
当客户端要写入文件到DataNode上,首先客户端读取一个Block然后写到第一个DataNode上,然后由第一个DataNode传递到备份的DataNode上,一直到所有需要写入这个Block的DataNode都成功写入,客户端才会继续开始写下一个Block。
7. 安全模式
安全模式主要是为了系统启动的时候检查各个DataNode上数据块的有效性,同时根据策略必要的复制或者删除部分数据块。
在分布式文件系统启动的时候,开始的时候会有安全模式,当分布式文件系统处于安全模式的情况下,文件系统中的内容不允许修改也不允许删除,
直到安全模式结束。运行期通过命令也可以进入安全模式。在实践过程中,系统启动的时候去修改和删除文件也会有安全模式不允许修改的出错提示,只需要等待一会儿即可。
2.5 说说MapReduce
MapReduce从它名字上来看就大致可以看出个缘由,两个动词Map和Reduce,“Map(展开)”就是将一个任务分解成为多个任务,“Reduce”就是将分解后多任务处理的结果汇总起来,得出最后的分析结果。
具体过程序如下:
1) Input输入
从文件中读取原始数据
原始数据 <InputKey, InputValue>
2) Map映射
将原始数据映射成用于Reduce的数据
<InputKey, InputValue> List<<MapKey, MapValue>>
3) Reduce合并
将相同Key值的中间数据合并成最终数据
<MapKey, List<MapValue>> <OutputKey, OutputValue>
4) Output输出
将最终处理结果输出到文件
<OutputKey, OutputValue> 结果文件
上述就是MapReduce大致处理过程,在Map前还可能会对输入的数据有Split(分割)的过程,保证任务并行效率,在Map之后还会有Shuffle(混合)的过程,对于提高Reduce的效率以及减小数据传输的压力有很大的帮助。后面会具体提及这些部分的细节。
再来看看hadoop下的MapReduce
最简单的 MapReduce 应用程序至少包含 3 个部分:一个 Map 函数、一个 Reduce函数和一个 main 函数。main 函数将作业控制和文件输入/输出结合起来。在这点上,Hadoop 提供了大量的接口和抽象类,从而为 Hadoop 应用程序开发人员提供许多工具,可用于调试和性能度量等。
MapReduce 本身就是用于并行处理大数据集的软件框架。
MapReduce 的根源是函数性编程中的 map 和 reduce 函数。它由两个可能包含有许多实例(许多 Map 和Reduce)的操作组成。Map 函数接受一组数据并将其转换为一个键/值对列表,输入域中的每个元素对应一个键/值对。Reduce 函数接受 Map 函数生成的列表,然后根据它们的键(为每个键生成一个键/值对)缩小键/值对列表。
2.6 hadoop结构示意图

MapReduce从它名字上在Hadoop的系统中,会有一台Master,主要负责NameNode的工作以及JobTracker的工作。
JobTracker的主要职责就是启动、跟踪和调度各个Slave的任务执行。还会有多台Slave,每一台Slave通常具有DataNode的功能并负责TaskTracker的工作。TaskTracker根据应用要求来结合本地数据执行Map任务以及Reduce任务。
第3章 FSShell 命令指南
3.1 FSShell 命令指南
调用文件系统(FS)Shell 命令应使用 bin/hadoop fs<args>的形式。所有的的 FSshell命令使用 URI 路径作为参数。URI 格式是 scheme://authority/path。对 HDFS 文件系统,scheme 是 hdfs,对本地文件系统,scheme 是 file。其中 scheme 和 authority 参数都是可选的,如果未加指定,就会使用配置中指定的默认 scheme。一个 HDFS 文件或目录比如/parent/child可以表示成 hdfs://namenode:namenodeport/parent/child,或者更简单的/parent/child(假设你配置文件中的默认值是 namenode:namenodeport)。大多数 FSShell命令的行为和对应的 UnixShell 命令类似,不同之处会在下面介绍各命令使用详情时指出。
出错信息会输出到 stderr,其他信息输出到 stdout。
1) cat
使用方法:hadoop fs -catURI[URI...]
将路径指定文件的内容输出到 stdout。
示例:
hadoop fs-cat hdfs://host1:port1/file1hdfs://host2:port2/file2
hadoop fs-cat file:///file3/user/hadoop/file4
返回值:
成功返回 0,失败返回-1。
2) copyFromLocal
使用方法:hadoop fs -copyFromLocal<localsrc>URI 除了限定源路径是一个本地文件外,和 put 命令相似。
3) copyToLocal
使用方法:hadoop fs -copyToLocal[-ignorecrc][-crc]URI<localdst>
除了限定目标路径是一个本地文件外,和 get 命令类似。
4) cp
使用方法:hadoopfs-cpURI[URI...]<dest>
将文件从源路径复制到目标路径。这个 Hadoop Shell 命令允许有多个源路径,此时目标路径必须是一个目录。
示例:
Hadoopfs –cp /user/hadoop/file1/user/hadoop/file2
hadoopfs –cp /user/hadoop/file1/user/hadoop/file2/user/hadoop/dir
返回值:
成功返回 0,失败返回-1。
5) du
使用方法:hadoop fs –du URI[URI...]
此 Hadoop Shell 命令显示目录中所有文件的大小,或者当只指定一个文件时,显示此文件的大小。
示例:
Hadoop fs –du
/user/hadoop/dir1/user/hadoop/file1hdfs://host:port/user/hadoop/dir1
返回值:
成功返回 0,失败返回-1。
6) dus
使用方法:hadoop fs -dus<args>
显示文件的大小。
7) expunge
使用方法:hadoop fs -expunge
清空回收站。请参考 HDFS 设计文档以获取更多关于回收站特性的信息。
8) get
使用方法:hadoop fs -get[-ignorecrc][-crc]<src><localdst>
复制文件到本地文件系统。可用-ignorecrc 选项复制 CRC 校验失败的文件。使用-crc 选项
复制文件以及 CRC 信息。
示例:
hadoop fs –get /user/hadoop/filelocalfile
hadoop fs –get hdfs://host:port/user/hadoop/filelocalfile
返回值:
成功返回 0,失败返回-1。Hadoop Shell 命令还有很多,这里只介绍了其中的一部分。
第4章 eclipse测试hadoop
4.1 配置eclipse
下载插件hadoop-1.03,拷贝到eclipse插件目录
启动hadoop

然后运行jps,看是否服务都已经启动
启动eclipse
配置hadoop,选择window->preferences->Hadoop Map/Reduce,选择hadoop安装路径

编辑map/reduce location

然后新建map/reduce工程

新建类
PutMerge.java
public
class
PutMerge {
/**
* @throws IOException
* @Title: main
* @Description: 测试逐一读取inputFiles中的文件,并写入目标HDFS文件
* @param args
* 设定文件
* @return void 返回类型
* @throws
*/
public
static
void
main(String[] args)
throws
IOException {
Configuration conf =
new
Configuration();
FileSystem local = FileSystem.getLocal(conf);
/** 设定文件的输入输出目录 */
Path inputDir =
new
Path(args[
0
]);
Path hdfsFile =
new
Path(args[
1
]);
// 伪分布式下这样处理
FileSystem hdfs = hdfsFile.getFileSystem(conf);
// 正常分布式
// FileSystem hdfs = FileSystem.get(conf);
try
{
FileStatus[] inputFiles = local.listStatus(inputDir);
FSDataOutputStream out = hdfs.create(hdfsFile);
for
(
int
i =
0
; i < inputFiles.length; i++) {
System.out.println(inputFiles[i].getPath().getName());
FSDataInputStream in = local.open(inputFiles[i].getPath());
byte
buffer[] =
new
byte
[
256
];
int
bytesRead =
0
;
while
((bytesRead = in.read(buffer)) >
0
) {
out.write(buffer,
0
, bytesRead);
}
in.close();
}
out.close();
}
catch
(IOException e) {
e.printStackTrace();
}
}
}
|
在本地创建input文件夹,创建file01,file02文件
配置java application,加入参数

加入本地路径和服务器上的路径
然后运行程序,得到输出结果
file02
file01
使用命令查看
bin/hadoop fs -ls /user
查看文件上传情况