包括:
Eclipse的下载
Eclipse的安装
Eclipse的使用
本地模式或集群模式
Scala IDE for Eclipse的下载、安装和WordCount的初步使用(本地模式和集群模式)
IntelliJ IDEA的下载、安装和WordCount的初步使用(本地模式和集群模式)
我们知道,对于开发而言,IDE是有很多个选择的版本。如我们大部分人经常用的是如下。

现在啊,在业界,用java语言,开发是霸主地位。
比如,一个高级的高手人员,在企业里,做了一个大开发,他走了之后,一般java,还算比较好其余的人,熟悉和做二次开发。
Eclipse的使用


创建Maven工程
这里,其实,可以跳过,参考我的博客
Eclipse下新建Maven项目、自动打依赖jar包
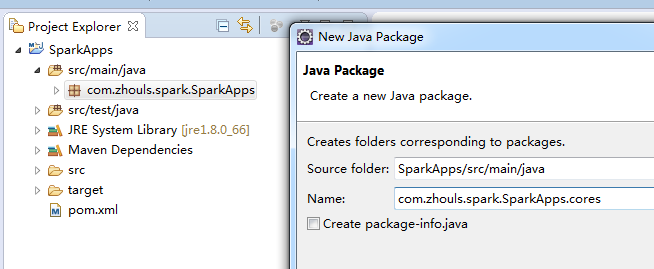
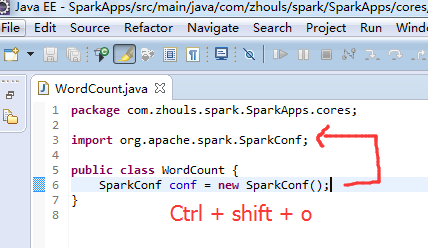
新建包 com.zhouls.spark.SparkApps.cores
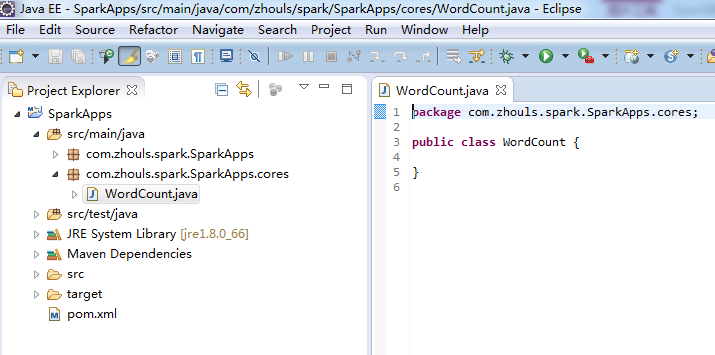
新建WordCount.java
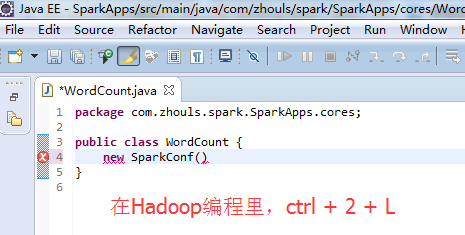
Ctrl + 2 ,再选择 Quick Assist - Assign to local variable Ctrl + 2,L 。
在spark里,貌似不可以,本人目前还没找到原因。
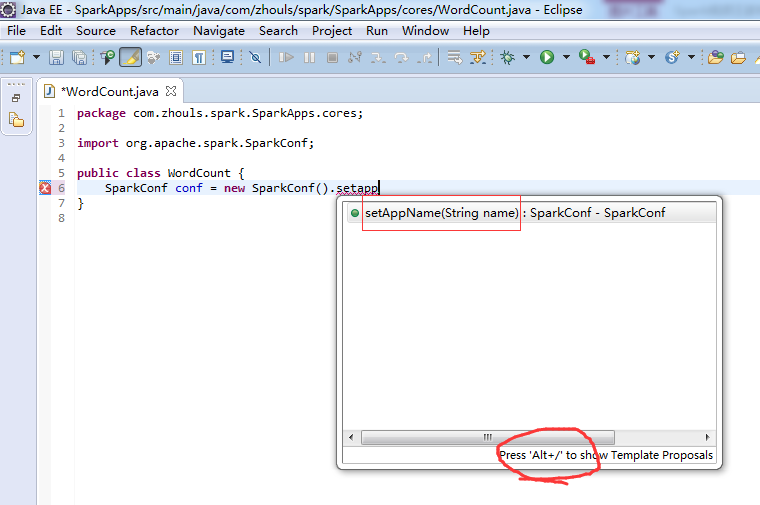
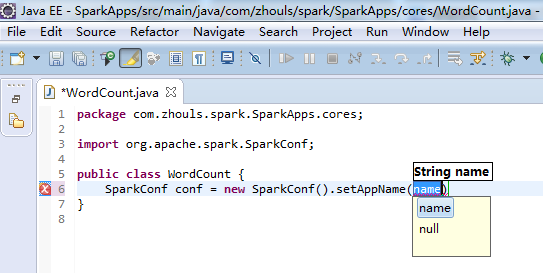
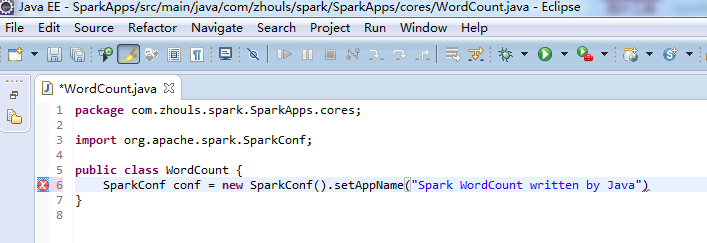
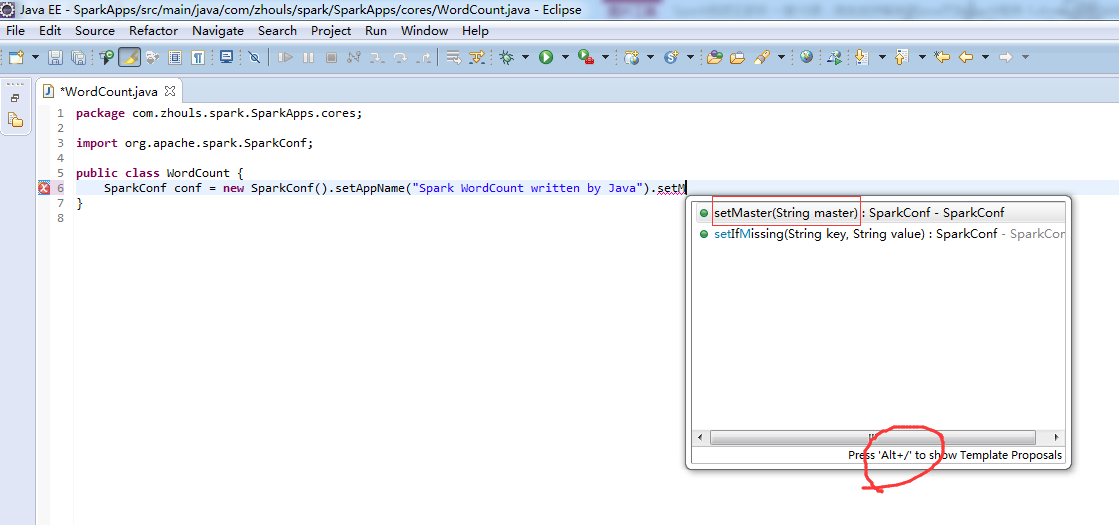
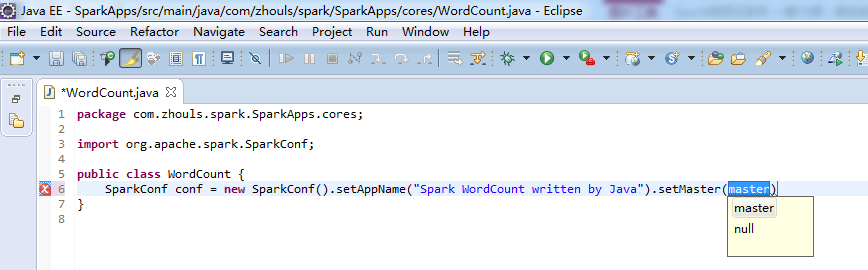
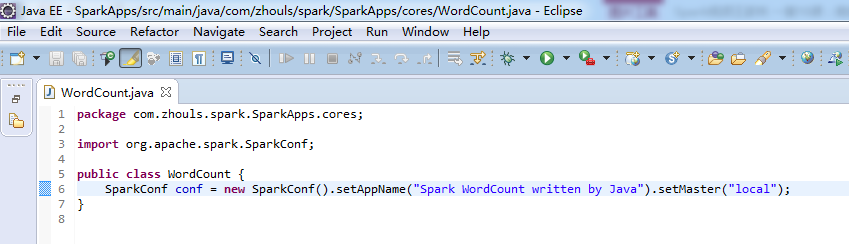
注意,不同语言编写,创建sparkcontext,是不同的。
比如,这里,是java语言,则是
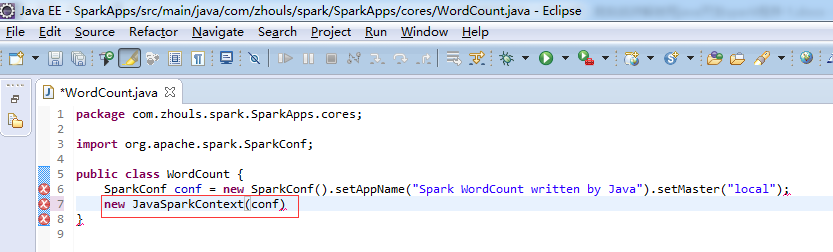
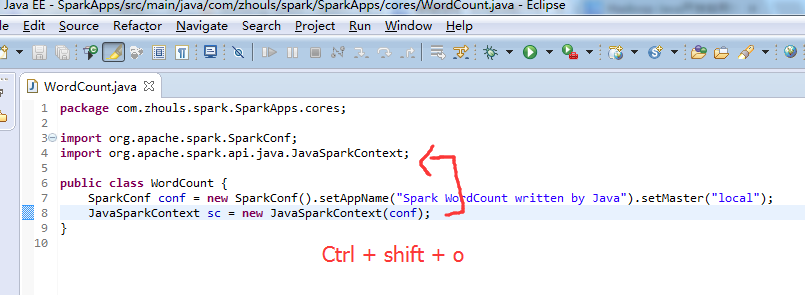
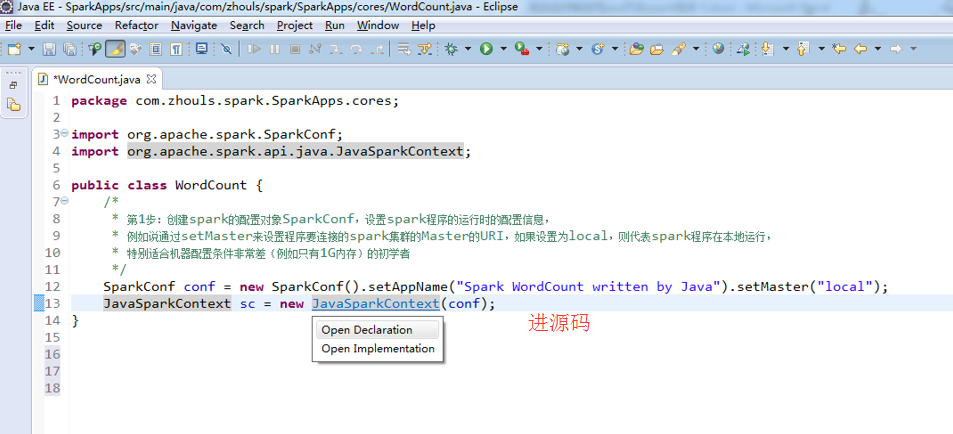



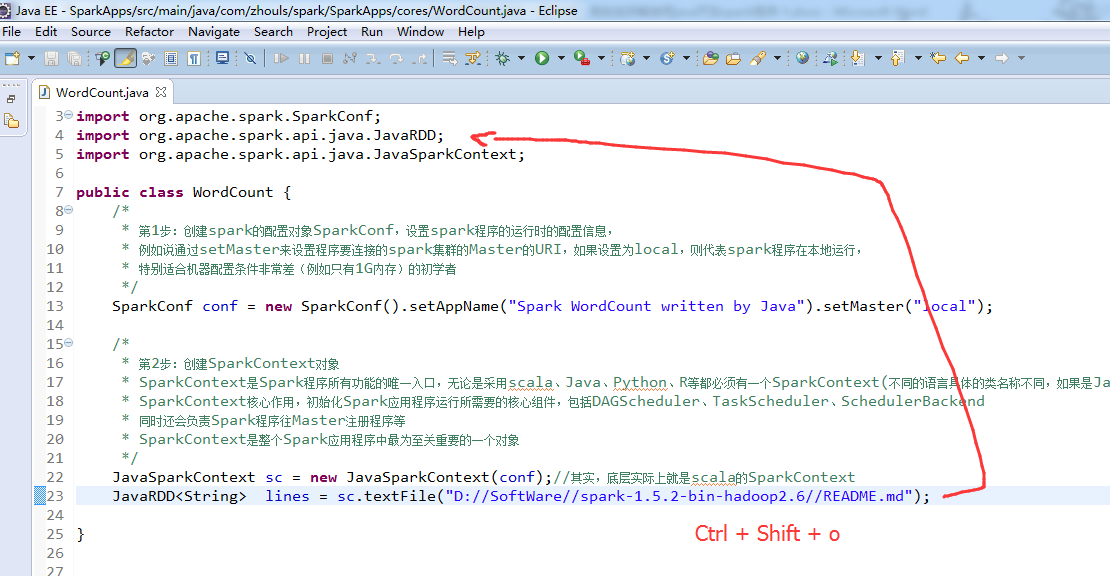
这个,因为是java语言编写的,所以,就没有像scala那样具有自动推导。

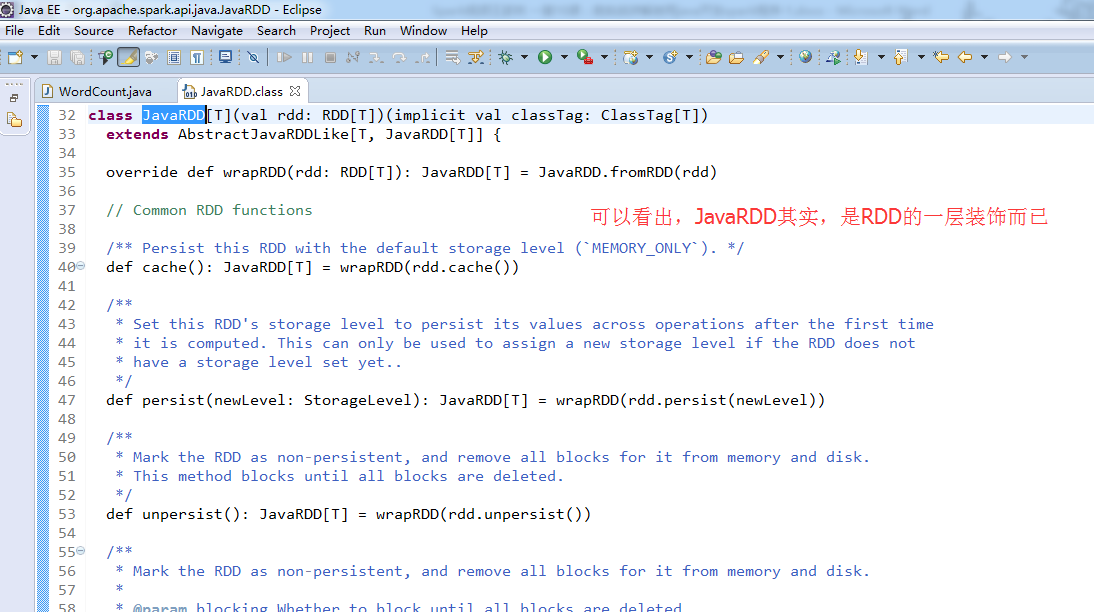
说白了,就是,我们java语言编写,其实就是一层外衣而已。
继续,编程,本地local模式下的用java语言编写的WordCount
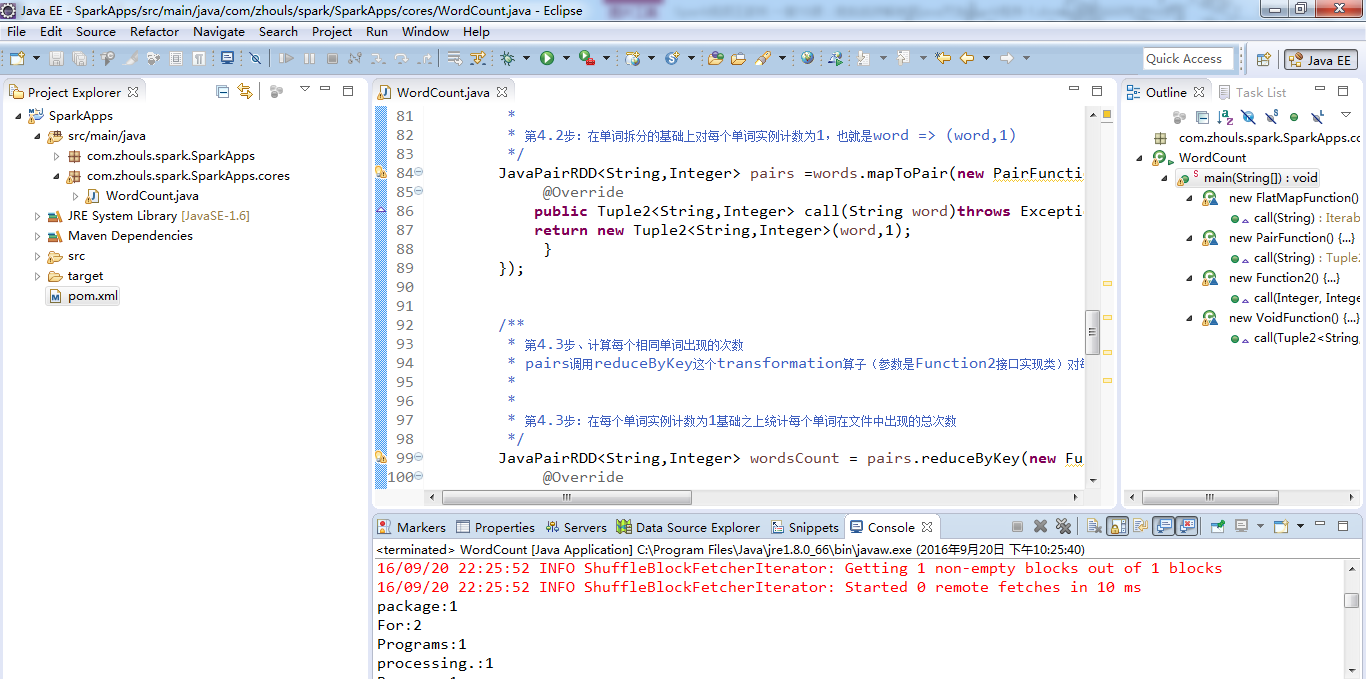
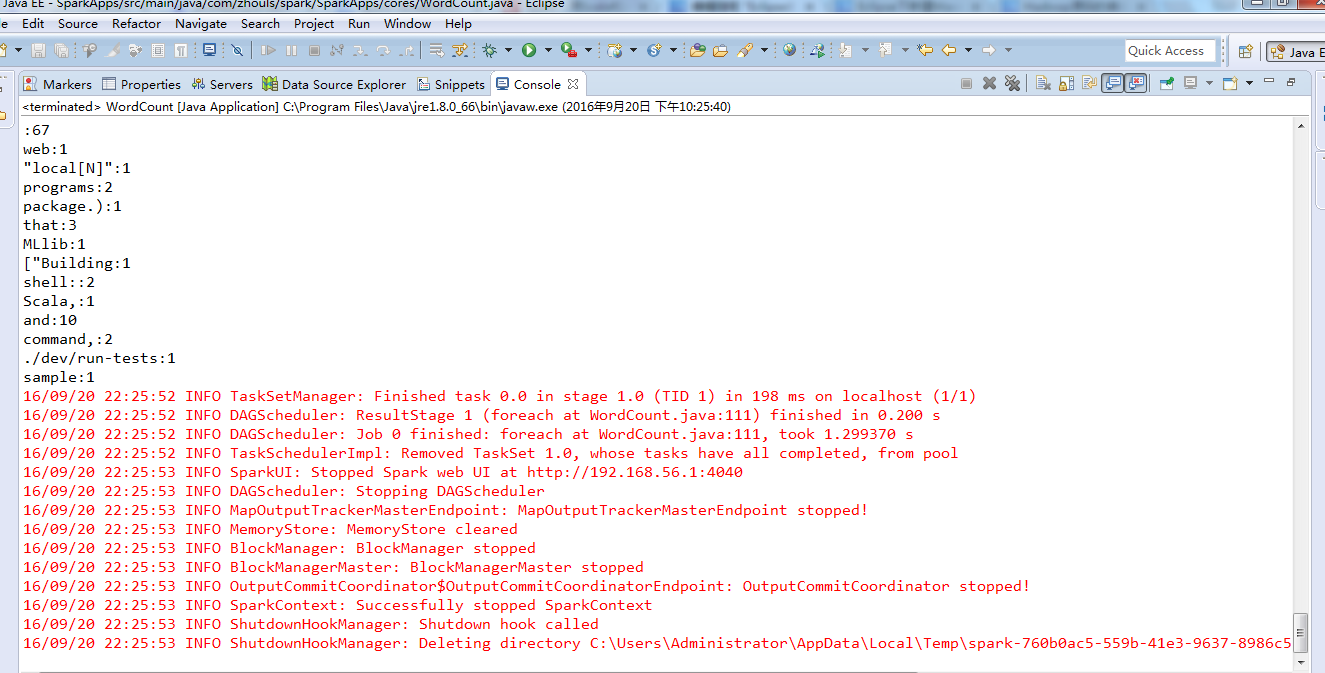
成功,上述不是 错误,
Spark-Java版本WordCount示例(本地local模式)
WordCount.java

package com.zhouls.spark.SparkApps.cores; import java.util.Arrays; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.FlatMapFunction; import org.apache.spark.api.java.function.Function2; import org.apache.spark.api.java.function.PairFunction; import org.apache.spark.api.java.function.VoidFunction; import scala.Tuple2; /** * Spark的WordCount程序 * @author zhouls * */ public class WordCount { public static void main(String[] args) { /** * 第1步:创建spark的配置对象SparkConf,设置spark程序的运行时的配置信息, * 例如说通过setMaster来设置程序要连接的spark集群的Master的URI,如果设置为local,则代表spark程序在本地运行, * 特别适合机器配置条件非常差(例如只有1G内存)的初学者 */ SparkConf conf = new SparkConf().setAppName("Spark WordCount written by Java").setMaster("local"); /** * 2、创建SparkContext对象,Java开发使用JavaSparkContext;Scala开发使用SparkContext * 在Spark中,SparkContext负责连接Spark集群,创建RDD、累积量和广播量等。 * Master参数是为了创建TaskSchedule(较低级的调度器,高层次的调度器为DAGSchedule),如下: * 如果setMaster("local")则创建LocalSchedule; * 如果setMaster("spark")则创建SparkDeploySchedulerBackend。在SparkDeploySchedulerBackend的start函数,会启动一个Client对象,连接到Spark集群。 * /* * 第2步:创建SparkContext对象 * SparkContext是Spark程序所有功能的唯一入口,无论是采用scala、Java、Python、R等都必须有一个SparkContext(不同的语言具体的类名称不同,如果是Java的话则为JavaSparkContext) * SparkContext核心作用,初始化Spark应用程序运行所需要的核心组件,包括DAGScheduler、TaskScheduler、SchedulerBackend * 同时还会负责Spark程序往Master注册程序等 * SparkContext是整个Spark应用程序中最为至关重要的一个对象 */ JavaSparkContext sc = new JavaSparkContext(conf);//其实,底层实际上就是scala的SparkContext /** * 第3步: sc中提供了textFile方法是SparkContext中定义的,如下: * def textFile(path: String): JavaRDD[String] = sc.textFile(path) * 用来读取HDFS上的文本文件、集群中节点的本地文本文件或任何支持Hadoop的文件系统上的文本文件,它的返回值是JavaRDD[String],是文本文件每一行 * * 第3步:根据具体的数据来源(如HDFS、HBase、Local FS、DB、S3等)通过JavaSparkContext来创建JavaRDD * JavaRDD的创建基本有三种方式:根据外部的数据来源(例如HDFS)、根据Scala集合、由其它的RDD操作 * 数据会被RDD划分成一系列的Partitions,分配到每个Partition的数据属于一个Task的处理范畴 */ JavaRDD<String> lines = sc.textFile("D://SoftWare//spark-1.5.2-bin-hadoop2.6//README.md"); /** * 4、将行文本内容拆分为多个单词 * lines调用flatMap这个transformation算子(参数类型是FlatMapFunction接口实现类)返回每一行的每个单词 * /* * 第4步:对初始的JavaRDD进行Transformation级别的处理,例如map、filter等高阶函数等的编程,来进行具体的数据计算 * 第4.1步:将每一行的字符串拆分成单个的单词 */ JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String,String>(){ @Override public Iterable<String> call(String line) throws Exception { return Arrays.asList(line.split(" ")); } }); /** * 第4.2步、将每个单词的初始数量都标记为1个 * words调用mapToPair这个transformation算子(参数类型是PairFunction接口实现类,PairFunction<String, String, Integer>的三个参数是<输入单词, Tuple2的key, Tuple2的value>),返回一个新的RDD,即JavaPairRDD * * * 第4.2步:在单词拆分的基础上对每个单词实例计数为1,也就是word => (word,1) */ JavaPairRDD<String,Integer> pairs =words.mapToPair(new PairFunction<String,String,Integer>(){ @Override public Tuple2<String,Integer> call(String word)throws Exception{ return new Tuple2<String,Integer>(word,1); } }); /** * 第4.3步、计算每个相同单词出现的次数 * pairs调用reduceByKey这个transformation算子(参数是Function2接口实现类)对每个key的value进行reduce操作,返回一个JavaPairRDD,这个JavaPairRDD中的每一个Tuple的key是单词、value则是相同单词次数的和 * * * 第4.3步:在每个单词实例计数为1基础之上统计每个单词在文件中出现的总次数 */ JavaPairRDD<String,Integer> wordsCount = pairs.reduceByKey(new Function2<Integer,Integer,Integer>(){ @Override public Integer call(Integer v1,Integer v2)throws Exception{ return v1 + v2; } }); /** * 第5步: 使用foreach这个action算子提交Spark应用程序 * 在Spark中,每个应用程序都需要transformation算子计算,最终由action算子触发作业提交 */ wordsCount.foreach(new VoidFunction<Tuple2<String,Integer>>() { @Override public void call(Tuple2<String, Integer> pairs) throws Exception { System.out.println(pairs._1+":"+pairs._2); } }); /** * 第6步:关闭SparkContext容器,结束本次作业 */ sc.close(); } }
Spark-Java版本WordCount示例(集群模式)
注意,这是,Ubuntu系统下的路径而已
/usr/local/spark/spark-1.5.2-bin-hadoop2.6
这里,必须要复制一份,到hdfs上,即Hadoop集群上。
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0$
bin/hadoop fs -copyFromLocal /usr/local/spark/spark-1.5.2-bin-hadoop2.6/README.md hdfs://SparkSingleNode:9000/
这样, 就可以了。
WordCountCluster.java
package com.zhouls.spark.SparkApps.cores; import java.util.Arrays; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.FlatMapFunction; import org.apache.spark.api.java.function.Function2; import org.apache.spark.api.java.function.PairFunction; import org.apache.spark.api.java.function.VoidFunction; import scala.Tuple2; /** * Spark的WordCountCluster程序 * @author zhouls * */ public class WordCountCluster { public static void main(String[] args) { /** * 第1步:创建spark的配置对象SparkConf,设置spark程序的运行时的配置信息, * 例如说通过setMaster来设置程序要连接的spark集群的Master的URI,如果设置为local,则代表spark程序在本地运行, * 特别适合机器配置条件非常差(例如只有1G内存)的初学者 */ SparkConf conf = new SparkConf().setAppName("Spark WordCount written by Java").setMaster("local"); /** * 2、创建SparkContext对象,Java开发使用JavaSparkContext;Scala开发使用SparkContext * 在Spark中,SparkContext负责连接Spark集群,创建RDD、累积量和广播量等。 * Master参数是为了创建TaskSchedule(较低级的调度器,高层次的调度器为DAGSchedule),如下: * 如果setMaster("local")则创建LocalSchedule; * 如果setMaster("spark")则创建SparkDeploySchedulerBackend。在SparkDeploySchedulerBackend的start函数,会启动一个Client对象,连接到Spark集群。 * /* * 第2步:创建SparkContext对象 * SparkContext是Spark程序所有功能的唯一入口,无论是采用scala、Java、Python、R等都必须有一个SparkContext(不同的语言具体的类名称不同,如果是Java的话则为JavaSparkContext) * SparkContext核心作用,初始化Spark应用程序运行所需要的核心组件,包括DAGScheduler、TaskScheduler、SchedulerBackend * 同时还会负责Spark程序往Master注册程序等 * SparkContext是整个Spark应用程序中最为至关重要的一个对象 */ JavaSparkContext sc = new JavaSparkContext(conf);//其实,底层实际上就是scala的SparkContext /** * 第3步: sc中提供了textFile方法是SparkContext中定义的,如下: * def textFile(path: String): JavaRDD[String] = sc.textFile(path) * 用来读取HDFS上的文本文件、集群中节点的本地文本文件或任何支持Hadoop的文件系统上的文本文件,它的返回值是JavaRDD[String],是文本文件每一行 * * 第3步:根据具体的数据来源(如HDFS、HBase、Local FS、DB、S3等)通过JavaSparkContext来创建JavaRDD * JavaRDD的创建基本有三种方式:根据外部的数据来源(例如HDFS)、根据Scala集合、由其它的RDD操作 * 数据会被RDD划分成一系列的Partitions,分配到每个Partition的数据属于一个Task的处理范畴 */ JavaRDD<String> lines = sc.textFile("hdfs://SparkSingleNode:9000/README.md"); /** * 4、将行文本内容拆分为多个单词 * lines调用flatMap这个transformation算子(参数类型是FlatMapFunction接口实现类)返回每一行的每个单词 * /* * 第4步:对初始的JavaRDD进行Transformation级别的处理,例如map、filter等高阶函数等的编程,来进行具体的数据计算 * 第4.1步:将每一行的字符串拆分成单个的单词 */ JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String,String>(){ private static final long serialVersionUID = -3243665984299496473L; @Override public Iterable<String> call(String line) throws Exception { return Arrays.asList(line.split(" ")); } }); /** * 第4.2步、将每个单词的初始数量都标记为1个 * words调用mapToPair这个transformation算子(参数类型是PairFunction接口实现类,PairFunction<String, String, Integer>的三个参数是<输入单词, Tuple2的key, Tuple2的value>),返回一个新的RDD,即JavaPairRDD * * * 第4.2步:在单词拆分的基础上对每个单词实例计数为1,也就是word => (word,1) */ JavaPairRDD<String,Integer> pairs =words.mapToPair(new PairFunction<String,String,Integer>(){ private static final long serialVersionUID = -7879847028195817507L; @Override public Tuple2<String,Integer> call(String word)throws Exception{ return new Tuple2<String,Integer>(word,1); } }); /** * 第4.3步、计算每个相同单词出现的次数 * pairs调用reduceByKey这个transformation算子(参数是Function2接口实现类)对每个key的value进行reduce操作,返回一个JavaPairRDD,这个JavaPairRDD中的每一个Tuple的key是单词、value则是相同单词次数的和 * * * 第4.3步:在每个单词实例计数为1基础之上统计每个单词在文件中出现的总次数 */ JavaPairRDD<String,Integer> wordsCount = pairs.reduceByKey(new Function2<Integer,Integer,Integer>(){ private static final long serialVersionUID = -4171349401750495688L; @Override public Integer call(Integer v1,Integer v2)throws Exception{ return v1 + v2; } }); /** * 第5步: 使用foreach这个action算子提交Spark应用程序 * 在Spark中,每个应用程序都需要transformation算子计算,最终由action算子触发作业提交 */ wordsCount.foreach(new VoidFunction<Tuple2<String,Integer>>() { private static final long serialVersionUID = -5926812153234798612L; @Override public void call(Tuple2<String, Integer> pairs) throws Exception { System.out.println(pairs._1+":"+pairs._2); } }); /** * 8、将计算结果文件输出到文件系统 * HDFS: * 使用新版API(org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;) * wordCount.saveAsNewAPIHadoopFile("hdfs://SparkSingleNode:9000/wordcount", Text.class, IntWritable.class, TextOutputFormat.class, new Configuration()); * 使用旧版API(org.apache.hadoop.mapred.JobConf;org.apache.hadoop.mapred.OutputFormat;) * wordCount.saveAsHadoopFile("hdfs://SparkSingleNode:9000/wordcount", Text.class, IntWritable.class, OutputFormat.class, new JobConf(new Configuration())); * 使用默认TextOutputFile写入到HDFS(注意写入HDFS权限,如无权限则执行:hdfs dfs -chmod -R 777 /wordcount) * wordCount.saveAsTextFile("hdfs://SparkSingleNode:9000/README.md"); */ wordsCount.saveAsTextFile("hdfs://SparkSingleNode:9000/wordcount"); /** * 第7步:关闭SparkContext容器,结束本次作业 */ sc.close(); } }
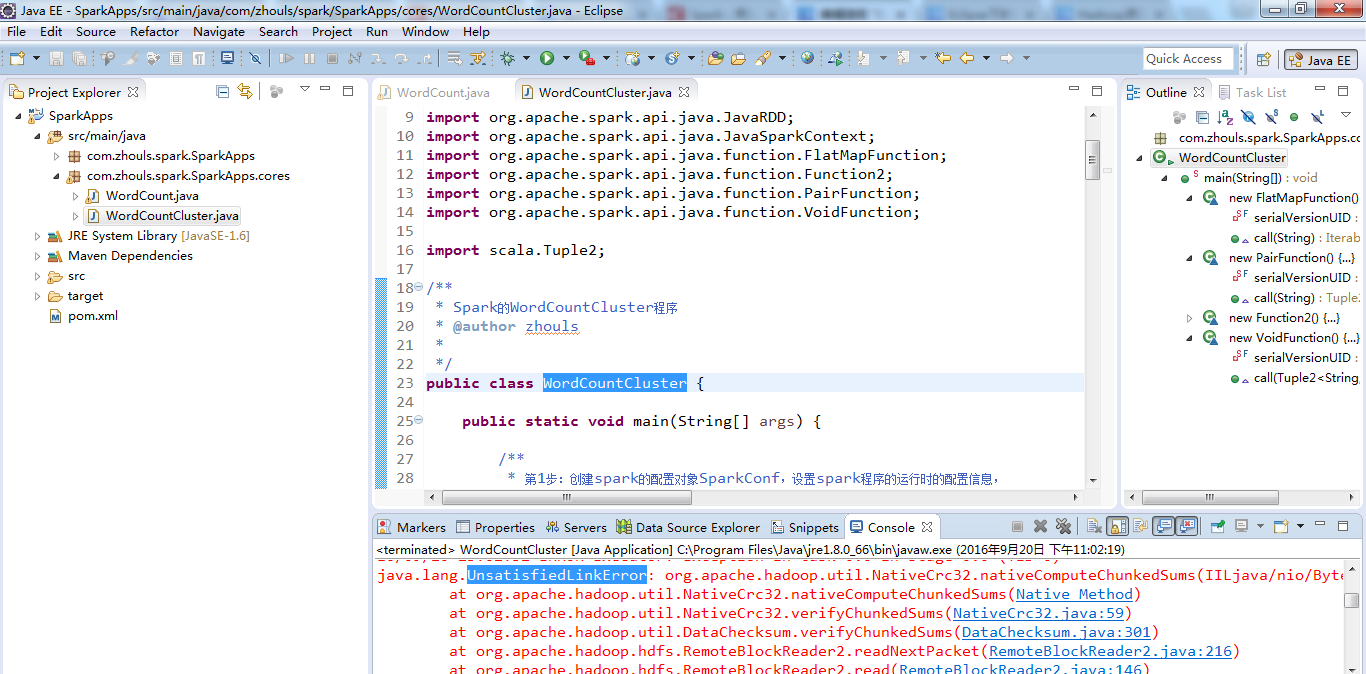
在这里,遇到了问题,
本文转自大数据躺过的坑博客园博客,原文链接:http://www.cnblogs.com/zlslch/p/5882231.html,如需转载请自行联系原作者




