我们已经知道了Hadoop的三大核心模块:HDFS、MapReduce、Yarn。
MapReduce是什么?
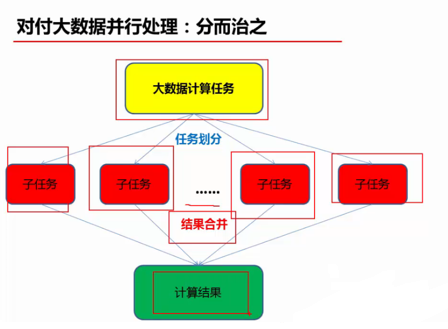
MapReduce是一种编程模型,用于大规模数据集的并行计算,其主要思想就是Map(映射)和Reduce(化简)。
MapReduce的创意和灵感来源于函数式编程,在函数式编程中,map对列表的每个元素执行操作或函数。例如:列表[1,2,3,4]上执行 multiple-by-two 函数会产生另一个列表[2,4,6,8],执行时,原列表不被改变。函数式编程认为,应当保持数据不可变,避免在多个进程或线程间共享数据。这意味着,这个函数虽然简单,但可以通过两个或更多线程在同一列表上同时执行,线程间互不影响,因为列表本身未被改变。
MapReduce是用来进行海量数据的并行计算的,需要将工作分配到大量的机器上去做,如果组件间可共享数据,那么数据节点间的数据同步会使系统变得低效且不可靠。实际上,MapReduce上的数据元素是不可变的,即便改变也不会反馈到输入文件,节点间通信只在新的键值对输出时发生,Hadoop会把输出键值对传到下一个阶段。
从概念上讲,MapReduce程序将输入数据列表转变成输出数据列表。一个MapReduce程序会执行两次数据转换操作,一次map,一次reduce。还是举个例子吧:








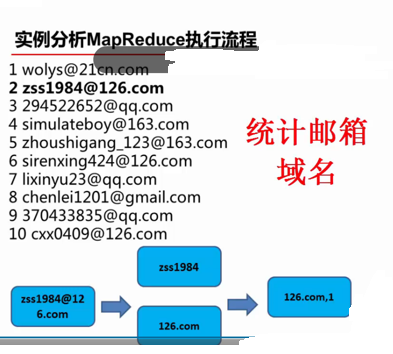



***********************数据来源******************************
1 wolys@21cn.com 2 zss1984@126.com 3 294522652@qq.com 4 simulateboy@163.com 5 zhoushigang_123@163.com 6 sirenxing424@126.com 7 lixinyu23@qq.com 8 chenlei1201@gmail.com 9 370433835@qq.com 10 cxx0409@126.com 11 viv093@sina.com 12 q62148830@163.com 13 65993266@qq.com 14 summeredison@sohu.com 15 zhangbao-autumn@163.com 16 diduo_007@yahoo.com.cn 17 fxh852@163.com 18 weiyang1128@163.com 19 licaijun007@163.com 20 junhongshouji@126.com 21 wuxiaohong11111@163.com 22 fennal@sina.com 23 li_dao888@163.com 24 bokil.xu@163.com 25 362212053@qq.com 26 youloveyingying@yahoo.cn 27 boiny@126.com 28 linlixian200606@126.com 29 alex126126@126.com 30 654468252@qq.com 31 huangdaqiao@yahoo.com.cn 32 kitty12502@163.com 33 xl200811@sohu.com 34 ysjd8@163.com 35 851627938@qq.com 36 wubo_1225@163.com 37 kangtezc@163.com 38 xiao2018@126.com 39 121641873@qq.com 40 296489419@qq.com 41 beibeilong012@126.com
第一步:map。读取输入文件内容,解析成key、value对。对输入文件的每一行,解析成key、value对。通过‘@’对value解析出邮箱域。即邮箱账号的@符号后面部分
<21cn.com 1> <126.com 1> <qq.com 1> <163.com 1> <163.com 1> <126.com 1> <qq.com 1> <gmail.com 1> ..........
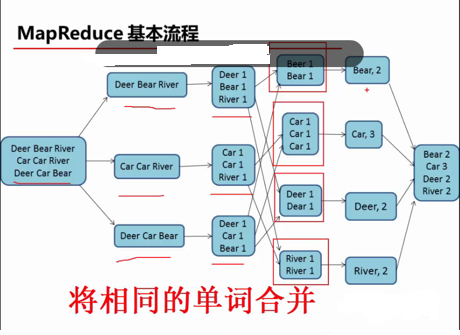
第二步:combine。对相同的邮箱域合并。
<163.com 1 1 1 1 1 1 1 1 1 1 1 1 1 1> <126.com 1 1 1 1 1 1 1 1 1> <qq.com 1 1 1 1 1 1 1 1 1> <sina.com 1 1> <sohu.com 1 1> <yahoo.com.cn 1 1> <21cn.com 1> <gmail.com 1> <yahoo.cn 1>
第三步:reduce。对相同的邮箱域统计求和。
<163.com 14> <126.com 9> <qq.com 9> <sina.com 2> <sohu.com 2> <yahoo.com.cn 2> <21cn.com 1> <gmail.com 1> <yahoo.cn 1>
好了,我们想要的结果出来了。MapReduce的思想从根源上讲也就是如此,是不是很简单呀?
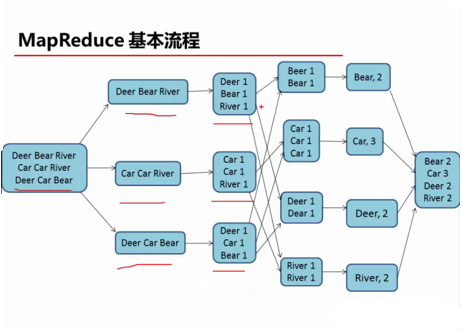
MapReduce的基本流程
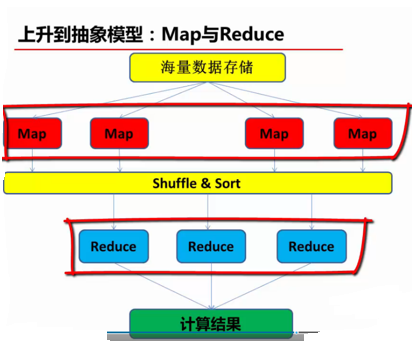
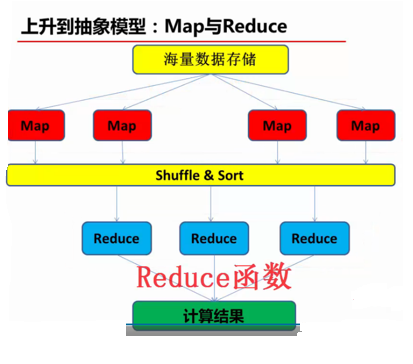
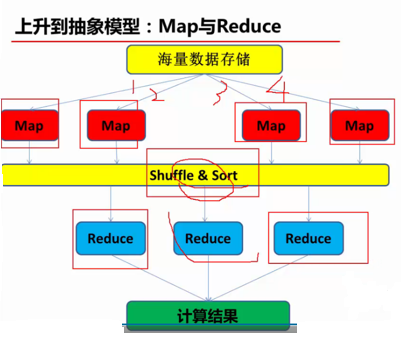
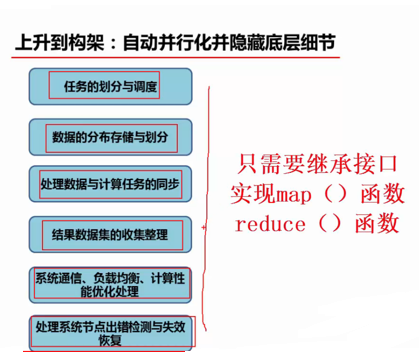
MapReduce计算模型由两个阶段组成:Map和Reduce,用户只需要实现map()和reduce()两个函数,即可实现分布式计算,非常简单。
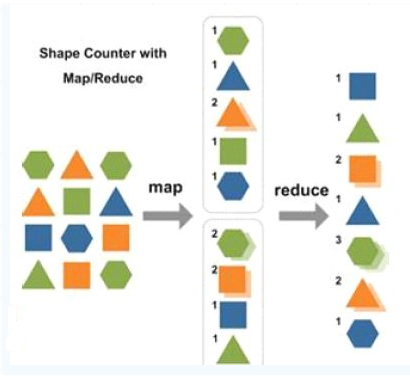
图1 统计图形样式个数的map和reduce过程示意图
map()和reduce()这两个函数的形参是key、value对,表示函数的输入信息。
1. map任务处理
1.1 读取输入文件内容,解析成key、value对。对输入文件的每一行,解析成key、value对。每一个键值对调用一次map函数。
1.2 写自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
1.3 对输出的key、value进行分区。
1.4 对不同分区的数据,按照key进行排序、分组。相同key的value放到一个集合中。
1.5 (可选)分组后的数据进行归约。
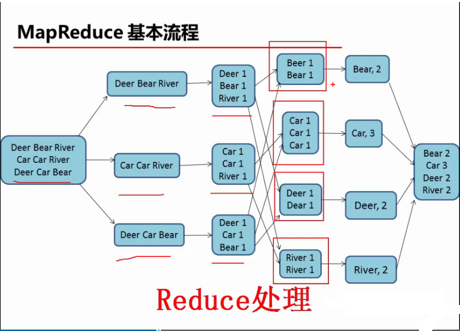
2.reduce任务处理
2.1 对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点。
2.2 对多个map任务的输出进行合并、排序。写reduce函数自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
2.3 把reduce的输出保存到文件中。

图2 word count的map和reduce过程示意图
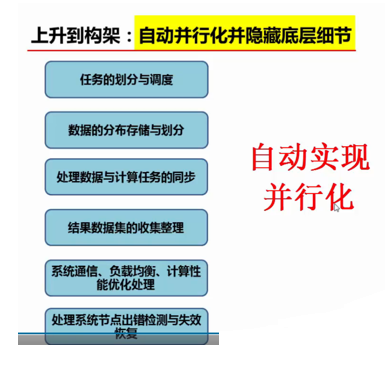
MapReduce的基本设计思想
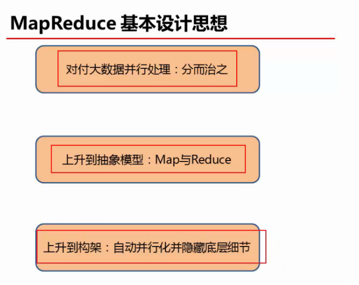
上面说了这么多,其实MapReduce的设计思想可以归结为如下三个:
(1)对付大数据并行处理:分而治之
(2)上升到抽象模型:Map与Reduce
(3)上升到构架:以统一构架为程序员隐藏系统层细节
*******************扩展*********************
同学:博主,怎么给萌妹子解释MapReduce呢?
小讲:那就先来看看印度Java程序员Shekhar Gulati怎样向妻子解释MapReduce的吧 (来源:CSDN)
我: 你是如何准备洋葱辣椒酱的?
妻子: 我会取一个洋葱,把它切碎,然后拌入盐和水,最后放进混合研磨机里研磨。这样就能得到洋葱辣椒酱了。但这和MapReduce有什么关系?
我: 你等一下。让我来编一个完整的情节,这样你肯定可以在15分钟内弄懂MapReduce.
妻子: 好吧。
我:现在,假设你想用薄荷、洋葱、番茄、辣椒、大蒜弄一瓶混合辣椒酱。你会怎么做呢?
妻子: 我会取薄荷叶一撮,洋葱一个,番茄一个,辣椒一根,大蒜一根,切碎后加入适量的盐和水,再放入混合研磨机里研磨,这样你就可以得到一瓶混合辣椒酱了。
我: 没错,让我们把MapReduce的概念应用到食谱上。Map和Reduce其实是两种操作,我来给你详细讲解下。
Map(映射): 把洋葱、番茄、辣椒和大蒜切碎,是各自作用在这些物体上的一个Map操作。所以你给Map一个洋葱,Map就会把洋葱切碎。 同样的,你把辣椒,大蒜和番茄一一地拿给Map,你也会得到各种碎块。 所以,当你在切像洋葱这样的蔬菜时,你执行就是一个Map操作。 Map操作适用于每一种蔬菜,它会相应地生产出一种或多种碎块,在我们的例子中生产的是蔬菜块。在Map操作中可能会出现有个洋葱坏掉了的情况,你只要把坏洋葱丢了就行了。所以,如果出现坏洋葱了,Map操作就会过滤掉坏洋葱而不会生产出任何的坏洋葱块。
Reduce(化简):在这一阶段,你将各种蔬菜碎都放入研磨机里进行研磨,你就可以得到一瓶辣椒酱了。这意味要制成一瓶辣椒酱,你得研磨所有的原料。因此,研磨机通常将map操作的蔬菜碎聚集在了一起。
妻子: 所以,这就是MapReduce?
我: 你可以说是,也可以说不是。 其实这只是MapReduce的一部分,MapReduce的强大在于分布式计算。
妻子: 分布式计算? 那是什么?请给我解释下吧。
我: 没问题。
假设你参加了一个辣椒酱比赛并且你的食谱赢得了最佳辣椒酱奖。得奖之后,辣椒酱食谱大受欢迎,于是你想要开始出售自制品牌的辣椒酱。假设你每天需要生产10000瓶辣椒酱,你会怎么办呢?
妻子: 我会找一个能为我大量提供原料的供应商。
我:是的……就是那样的。那你能否独自完成制作呢?也就是说,独自将原料都切碎? 仅仅一部研磨机又是否能满足需要?而且现在,我们还需要供应不同种类的辣椒酱,像洋葱辣椒酱、青椒辣椒酱、番茄辣椒酱等等。
妻子: 当然不能了,我会雇佣更多的工人来切蔬菜。我还需要更多的研磨机,这样我就可以更快地生产辣椒酱了。
我:没错,所以现在你就不得不分配工作了,你将需要几个人一起切蔬菜。每个人都要处理满满一袋的蔬菜,而每一个人都相当于在执行一个简单的Map操作。每一个人都将不断的从袋子里拿出蔬菜来,并且每次只对一种蔬菜进行处理,也就是将它们切碎,直到袋子空了为止。
这样,当所有的工人都切完以后,工作台(每个人工作的地方)上就有了洋葱块、番茄块、和蒜蓉等等。
妻子:但是我怎么会制造出不同种类的番茄酱呢?
我:现在你会看到MapReduce遗漏的阶段---搅拌阶段。MapReduce将所有输出的蔬菜碎都搅拌在了一起,这些蔬菜碎都是在以key为基础的 map操作下产生的。搅拌将自动完成,你可以假设key是一种原料的名字,就像洋葱一样。 所以全部的洋葱keys都会搅拌在一起,并转移到研磨洋葱的研磨器里。这样,你就能得到洋葱辣椒酱了。同样地,所有的番茄也会被转移到标记着番茄的研磨器里,并制造出番茄辣椒酱。
本文转自大数据躺过的坑博客园博客,原文链接:http://www.cnblogs.com/zlslch/p/5077646.html,如需转载请自行联系原作者
