想说的是,当学了Hadoop一段时间之后,很有必要去官网上去下载源代码来进行学习。如hadoop-***.src.tar.gz。
**************************学习**************************
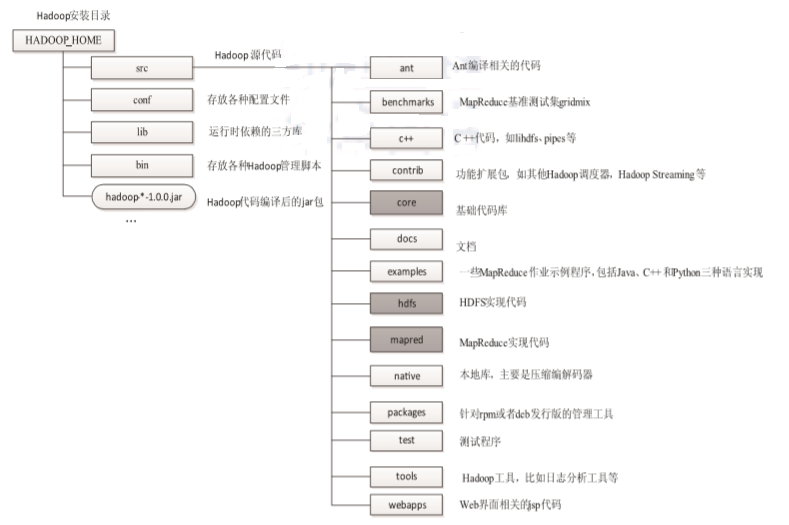
直接解压 Hadoop 压缩包后,可看到下图所示的目录结构,其中,比较重要的目录有 src、conf、lib、bin等。
下面分别介绍这几个目录的作用:
src :Hadoop 源代码所在的目录。最核心的代码所在子目录分别是 core、hdfs 和mapred,它们分别实现了 Hadoop 最重要的三个模块,即基础公共库、HDFS 实现和 MapReduce 实现。
conf:配置文件所在目录。Hadoop 的配置文件比较多,其设计原则可概括为如下两点。
1 尽可能模块化,即每个重要模块拥有自己的配置文件,这样使得维护以及管理变得简单。
2 动静分离,即将可动态加载的配置选项剥离出来,组成独立配置文件。比如, Hadoop 1.0.0 版本之前,作业队列权限管理相关的配置选项被放在配置文件 mapred- site.xml 中,而该文件是不可以动态加载的,每次修改后必须重启 MapReduce。但 从 1.0.0 版本开始,这些配置选项被剥离放到独立配置文件 mapred-queue-acls.xml 中,该文件可以通过 Hadoop 命令行动态加载。conf 目录下最重要的配置文件有 core-site.xml、hdfs-site.xml 和 mapred- site.xml,分别设置了基础公共库 core、分布式文件系统 HDFS 和分布式计算框架 MapReduce 的配置选项。
lib:Hadoop 运行时依赖的三方库,包括编译好的 jar 包以及其他语言生成的动态库。 Hadoop 启动或者用户提交作业时,会自动加载这些库。
bin:运行以及管理 Hadoop 集群相关的脚本。这里介绍几个常用的脚本。
1 hadoop:最基本且功能最完备的管理脚本,其他大部分脚本都会调用该脚本。
2 start-all.sh/stop-all.sh:启动 / 停止所有节点上的 HDFS 和 MapReduce 相关服务。
3 start-mapred.sh/stop-mapred.sh:单独启动 / 停止 MapReduce 相关服务。
4 start-dfs.sh/stop-dfs.sh:单独启动 / 停止 HDFS 相关服务。
下面就 Hadoop MapReduce 源代码组织结构进 行介绍。Hadoop MapReduce 源代码组织结构如下图所示。

总体上看,Hadoop MapReduce 分为两部分:一部分是 org.apache.hadoop.mapred.*,这 里面主要包含旧的对外编程接口以及 MapReduce 各个服务(JobTracker 以及 TaskTracker) 的实现 ;另一部分是 org.apache.hadoop.mapreduce.*,主要内容涉及新版本的对外编程接口 以及一些新特性(比如 MapReduce 安全)。
1. MapReduce 编程模型相关
org.apache.hadoop.mapred.lib.* :这一系列 Java 包提供了各种可直接在应用程序中使用的 InputFormat、Mapper、Partitioner、Reducer 和 OuputFormat,以减少用户编写 MapReduce 程序的工作量。
org.apache.hadoop.mapred.jobcontrol :该 Java 包允许用户管理具有相互依赖关系的作业(DAG 作业)。
org.apache.hadoop.mapred.join :该 Java 包实现了 map-side join 算法。该算法要求 数据已经按照 key 排好序,且分好片,这样可以只使用 Map Task 实现 join 算法,避 免 re-partition、sort、shuffling 等开销。
org.apache.hadoop.mapred.pipes:该 Java 包允许用户用 C/C++ 编写 MapReduce 作业。
org.apache.hadoop.mapreduce:该 Java 包定义了一套新版本的编程接口,这套接口比 旧版接口封装性更好。
org.apache.hadoop.mapreduce.* :这一系列Java包根据新版接口实现了各种InputFormat、Mapper、Partitioner、Reducer 和 OuputFormat。
2. MapReduce 计算框架相关
org.apache.hadoop.mapred:Hadoop MapReduce 最核心的实现代码,包括各个服务的具体实现。
org.apache.hadoop.mapred.filecache:Hadoop DistributedCache 实现。
DistributedCache是 Hadoop 提供的数据分发工具,可将用户应用程序中需要的文件分发到各个节 点上。
org.apache.hadoop.mapred.tools :管理控制 Hadoop MapReduce,当前功能仅包括允许用户动态更新服务级别的授权策略和 ACL(访问权限控制)属性。 org.apache.hadoop.mapreduce.split :该 Java 包的主要功能是根据作业的 InputFormat生成相应的输入 split。
org.apache.hadoop.mapreduce.server.jobtracker :该 Java 包维护了 JobTracker 可看到的 TaskTracker 状态信息和资源使用情况。
org.apache.hadoop.mapreduce.server.tasktracker.*:TaskTracker 的一些辅助类。
3. MapReduce 安全机制相关
这里只涉及 org.apache.hadoop.mapreduce.security.*。这一系列 Java 包实现了 MapReduce 安全机制。
本文转自大数据躺过的坑博客园博客,原文链接:http://www.cnblogs.com/zlslch/p/5065053.html,如需转载请自行联系原作者





