Hadoop整合了众多文件系统,它首先提供了一个高层的文件系统抽象类org.apache.hadoop.fs.FileSystem,这个抽象类展示了一个分布式文件系统,并有几个具体实现。
如下表所示。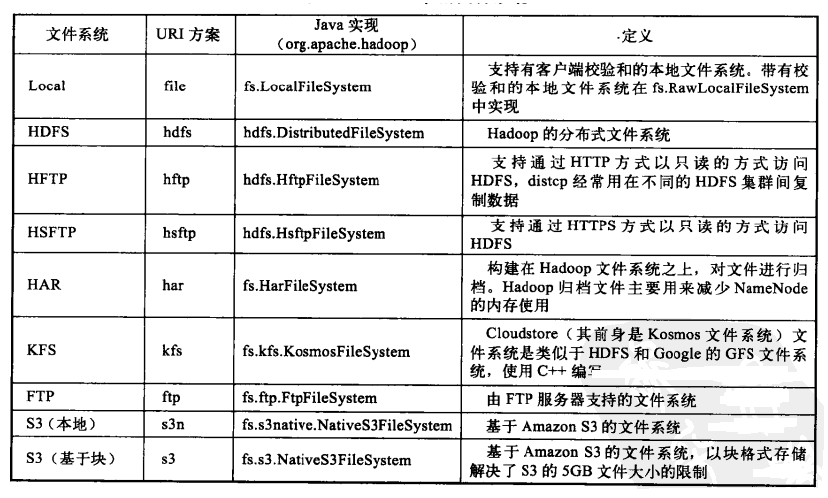
Hadovp提供了许多文件系统的接口,用户可使用URI方案选取合适的文件系统来实现交互。比如,可以使用文件系统命令行接口来进行Hadoop文件系统的操作。如果想列出本地文件系统的目录,那么执行以下shell命令即可:
hadoop fs -ls file:///
(1)接口
Hadoop是使用Java编写的,而Hadoop中不同文件系统之间的交互是由Java API进行调解的。事实上,前面使用的文件系统的shell就是一个Java应用,它使用Java文件系统类来提供文件系统操作。即使其他文件系统比如FTP, S3都有自己的访问工具,这些接口在HDFS中还是被广泛使用,主要用来进行Hadoop文件系统之间的协作。
(2)Thrift
上面提到可以通过Java API与Hadoop的文件系统进行交互,而对于其他非Java应用访问Hadaop文件系统则比较麻烦。Thriftfs分类单元中的Thrift API可通过将Hadaop文件系统展示为一个Apache Thrift服务来填补这个不足,让任何有Thrift绑定的语言都能轻松地与Hadoop文件系统进行交互。Thrift是由Facebook公司开发的一种可伸缩的跨语言服务的发展软件框架。Thrift解决了各系统间大数据量的传输通信,以及系统之间因语言环境不同而需要跨平台的问题。在多种不同的语言之间通信时,Thrift可以作为二进制的高性能的通信中间件,它支持数据(对象)序列化和多种类型
的RPC服务。
下面来看如何使用Thrift API。要使用Thrift API,首先要运行提供Thrill服务的Java服务器,并以代理的方式访问Hadoop文件系统。Thrill API包含很多其他语言生成的stub,包括C++、Perl、PHP、 Python等。Thrift支持不同的版本,因此可以从同一个客户代码中访问不同版本的Hadoop文件系统,但要运行针对不同版本的代理。
(3)C语言库
Hadoop提供了映射Java文件系统接口的C语言库—libhdfs。libhdfs可以编写为一个访问HDFS的C语言库,实际上,它可以访问任意的Haduap文件系统,它也可以使用JNI(Java Native Interface)来调用Java文件系统的客户端。
这里的C语言的接口和Java的使用非常相似,只是稍滞后于Java,目前还不支持一些新特性。相关资料可参见libhdfs/docs/api目录中关丁Hadoop分布的C API文档。
(4) FUSE
FUSE(Filesystem in Userspace)允许将文件系统整合为一个Unix文件系统并在用户空间中执行。通过使用Hadoop Fuse-DFS的contirb模块来支持任意的Hadoop文件系统作为一个标准的文件系统挂载,便可以使用Unix的工具(像1s, cat)和文件系统进行交互,还可以通过任意一种编程语言使用POSIX库来访问文件系统。
Fuse-DFS是用C语言实现的,可使用libhdfs作为与HDFS的接口,关于如何编译和运行Fuse-DFS,可以参见src/contrib../fuse-dfs中的相关文档。
(5) WebDAV
WebDAV是一系列支持编辑和更新文件的HTTP的扩展,在大部分操作系统中,WeDAV共享都可以作为文件系统进行挂载,因此,可通过WebDAV来对外提供HDFS或其他Nadoop文件系统,可以将HDFS作为一个标淮的文件系统进行访问。
(6)其他HDFS接口
HDFS接口还提供了以下其他两种特定的接口。
HTTP。 HDFS定义了一个只读接口,用来在HTTP上检索目录列表和数据。NameNode的嵌入式Web服务器运行在50070端口上,以XML格式提供服务,文件数据由DataNode通过它们的Web服务器50075端日向NameNode提供。这个协议并不拘泥于某个HDFS版本,所以用户可以自己编写使用HTTP从运行不同版本的Hadoop的NDFS中读取数据。HftpFileSystem就是其中的一种实现,它是一个通过HTTP和HDFS交流的Hadoop文件系统,是HTTPS的变体。
FTP。Hadoop接口中还有一个HDFS的FTP接口,它允许使用FTP协议和HDFS交互,即使用FTP客户端和HDFS进行交互。
本文转自大数据躺过的坑博客园博客,原文链接:http://www.cnblogs.com/zlslch/p/5089369.html,如需转载请自行联系原作者