RDD算子分为两类:Transformation和Action,如下图,记住这张图,走遍天下都不怕。

Transformation:将一个RDD通过一种规则映射为另外一个RDD。
Action:返回结果或保存结果。
注意:只有action才触发程序的执行,transformation不触发执行。
RDD的操作种类有多个,分为: 单指RDD操作、Key/Value RDD操作、多个RDD联合操作,其他操作。
单值RDD
1. Map
map (f: T => U) : RDD[U] ,其中f定义了类型为T的元素到类型为U
的元素的映射,RDD[T] => RDD[U]的变换
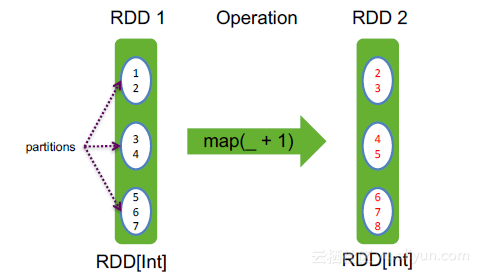
举例:
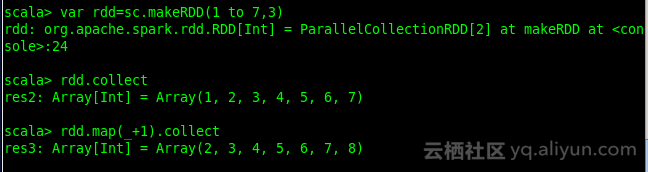
var rdd=sc.makeRDD(1 to 7,3)
简写为 rdd.map(_+1) //rdd.map(x=>x+1)
2. collect
collect(): Array[T],T是RDD中元素类型,将RDD转化为数组。
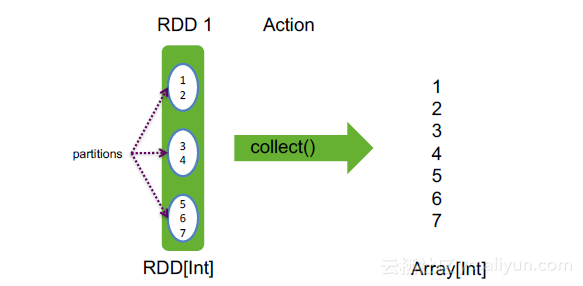
举例:
val rdd = sc.makeRDD(1 to 7, 3)
rdd.collect()
注意:此算子非常危险,他会将所有RDD中的数据汇总到Drive端的JVM内存中,对Drive端压力很大。
3. take
take(num: Int): Array[T] ,其中k是整数,T是RDD中元素类型,返回RDD中前k个元素,并保存成数组
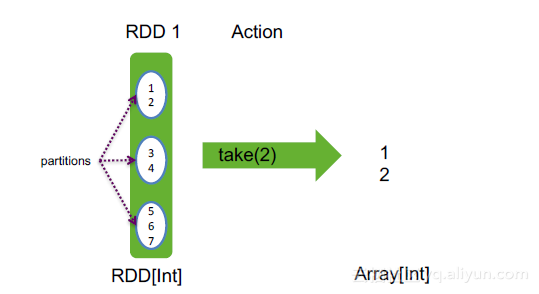
举例:
val rdd = sc.makeRDD(1 to 7, 3)
rdd.take(2)

4. glom
glom() : RDD[Array[T]],将RDD中每个partition中元素转换为数组
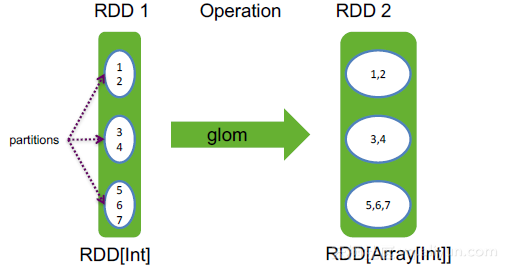
举例:
val rdd = sc.makeRDD(1 to 7, 3)
rdd.glom.collect
![]()
5. coalesce
coalesce(numPartitions: Int) : RDD[T],将RDD中的partition个数合并为numPartitions个
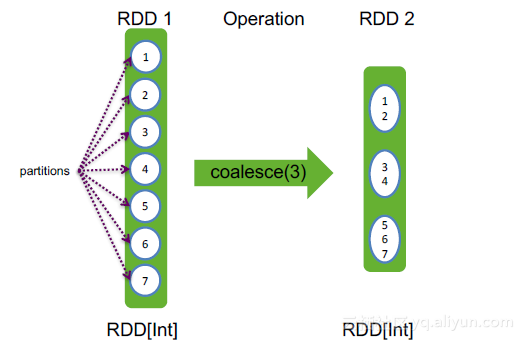
举例:
val rdd = sc.makeRDD(1 to 7,7)
rdd.coalesce(3) // 生成新的RDD,它包含三个Partition
6. repartition
repartition(numPartitions: Int) :RDD[T],将RDD中的partition个数均匀合并为numPartitions个
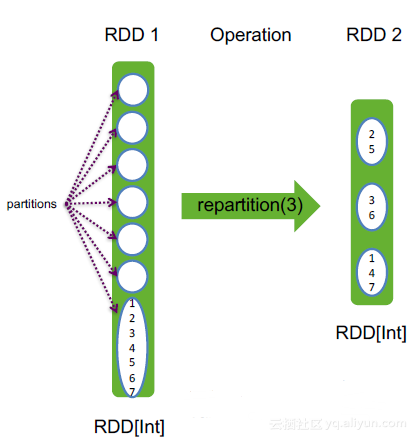
举例:
val list = Seq(Seq(),Seq(),Seq(),Seq(),Seq(),Seq(),
Seq(1,2,3,4,5,6,7))
val rdd = sc.makeRDD(list, 7).flatMap(x => x)
rdd.repartition(3) // 生成新的RDD,它包含三个Partition
7. filter
filter(f: T => Boolean):
RDD[T] ,其中f定义了类型为T的元素是否留下,过滤输入RDD中的元素,将f返回true的元素留下
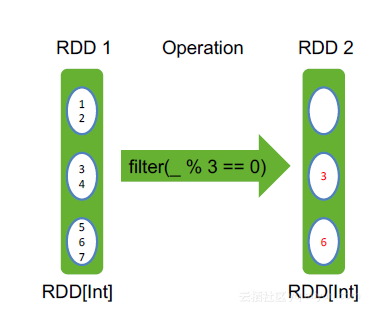
举例:
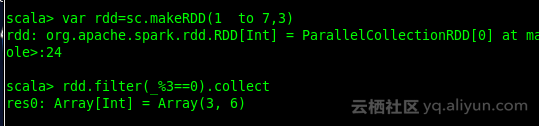
var rdd=sc.makeRDD(1 to 7,7)
rdd.filter(_%3==0)
8. count
count(): Long,统计RDD中元素个数,并返回Long类型
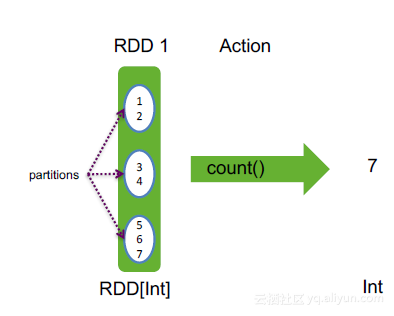
val rdd = sc.makeRDD(1 to 7, 3)
rdd.count() // 统计RDD中元素总数
9. flatMap
flatMap(f: T =>TraversableOnce[U]): RDD[U],将函数f作用在RDD中每个元素上,并展开(flatten)
输出的每个结果, flatMap = flatten + map,先映射(map),再拍扁(flatten )
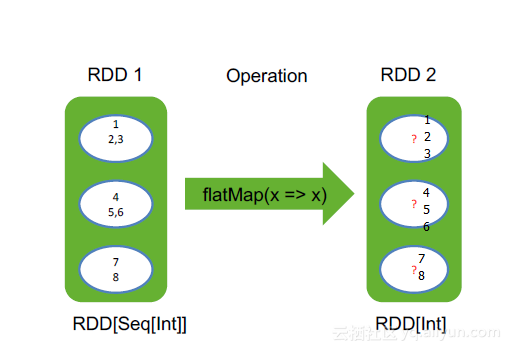
举例:
val rdd = sc.makeRDD(1 to 3, 3)
rdd.flatMap( x => 1 to x) // 将x映射成1~x
10. reduce
reduce(f: (T, T) => T): T, 按照函数f对RDD中元素,进行规约
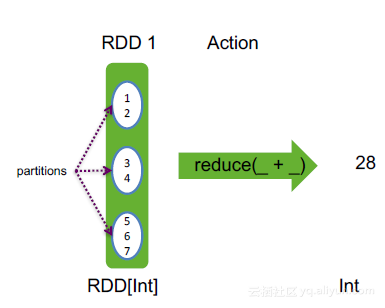
举例:
val rdd = sc.makeRDD(1 to 7, 3)
rdd.reduce((x, y) => x + y)
简写为:rdd.reduce(_ + _)

11. foreach
foreach(f: T => Unit):Unit,对RDD中每个元素,调用函数f
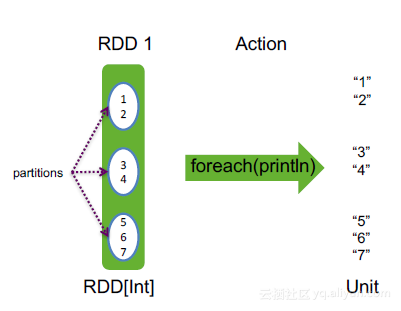
举例:
val rdd = sc.makeRDD(1 to 7, 3)
rdd.foreach( x => println(x))
简写为:rdd.foreach(println)
Key/Value RDD
首先先来看下如何创建一个Key/Value的rdd
var seq=Seq((A,1),(B,1),(C,1))
var rdd=sc.makeRDD(seq)
1. mapValues
对vaule做map操作
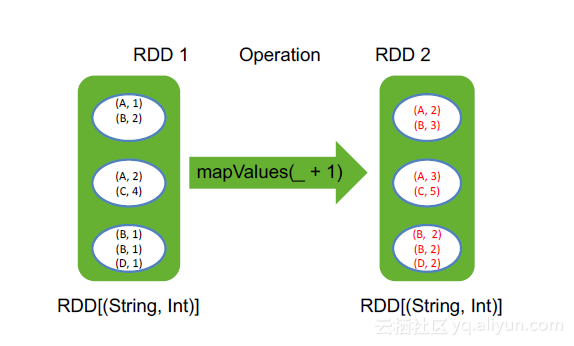
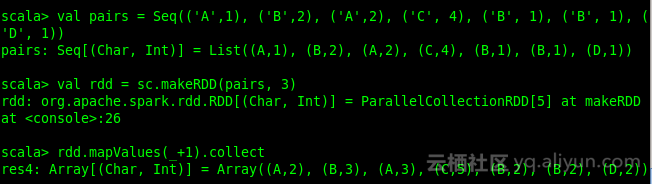
举例:
val pairs = Seq((A,1), (B,2), (A,2), (C, 4), (B, 1), (B, 1), (D, 1))
val rdd = sc.makeRDD(pairs, 3)
rdd.mapValues(_ + 1)
2. reduceByKey
对Key相同的value做计算
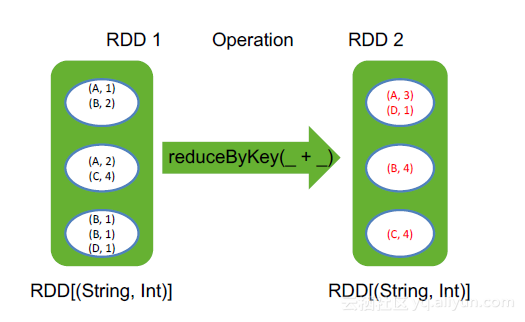
举例:
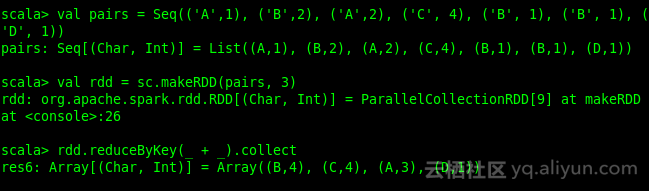
val pairs = Seq(('A',1), ('B',2), ('A',2), ('C', 4), ('B', 1), ('B', 1), ('D', 1))
val rdd = sc.makeRDD(pairs, 3)
rdd.reduceByKey(_ + _)
3. groupByKey
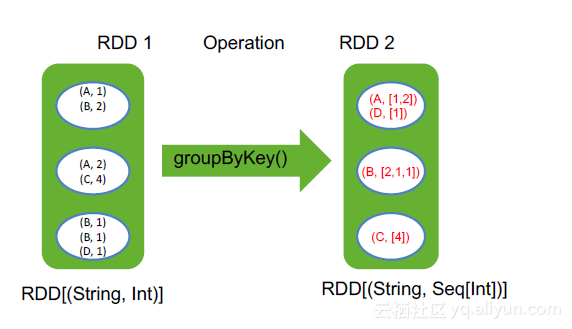
将RDD[key,value] 按照相同的key进行分组,形成RDD[key,Iterable[value]]的形式, 有点类似于sql中的groupby
举例:
val pairs = Seq((A,1), (B,2), (A,2), (C, 4), (B, 1), (B, 1), (D, 1))
val rdd = sc.makeRDD(pairs, 3)
rdd.groupByKey()
注意:能用reducebykey代替就不用groupbykey,groupbykey会将所有的元素进行聚合,消耗大量内存。
多RDD
1. union
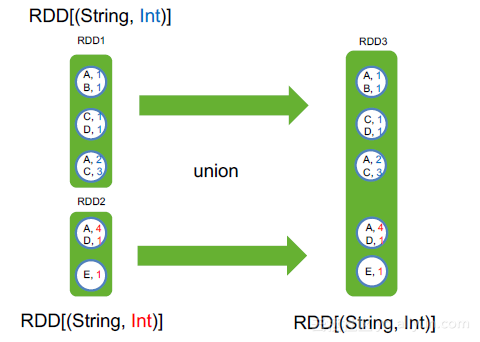
将多个RDD合并为一个RDD
举例:
val pairs1 = Seq((A,1), (B,1), (C,1), (D, 1), (A, 2), (C, 3))
val rdd1 = sc.makeRDD(pairs1, 3)
val pairs2 = Seq((A,4), (D,1), (E, 1))
val rdd2 = sc.makeRDD(pairs2, 2)
rdd1.union(rdd2)
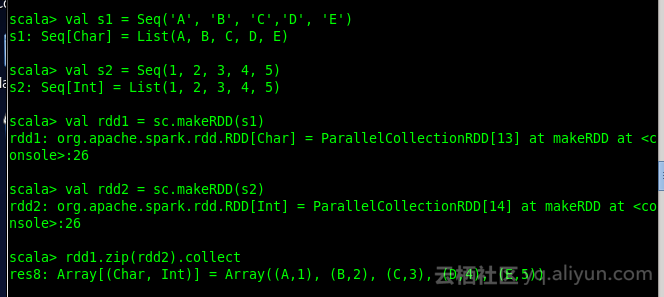
2. zip
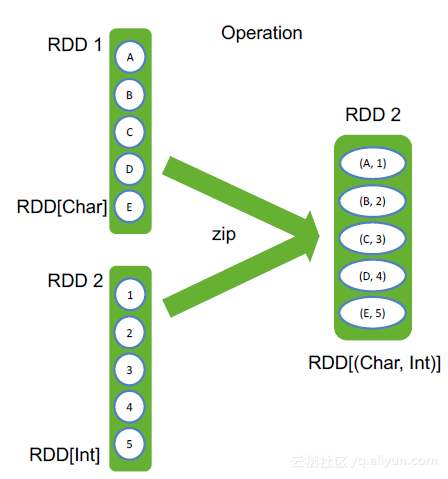
zip函数用于将两个RDD组合成Key/Value形式的RDD,如果两个rdd中的partition数量不一致,会报错。
举例:
val s1 = Seq(A, B, C, D, E)
val rdd1 = sc.makeRDD(s1)
val s2 = Seq(1, 2, 3, 4, 5)
val rdd2 = sc.makeRDD(s2)
rdd1.zip(rdd2)
3. join
join相当于SQL中的内关联join,只返回两个RDD根据K可以关联上的结果,join只能用于两个RDD之间的关联,
如果要多个RDD关联,多关联几次即可
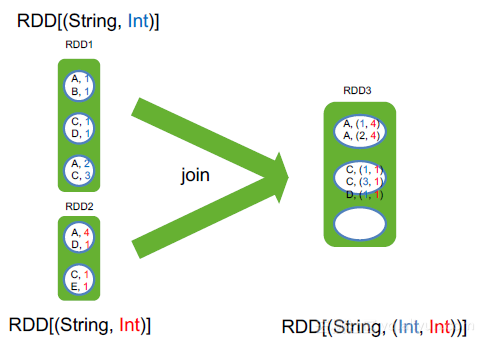
举例:
val pairs1 = Seq((A,1), (B,1), (C,1), (D, 1), (A, 2), (C, 3))
val rdd1 = sc.makeRDD(pairs1, 3)
val pairs2 = Seq((A,4), (D,1), (C,1), (E, 1))
val rdd2 = sc.makeRDD(pairs2, 2)
rdd1.join(rdd2)
还有些是是其他rdd操作符,这里就不讲解了,上述所写如有不对之处,还请各位前辈赐教。




