







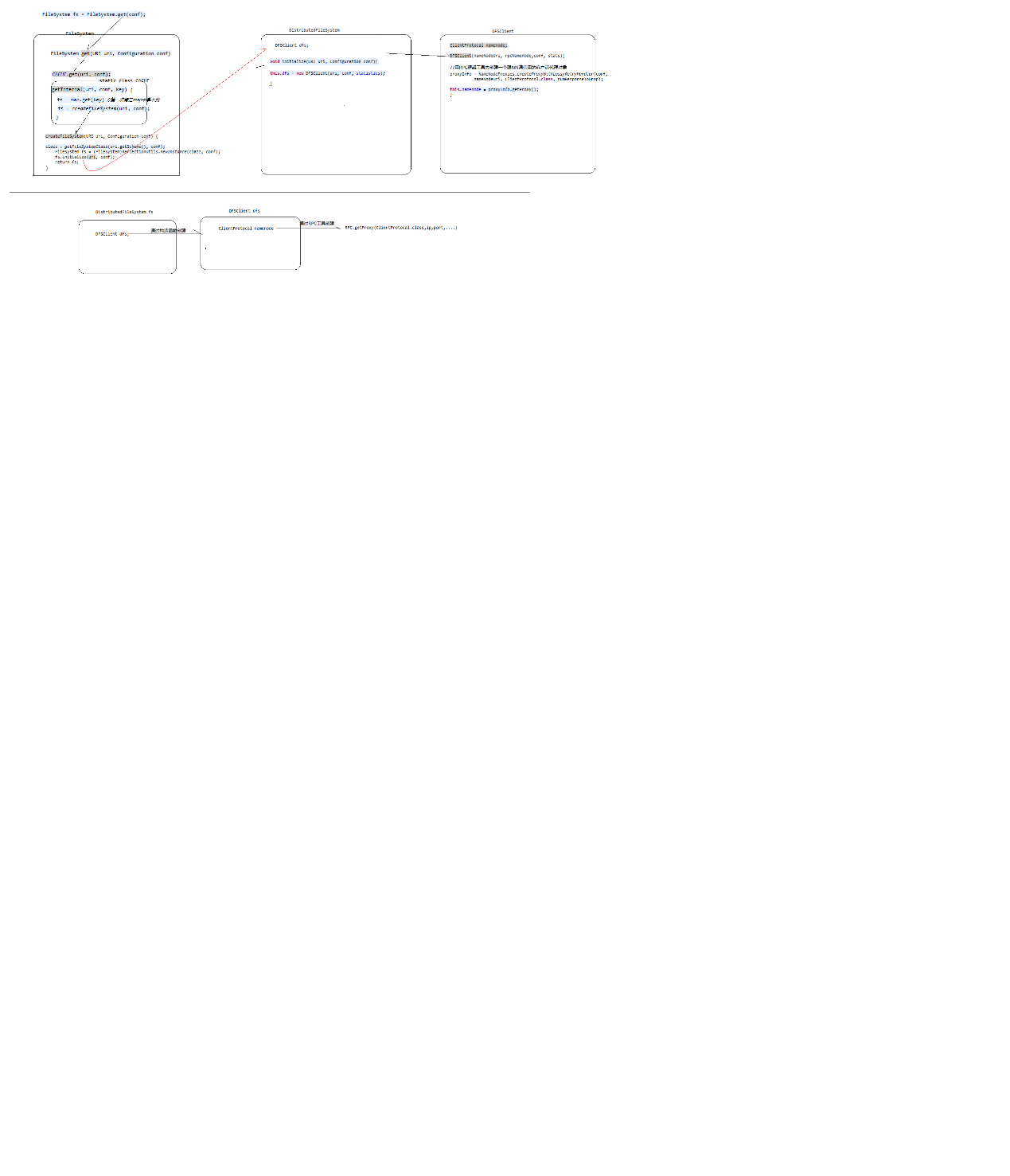
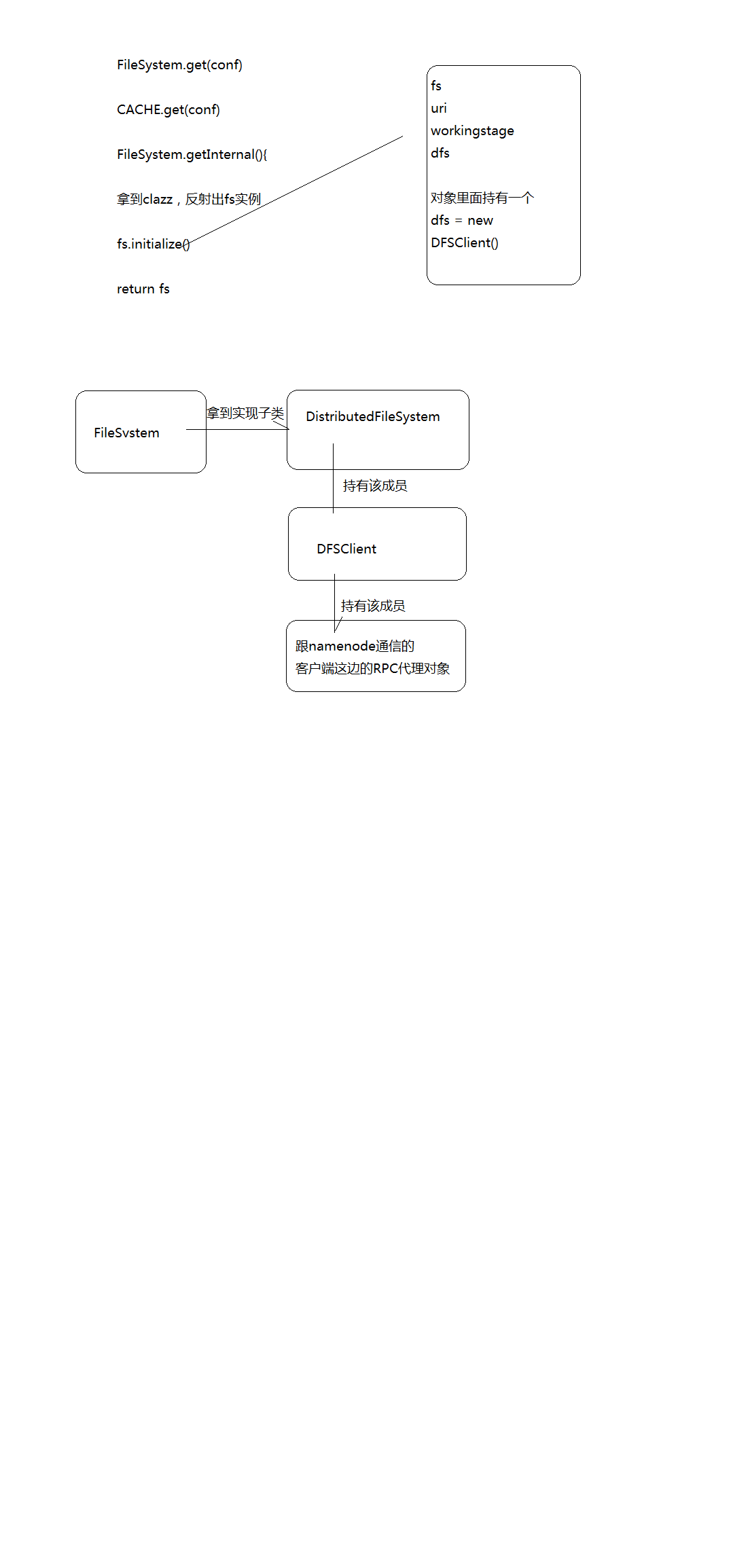
Hdfs下载数据源码分析
在这里,我是接着之前的,贴下代码
package cn.itcast.hadoop.hdfs;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.commons.io.IOUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
import org.junit.Before;
import org.junit.Test;
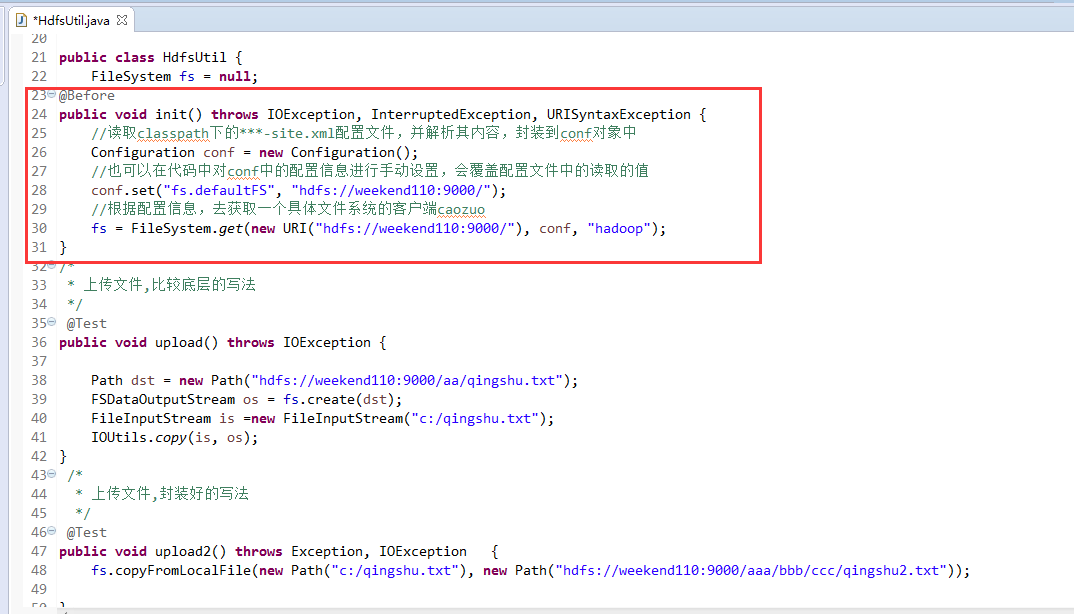
public class HdfsUtil {
FileSystem fs = null;
@Before
public void init() throws IOException, InterruptedException, URISyntaxException {
//读取classpath下的***-site.xml配置文件,并解析其内容,封装到conf对象中
Configuration conf = new Configuration();
//也可以在代码中对conf中的配置信息进行手动设置,会覆盖配置文件中的读取的值
conf.set("fs.defaultFS", "hdfs://weekend110:9000/");
//根据配置信息,去获取一个具体文件系统的客户端caozuo
fs = FileSystem.get(new URI("hdfs://weekend110:9000/"), conf, "hadoop");
}
/*
* 上传文件,比较底层的写法
*/
@Test
public void upload() throws IOException {
Path dst = new Path("hdfs://weekend110:9000/aa/qingshu.txt");
FSDataOutputStream os = fs.create(dst);
FileInputStream is =new FileInputStream("c:/qingshu.txt");
IOUtils.copy(is, os);
}
/*
* 上传文件,封装好的写法
*/
@Test
public void upload2() throws Exception, IOException {
fs.copyFromLocalFile(new Path("c:/qingshu.txt"), new Path("hdfs://weekend110:9000/aaa/bbb/ccc/qingshu2.txt"));
}
/*
* 下载文件,封装好的写法
*/
@Test
public void download() throws Exception, IOException{
fs.copyToLocalFile(new Path("hdfs://weekend110:9000/aa/qingshu2.txt"), new Path("c:/qingshu2.txt"));
}
/*
* 查看文件信息,封装好的写法
*/
@Test
public void listFiles() throws FileNotFoundException, IllegalArgumentException, IOException {
// listFiles列出的是文件信息,而且提供递归遍历
RemoteIterator<LocatedFileStatus> files = fs.listFiles(new Path("/"), true);
while (files.hasNext()){
LocatedFileStatus file = files.next();
Path filePath = file.getPath();
String fileName = filePath.getName();
System.out.println(fileName);
}
System.out.println("----------------------");
// listStatus列出的是文件和目录的信息,但是不提供自带的递归遍历
FileStatus[] listStatus = fs.listStatus(new Path("/"));
for(FileStatus status : listStatus ){
String name = status.getPath().getName();
System.out.println(name + (status.isDirectory()?"id dir":"is file"));
}
}
/*
* 创建目录,封装好的写法
*/
@Test
public void mkdir() throws Exception, IOException{
fs.mkdirs(new Path("/aaa/bbb/ccc"));
}
/*
* 删除文件或目录,封装好的写法
*/
@Test
public void rm() throws Exception, IOException{
fs.delete(new Path("/aa"), true);
}
}

拿到mian方法里去了,

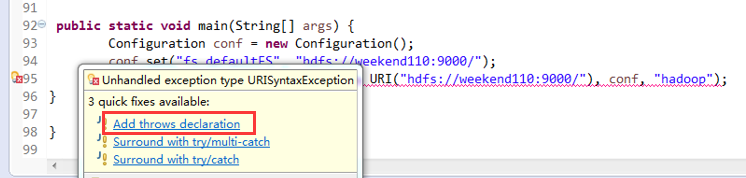





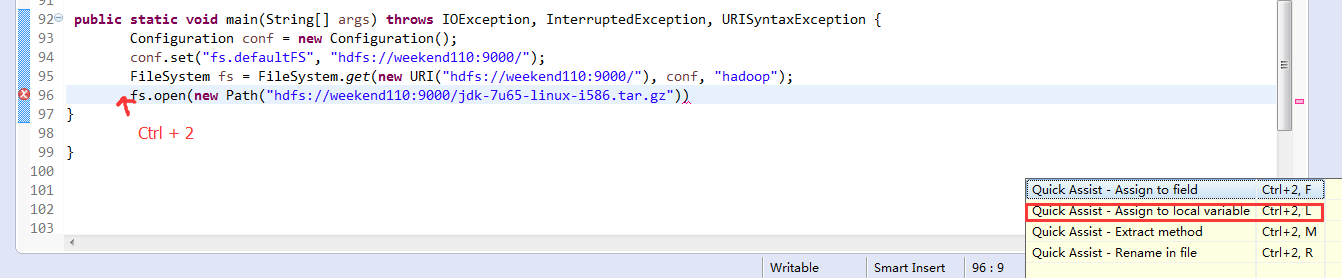
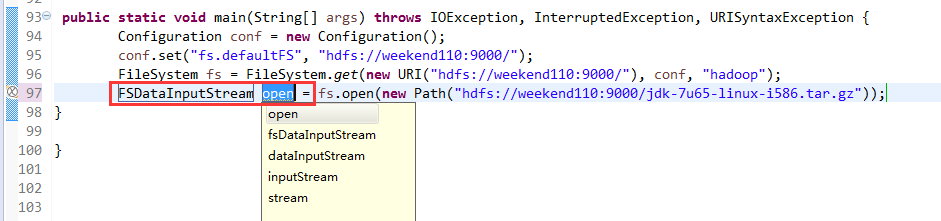



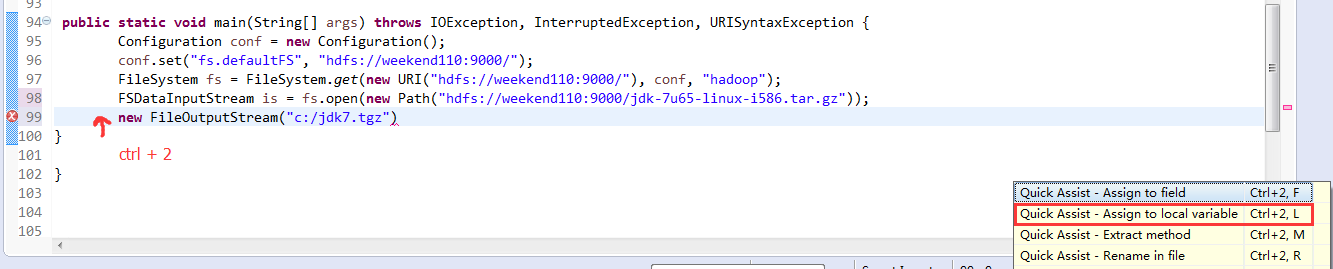



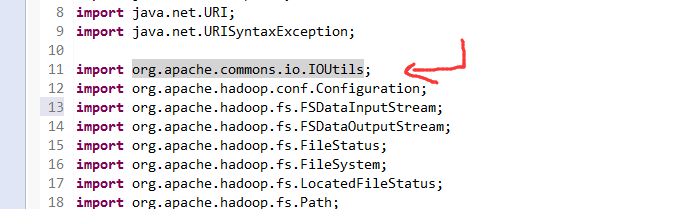
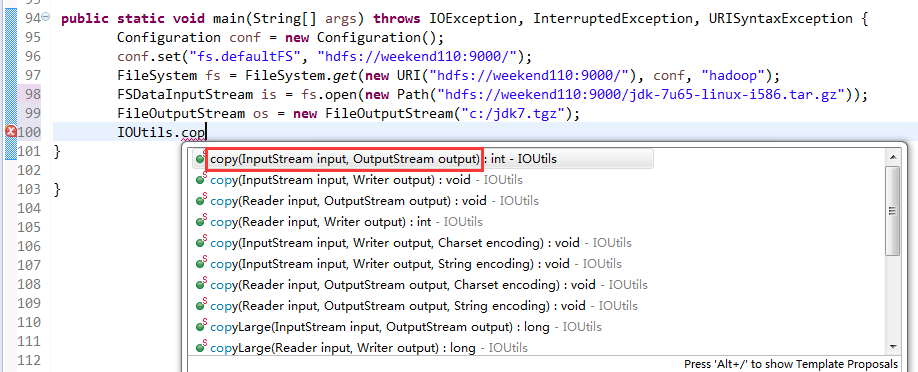
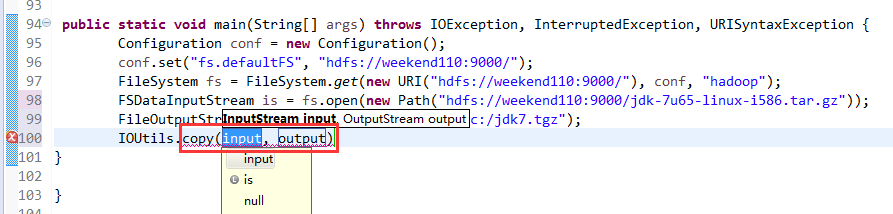


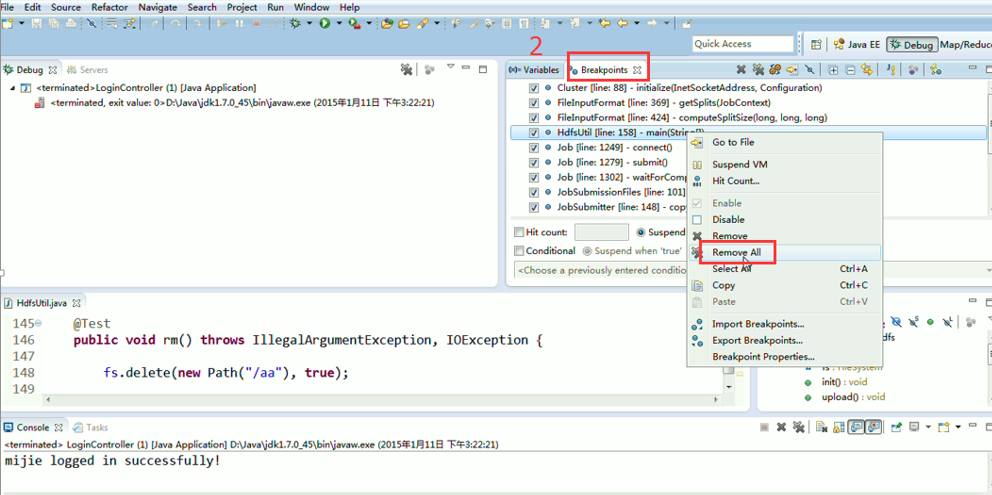
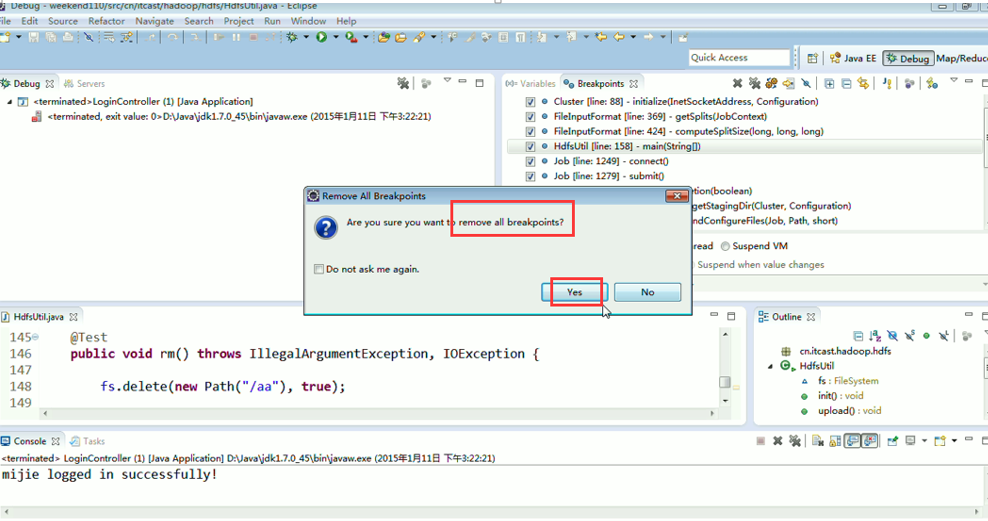
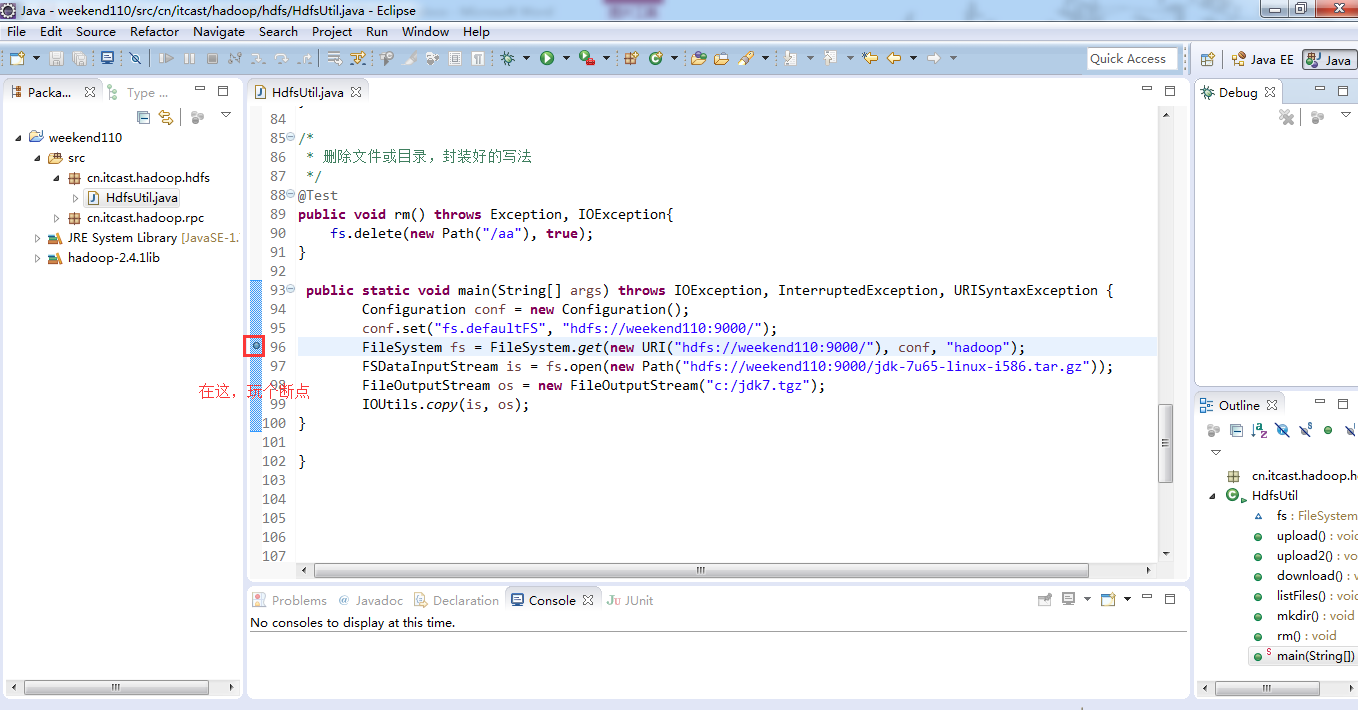
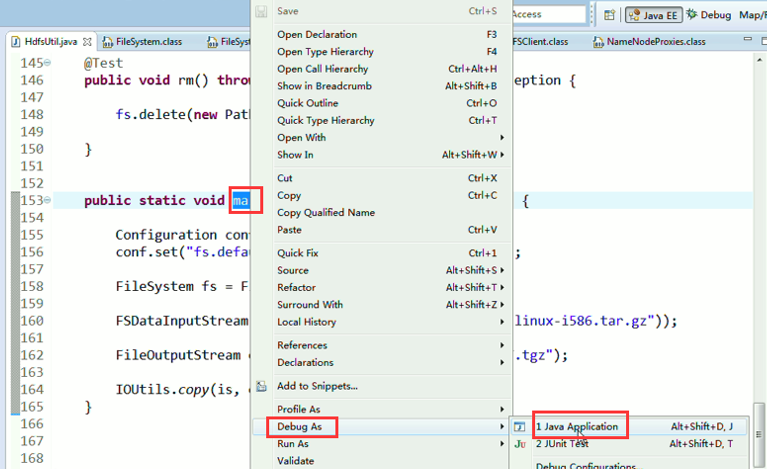
一般是,清楚之前所有的断点,最好先这样,不管它有没有。
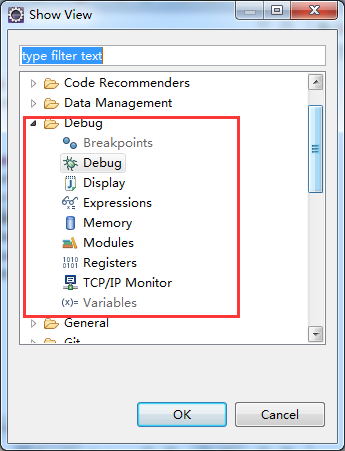
调出Debug工具框,window -> show view -> other –> Debug ->

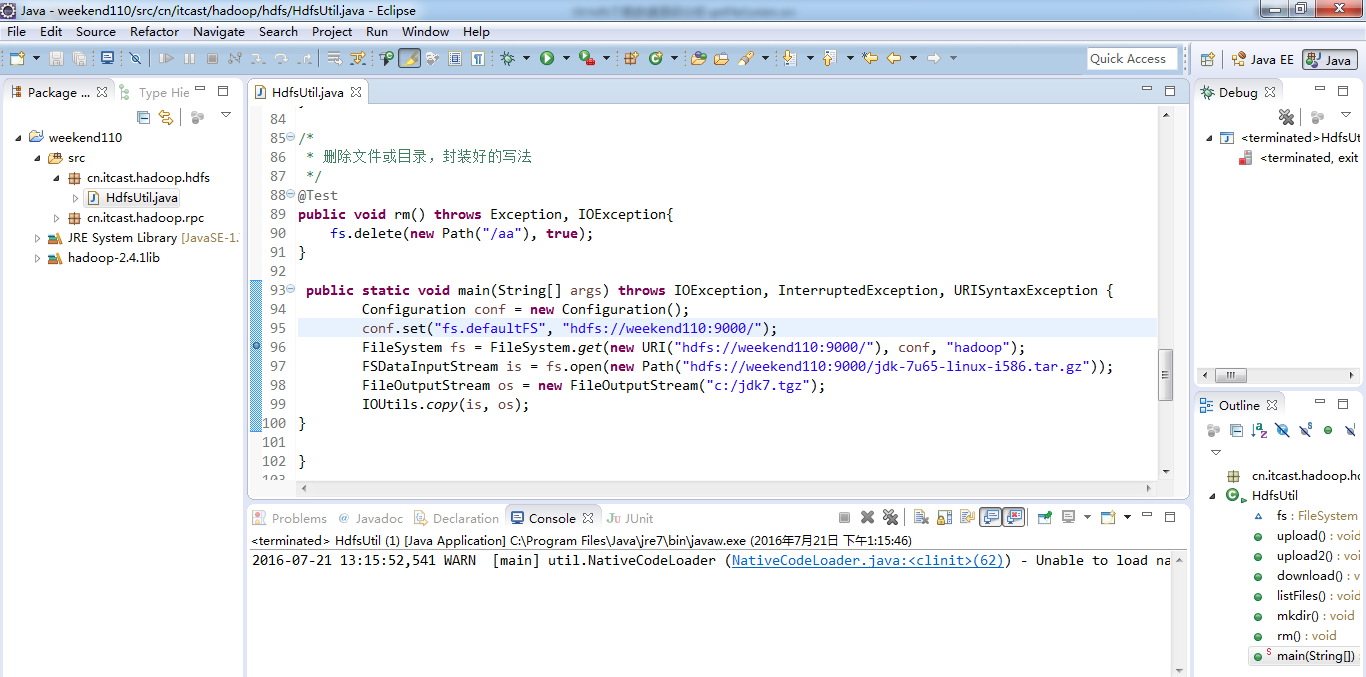

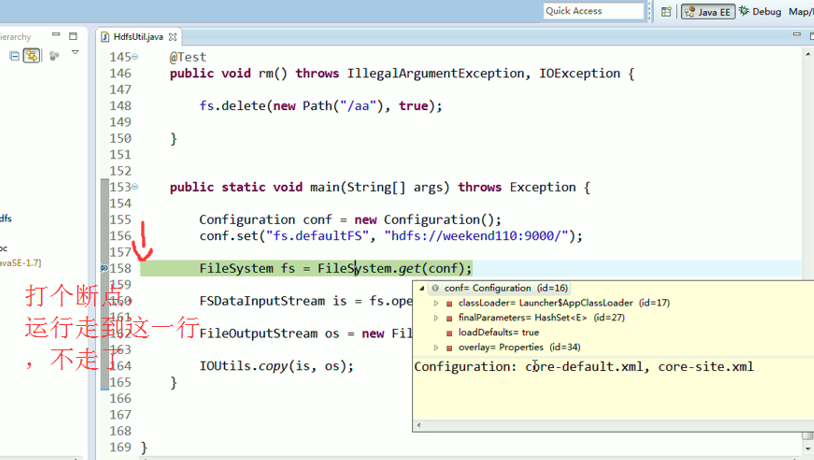
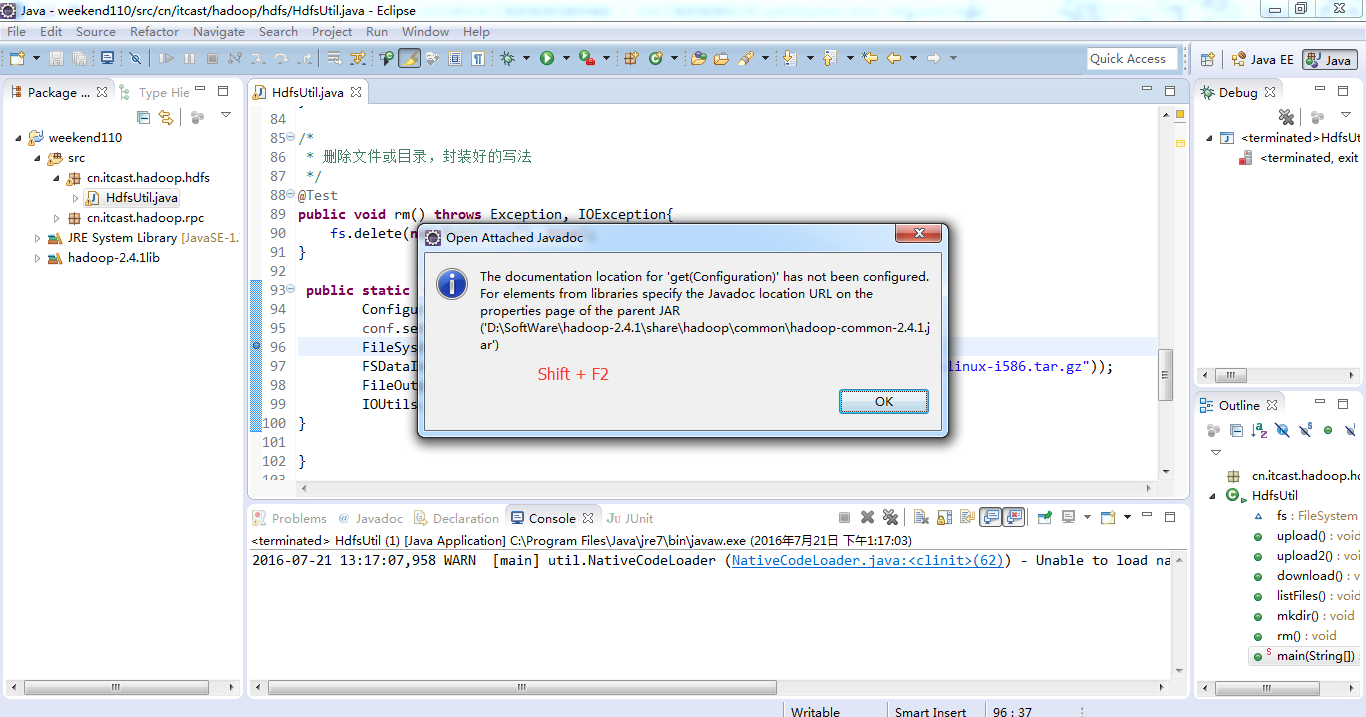
为什么不一样的结果,寻找原因,说明没有安装调用javadoc
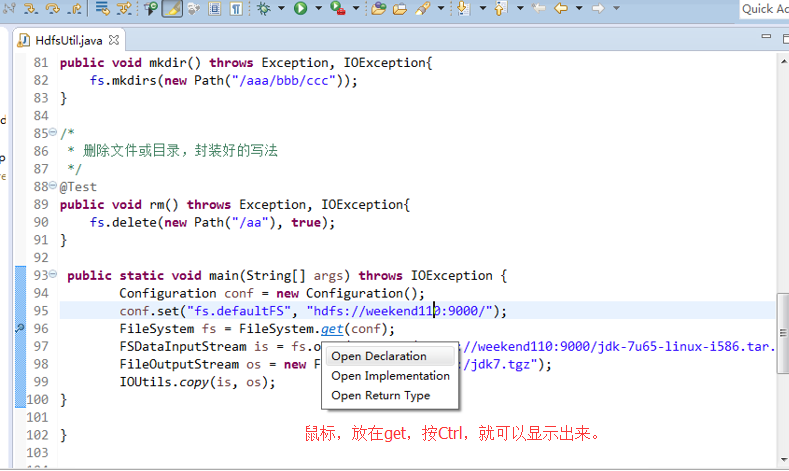
http://jingyan.baidu.com/article/6079ad0e86f69928ff86dbe6.html
http://blog.csdn.net/jxtrg20111218/article/details/8179415
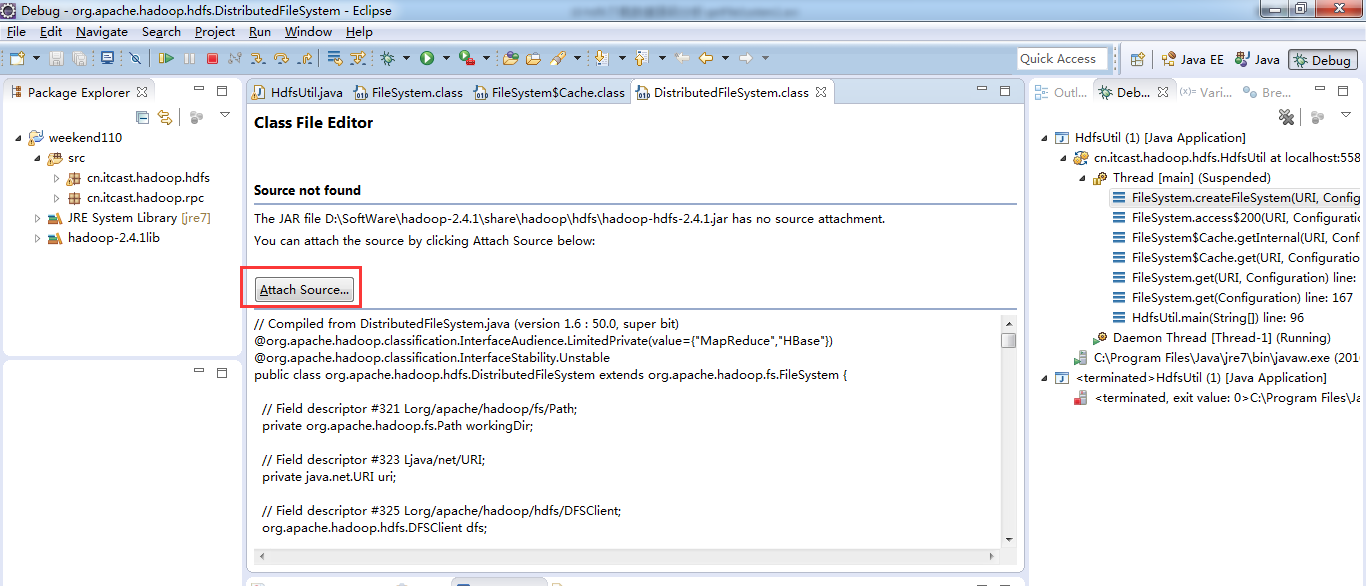
This element neither has attached source nor attached Javadoc and hence no Javadoc could be found
Eclipse有直接查看java文档和类库源码的功能,不过得手工添加才行,下面对如何在Eclipse中添加java文档和类库源码进行总结。
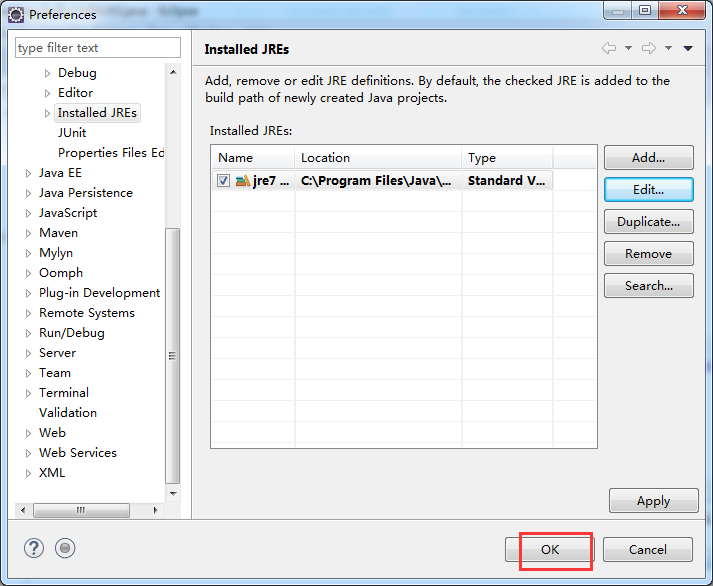
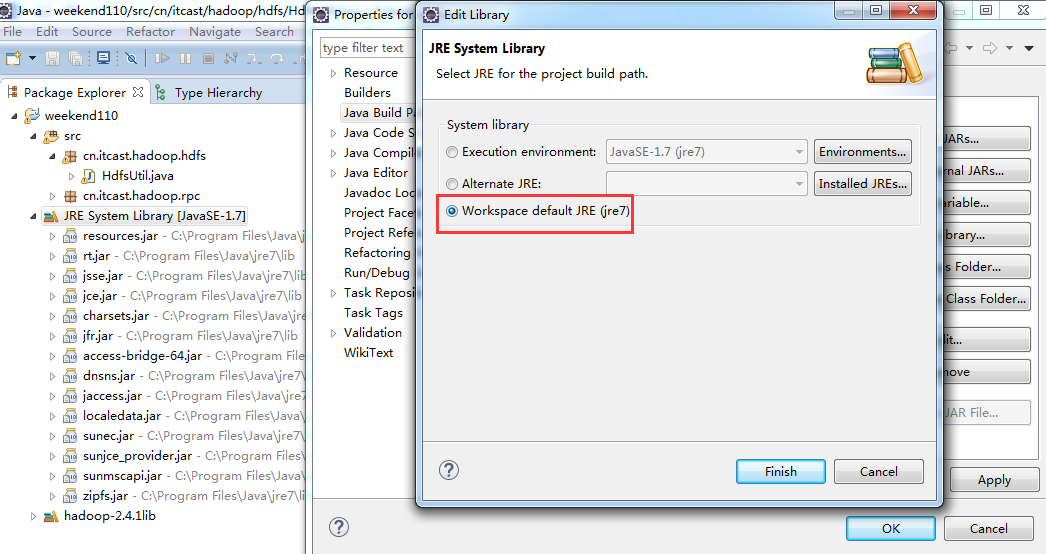
- Window->Pereferences...打开参数选择对话框,展开Java节点,单击“Installed JREs",此时右边窗口会显示已经加载的jre。

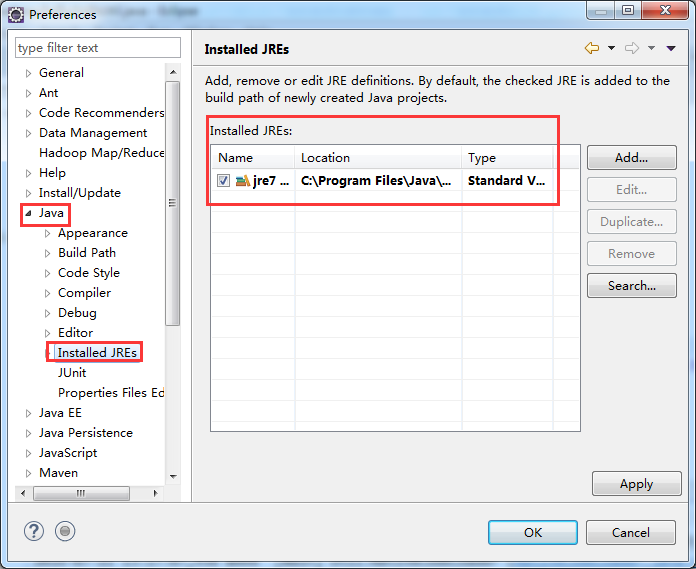
2、选中要设置的jre版本,单击"Edit",弹出JRE编辑窗口
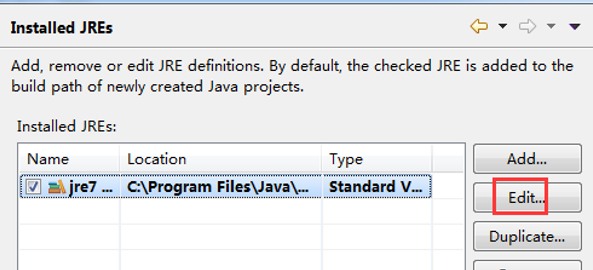
3、添加javadoc:将JRE system libraries下的所有包选中,单击右边的“Javadoc Location”按钮,弹出javadoc设置窗口。
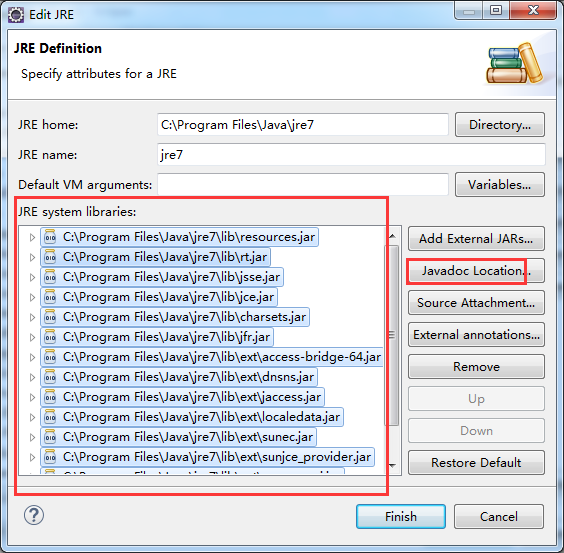
选择“Javadoc URL”单选框,单击“Browse”按钮,
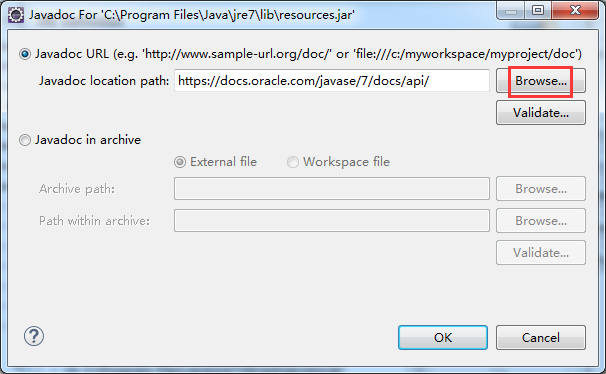
选中docs/api目录,然后点击“OK”
可以看出,已经本来就好的。
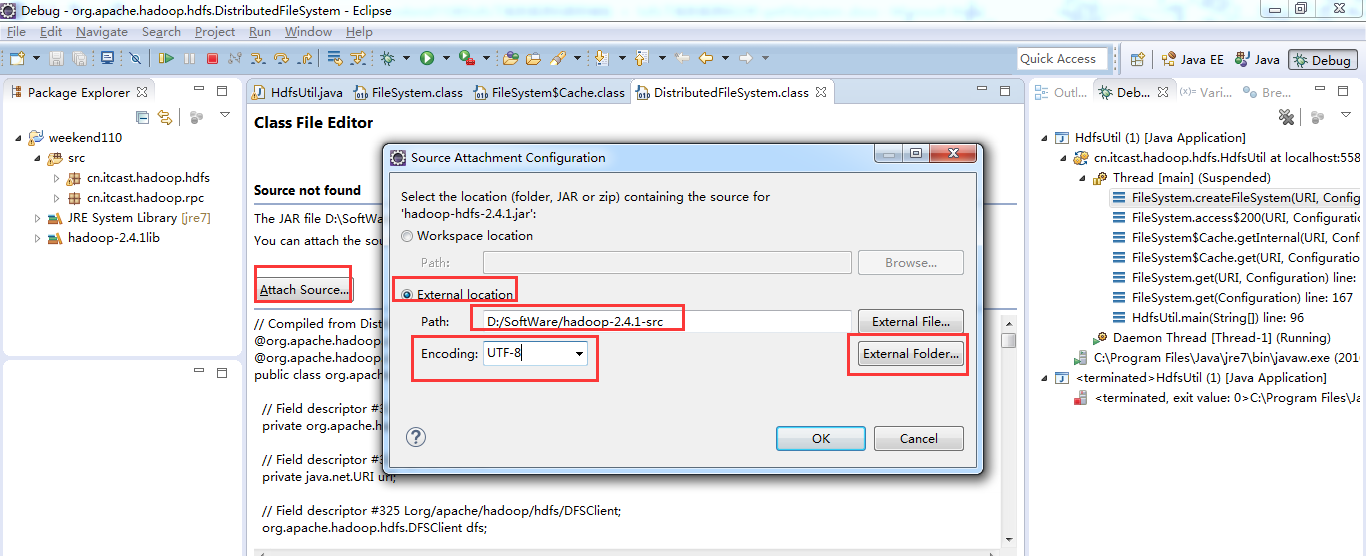
4、添加source: 将JRE system libraries下的所有包选中,单击右边的“Source Attachment”按钮,弹出source attachment configuration窗口。

单击“External File”按钮,选中java安装目录中的src.zip文件,然后点击“OK”
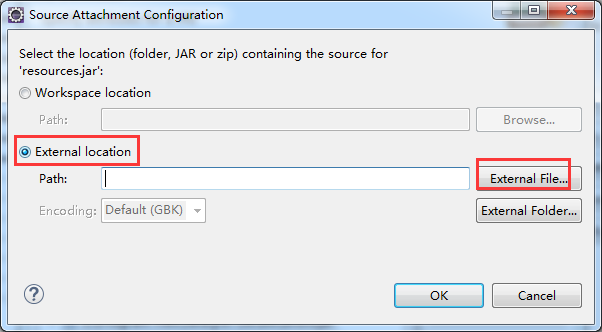
默认打开是,C:\Program Files\Java\jre7\lib
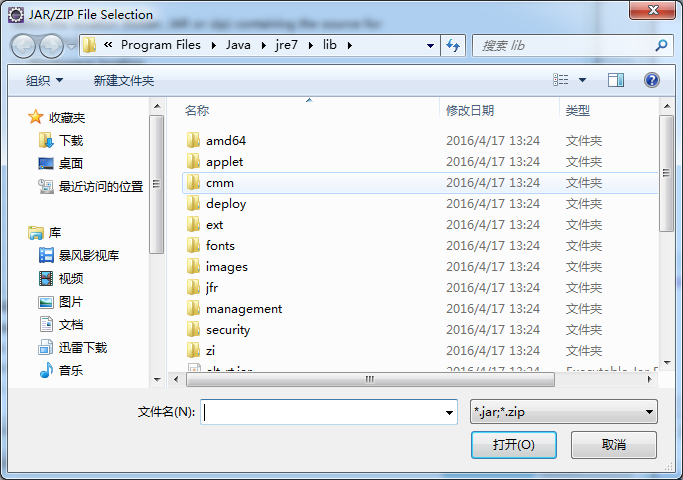
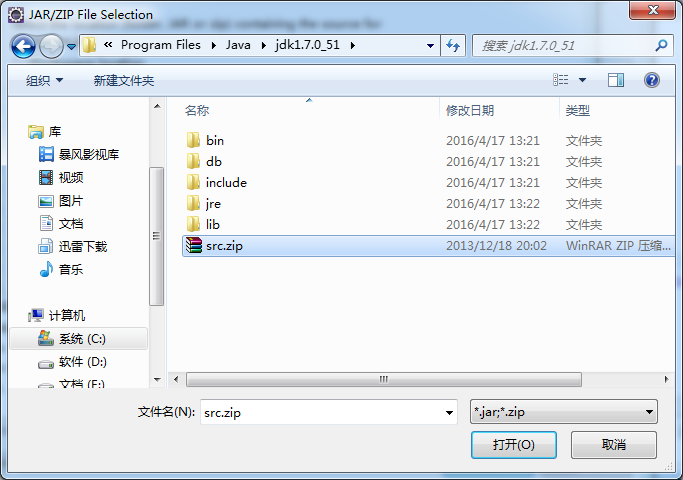

5、后面就一路OK、确定就行了。

6.在添加好了javadoc与source后,在eclipse中,使用快捷键"Shift+F2",可快速调出选中类的api文档;使用快捷建F3(或在类上点击右键,现在查看声明),可打开类的源文件。
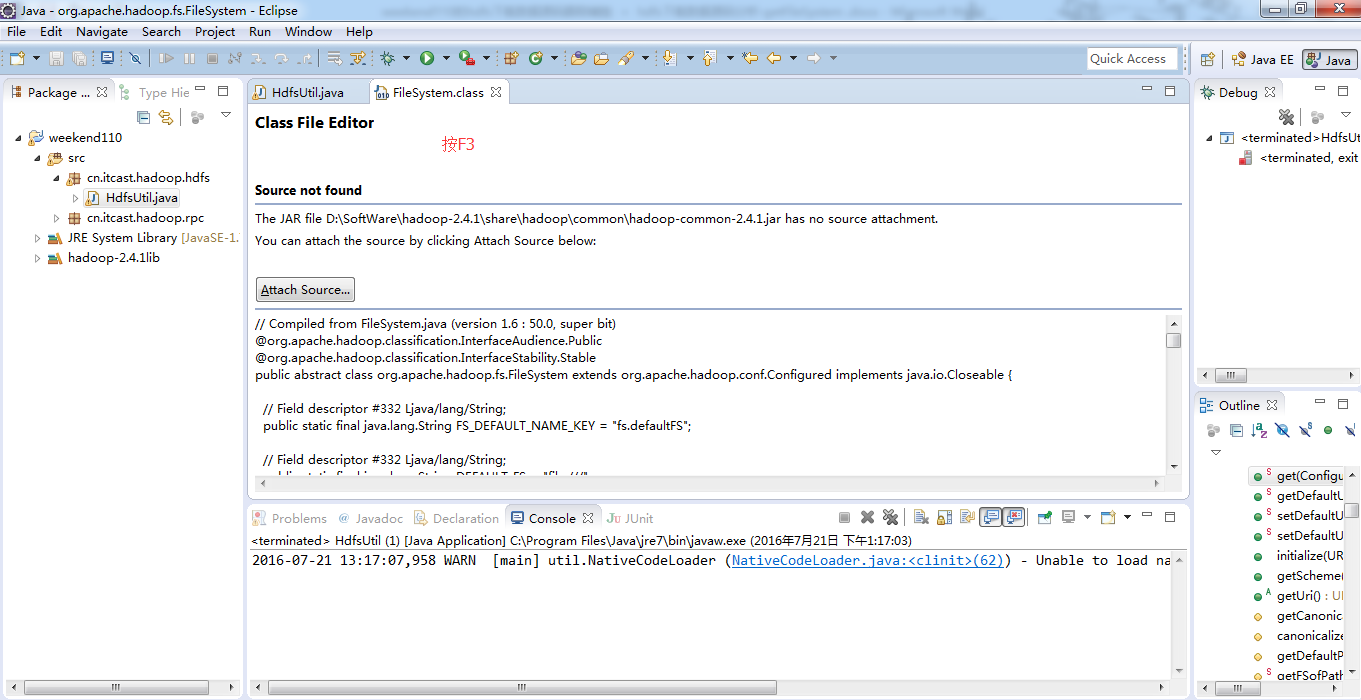
默认是,D:\SoftWare\hadoop-2.4.1\share\hadoop\common

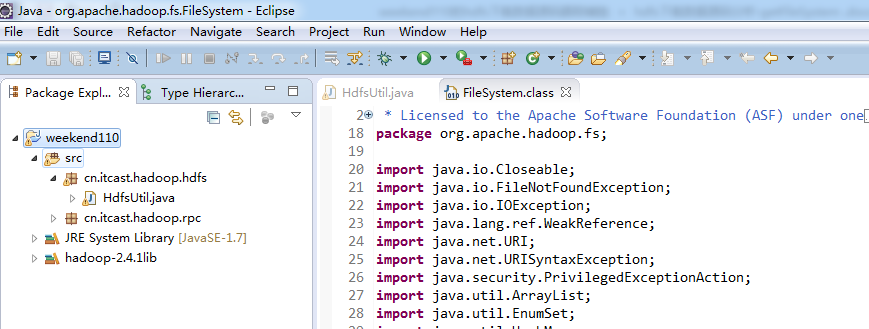
成功!
<terminated, exit value: 0>C:\Program Files\Java\jre7\bin\javaw.exe (2016年7月21日 下午8:55:19)

这里,是自出增加Debug窗口的。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
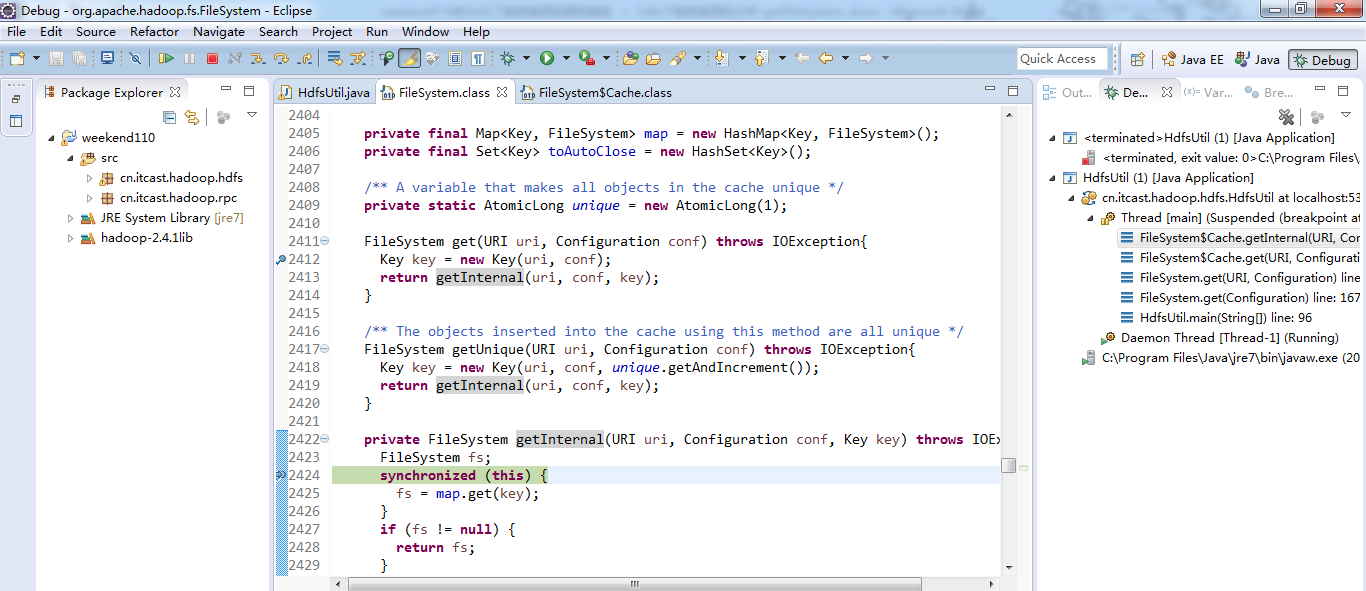
经过上面的处理一些问题,通常是如下步骤,进行断点调试。。。。。
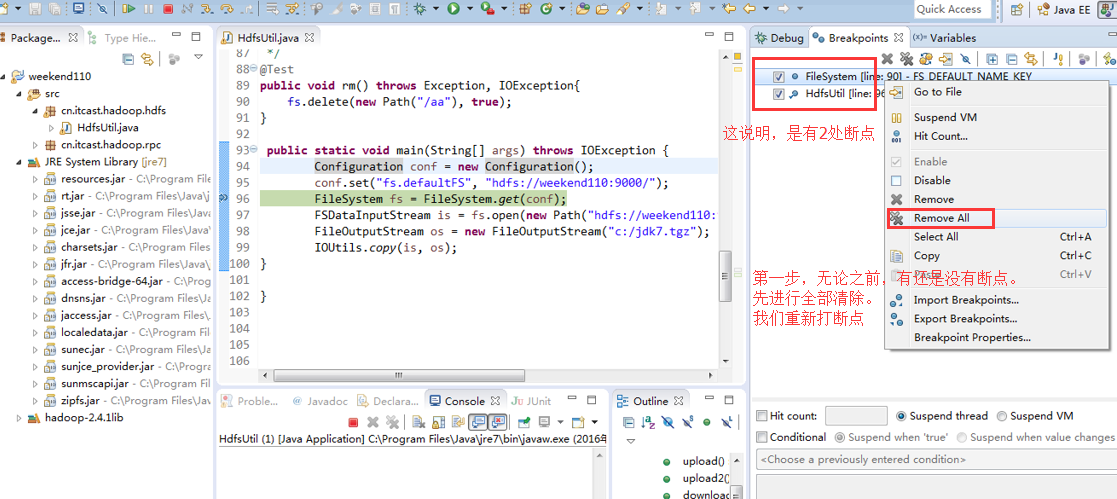


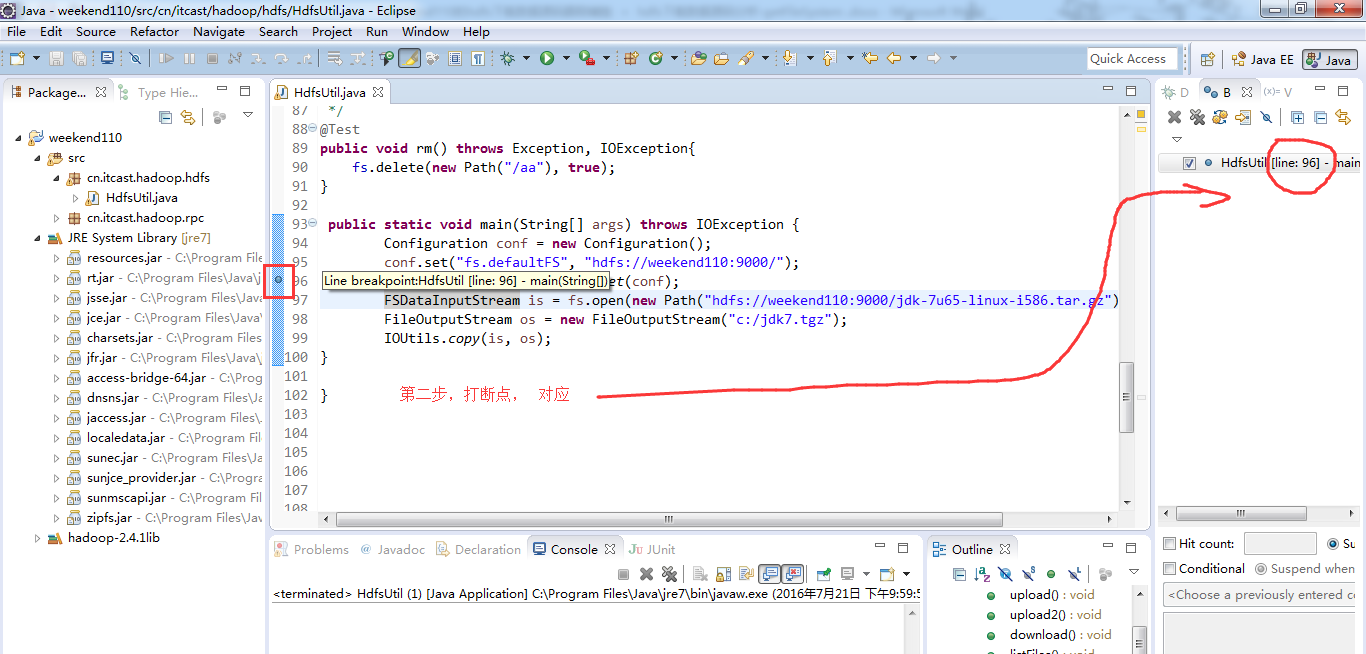


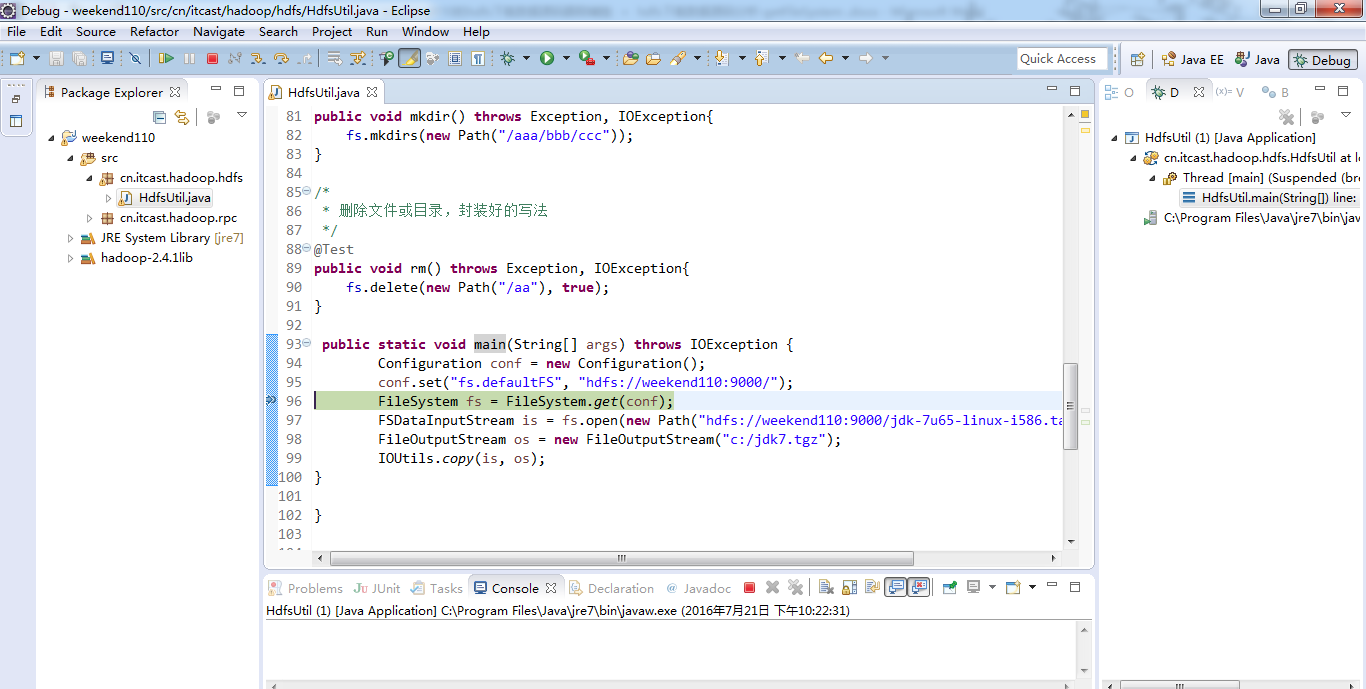
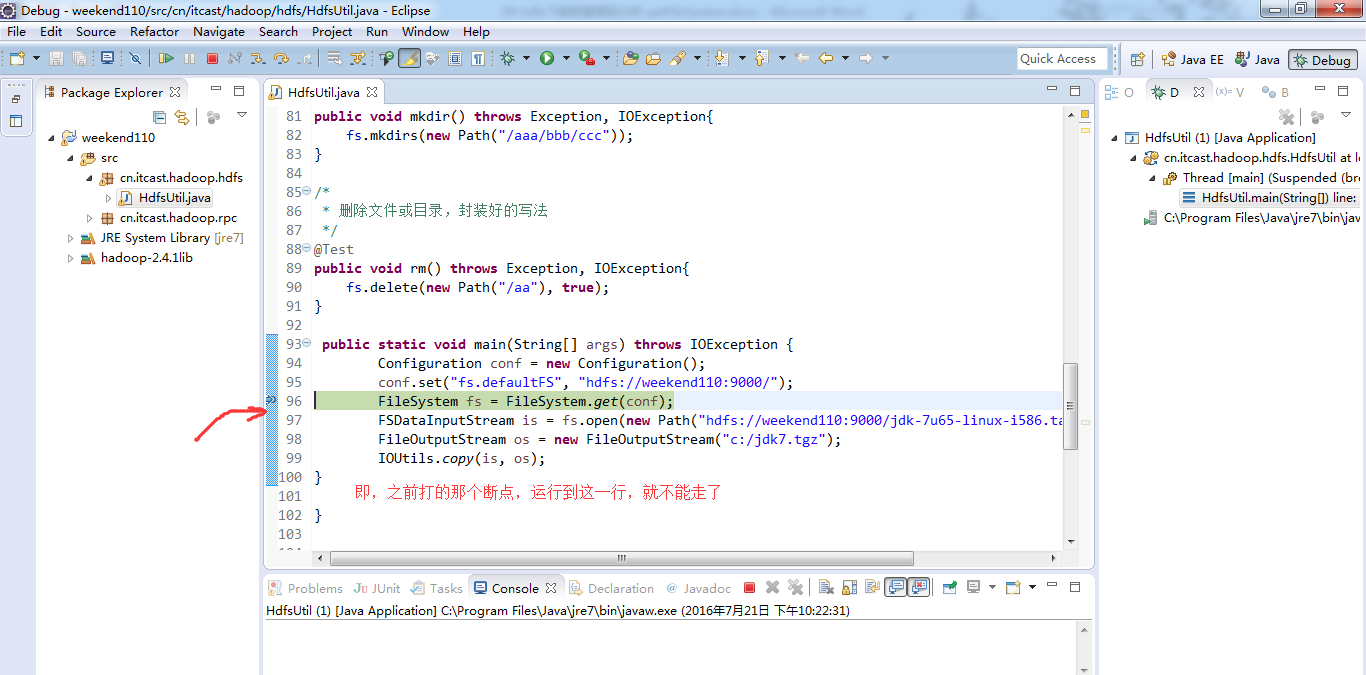
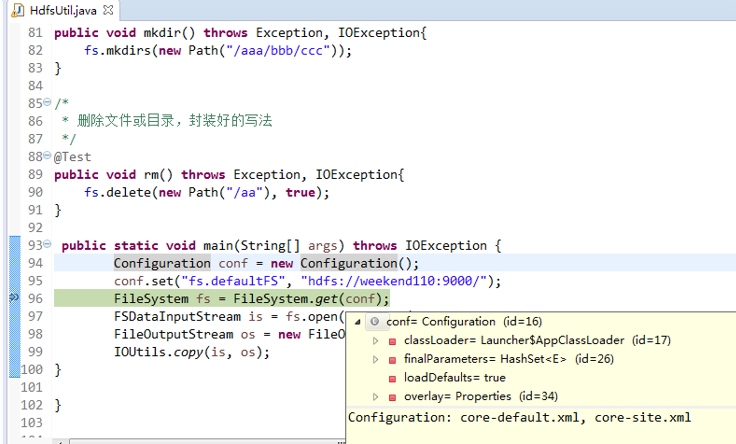
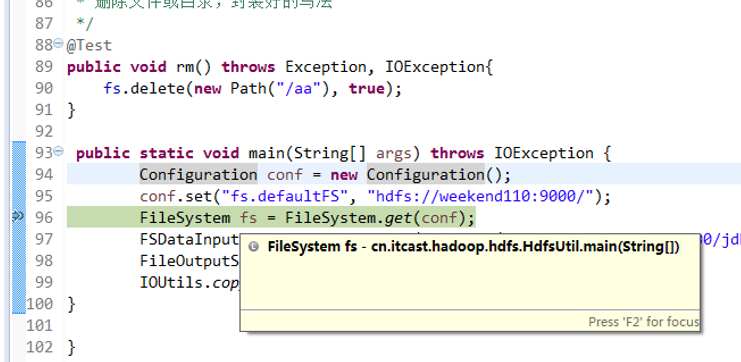
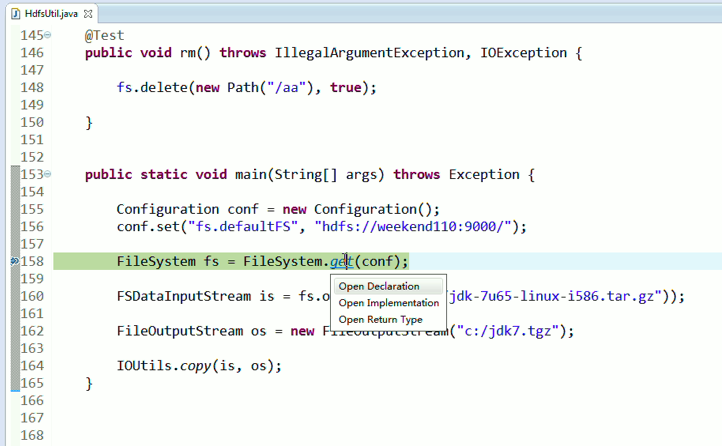
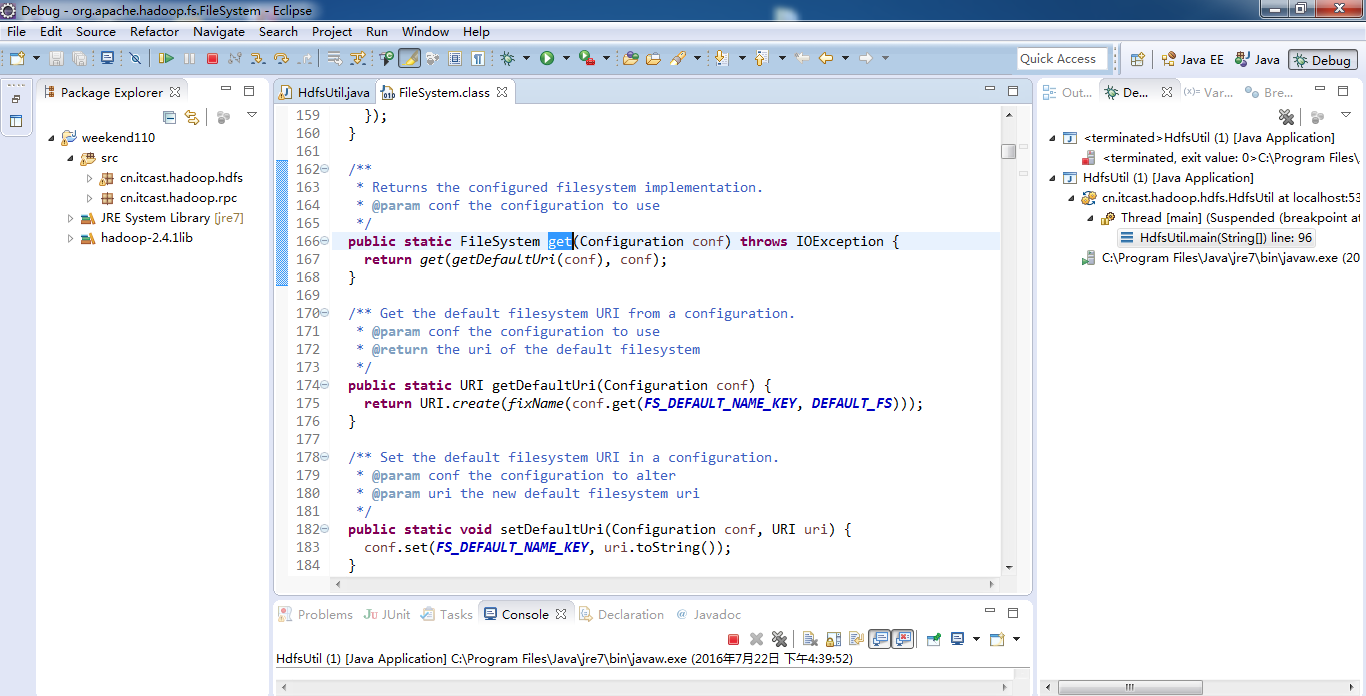
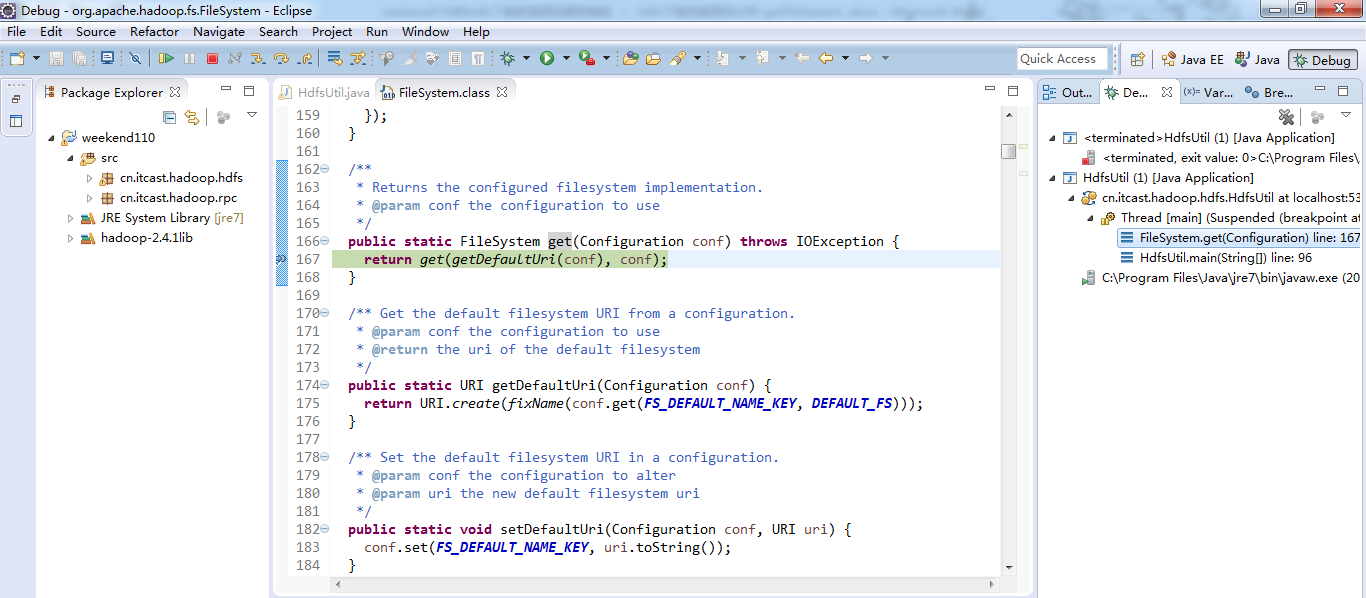

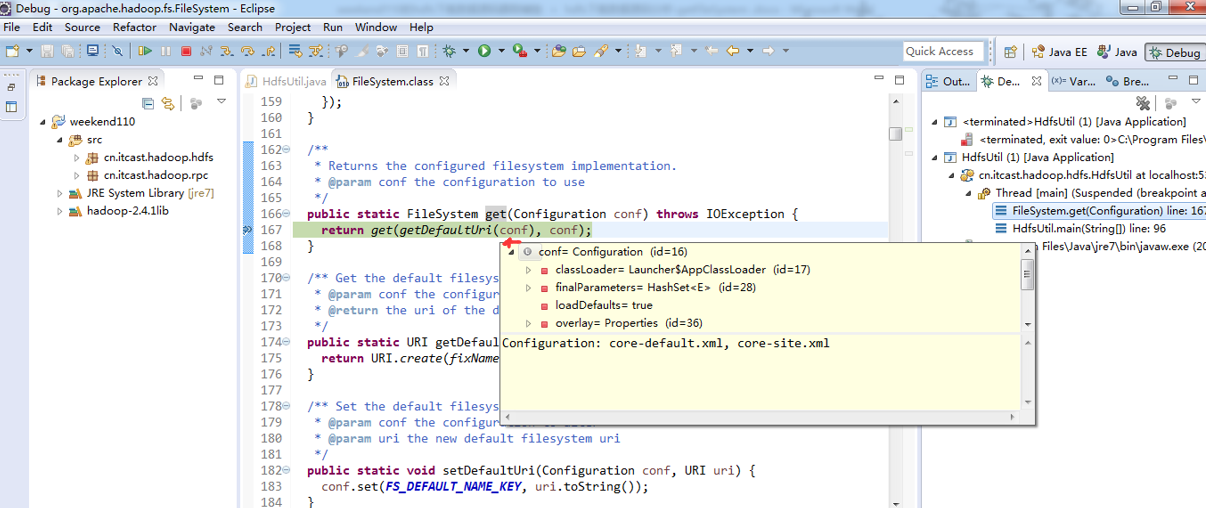
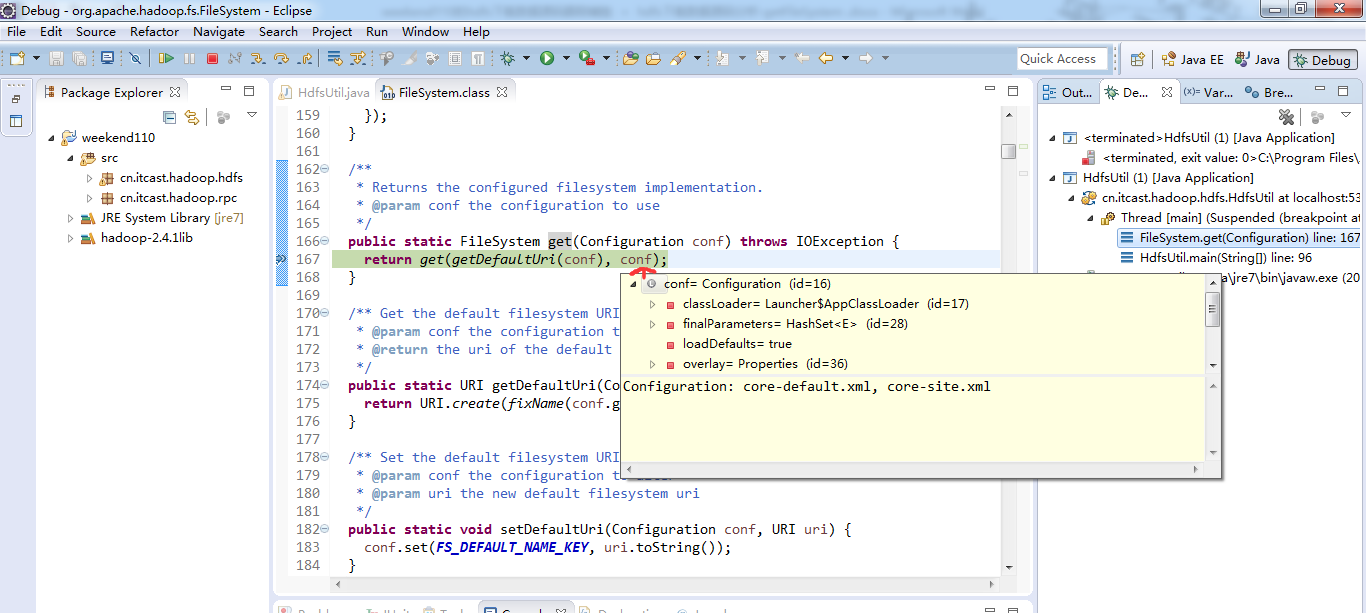
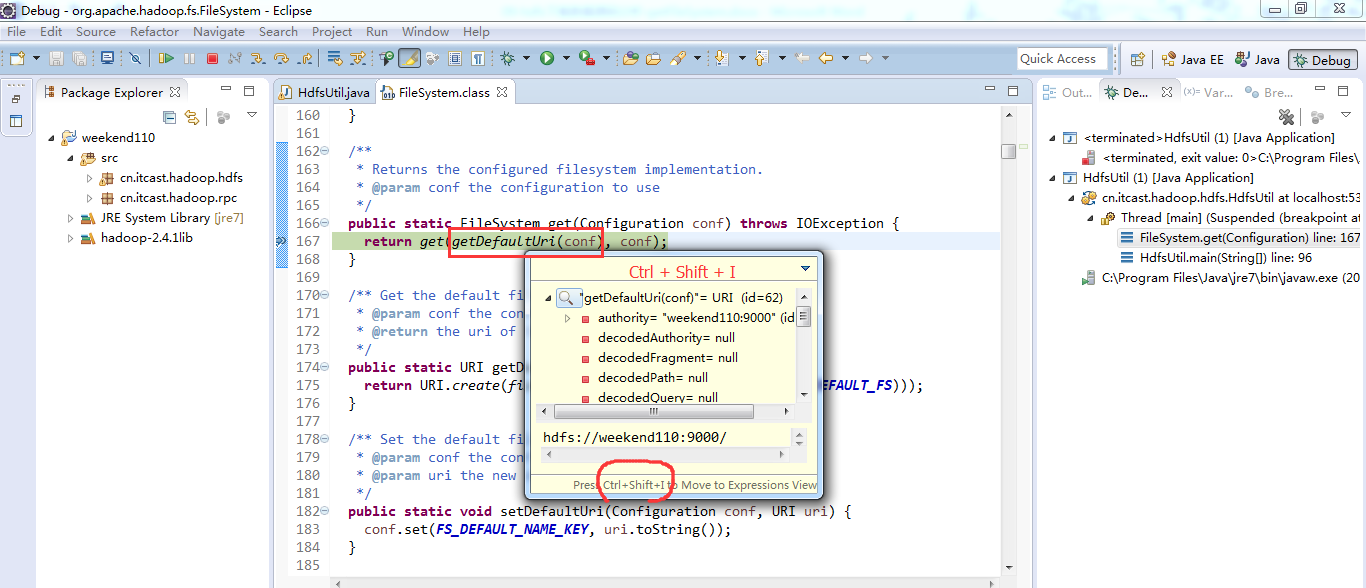
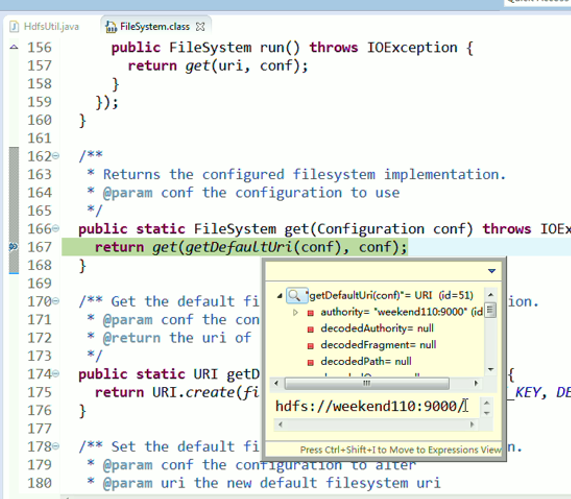
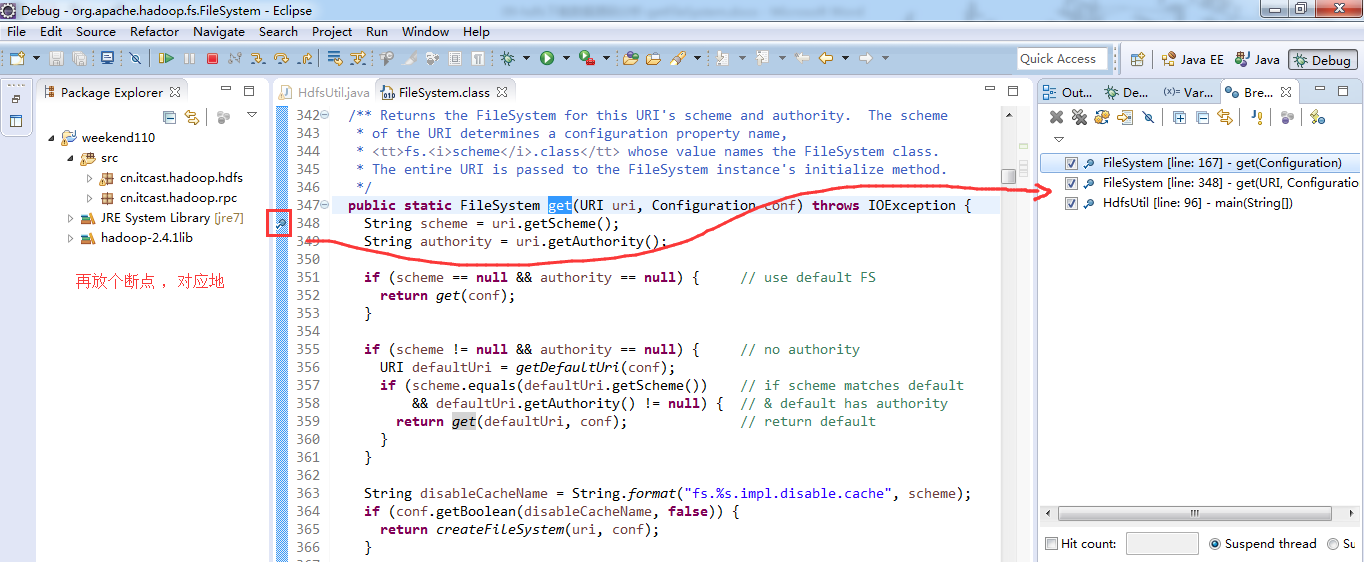

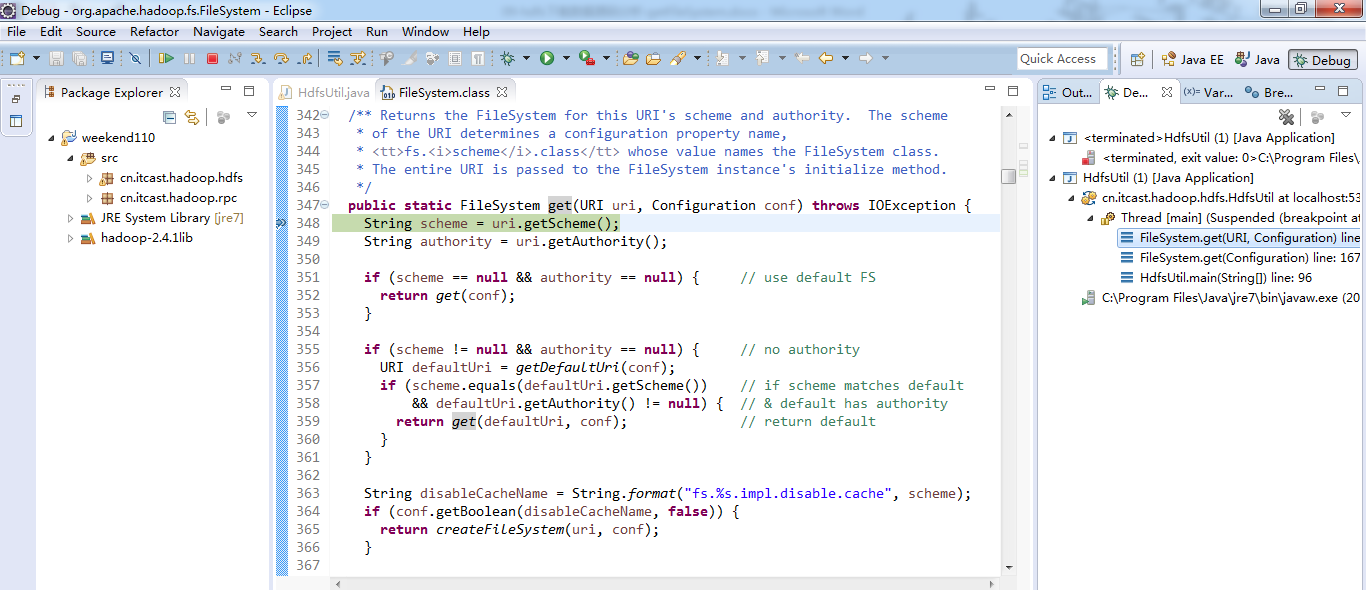
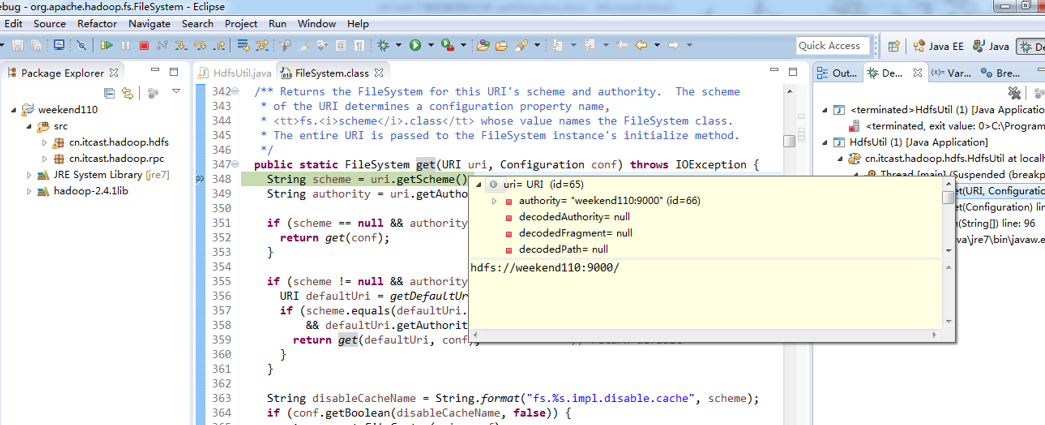
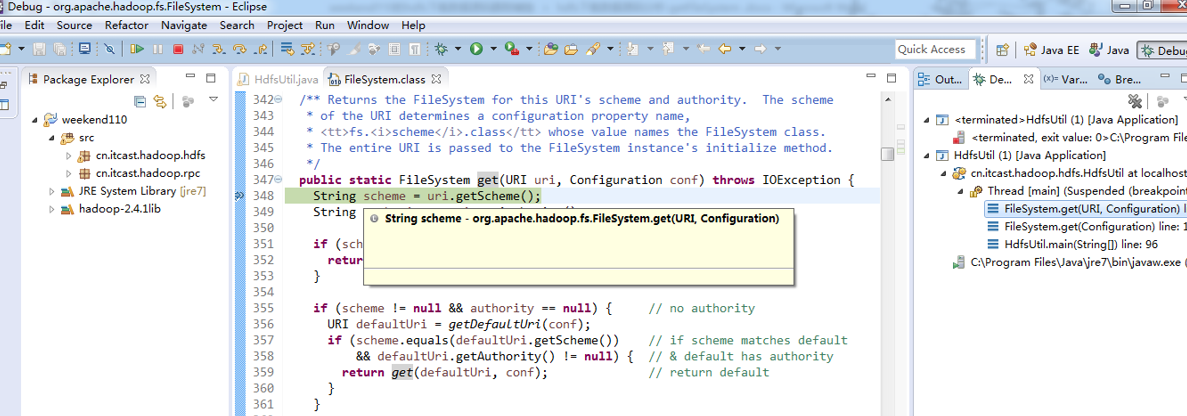
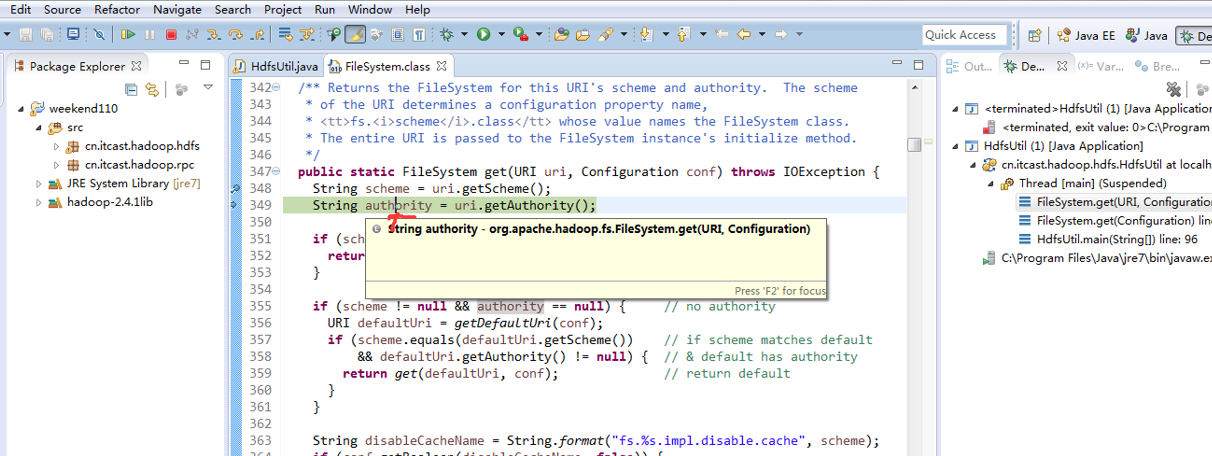
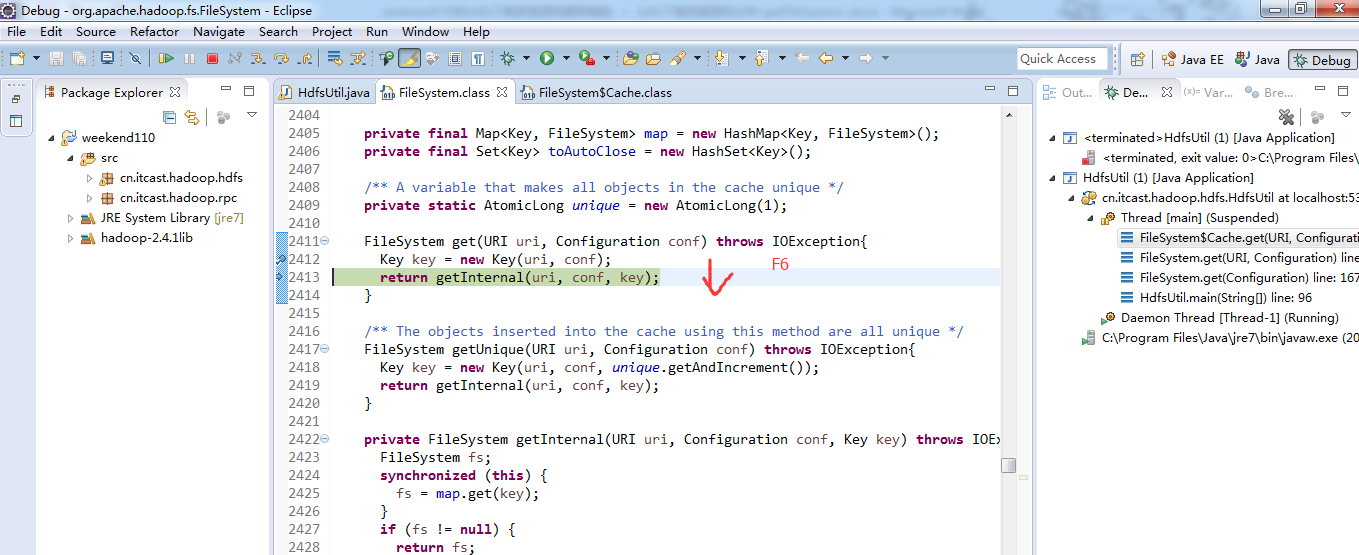
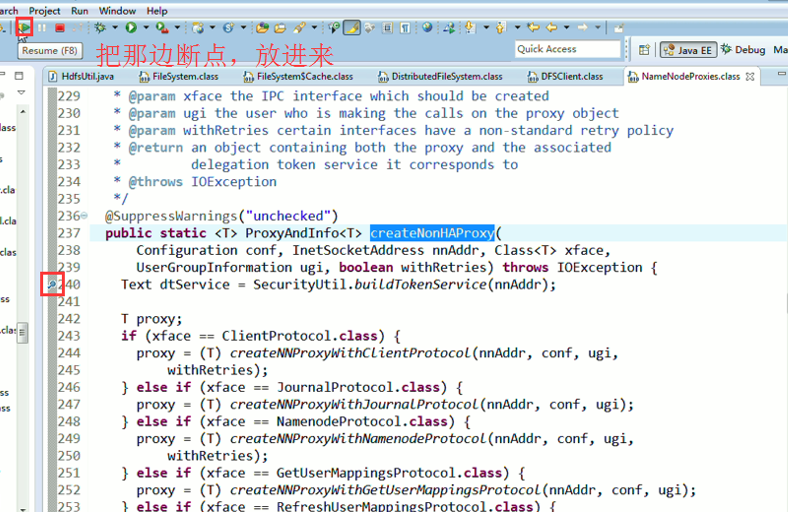
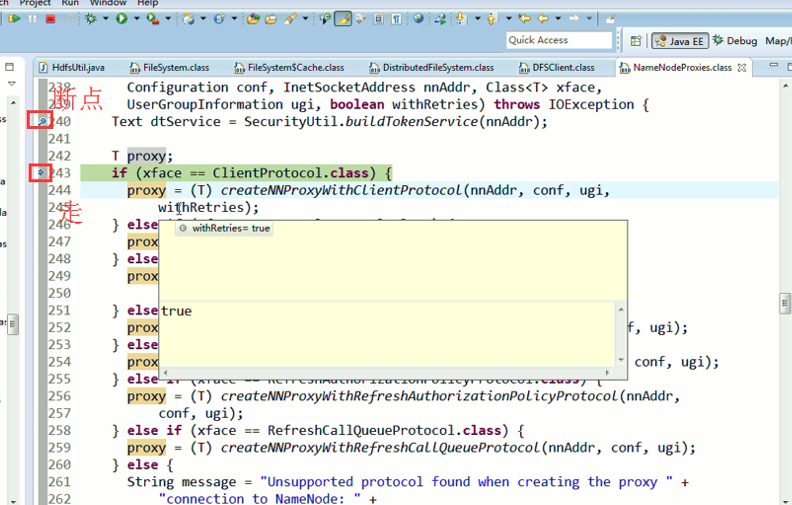
补充知识,F5是跳入方法,F6是向下逐行调试,F7是跳出方法,F8是直接跳转到下一个断点。


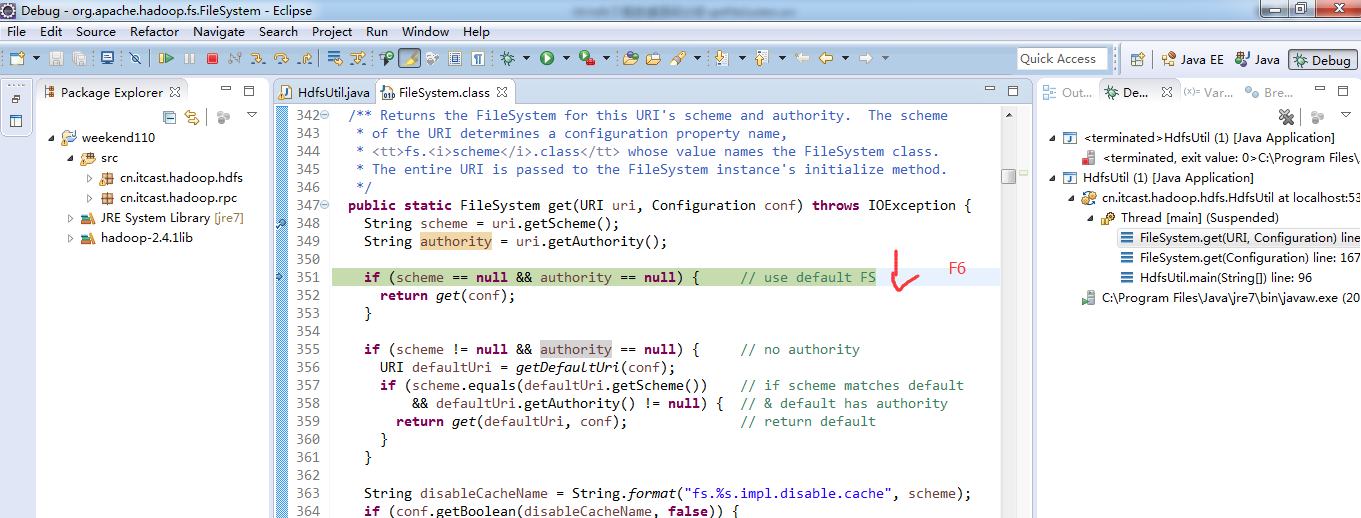

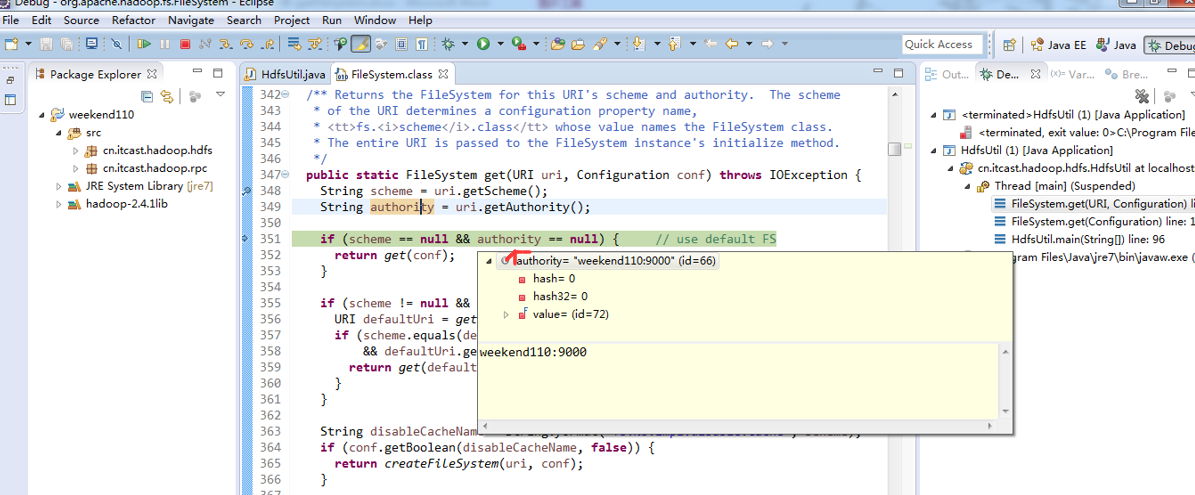
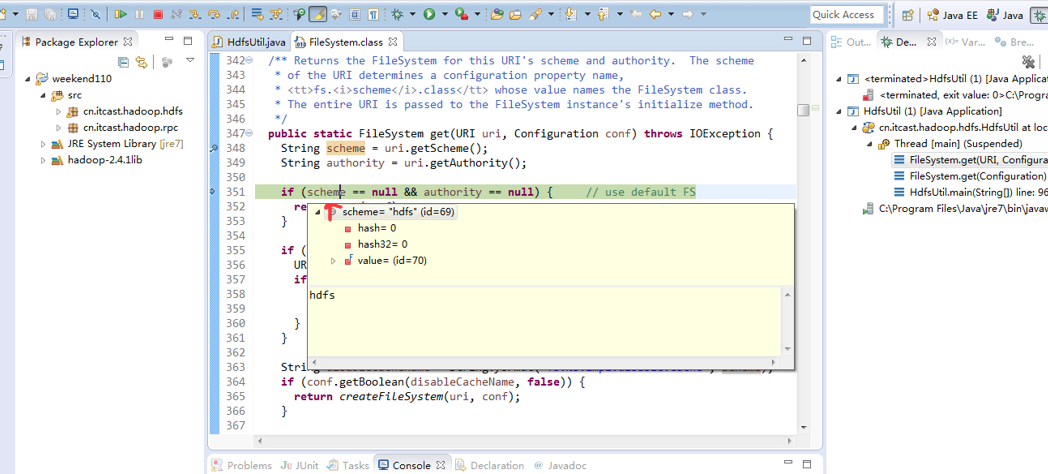
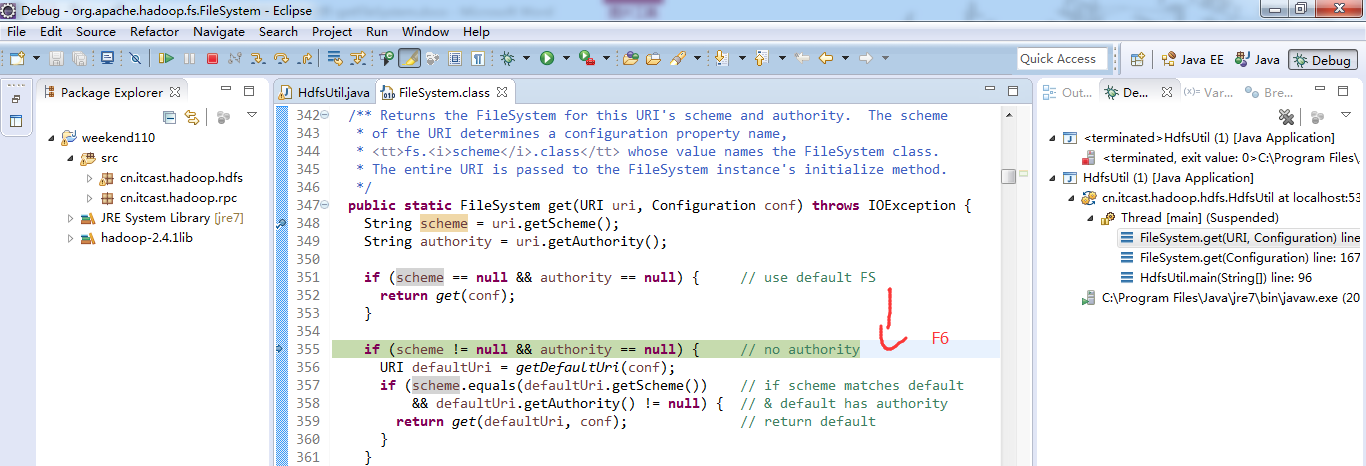
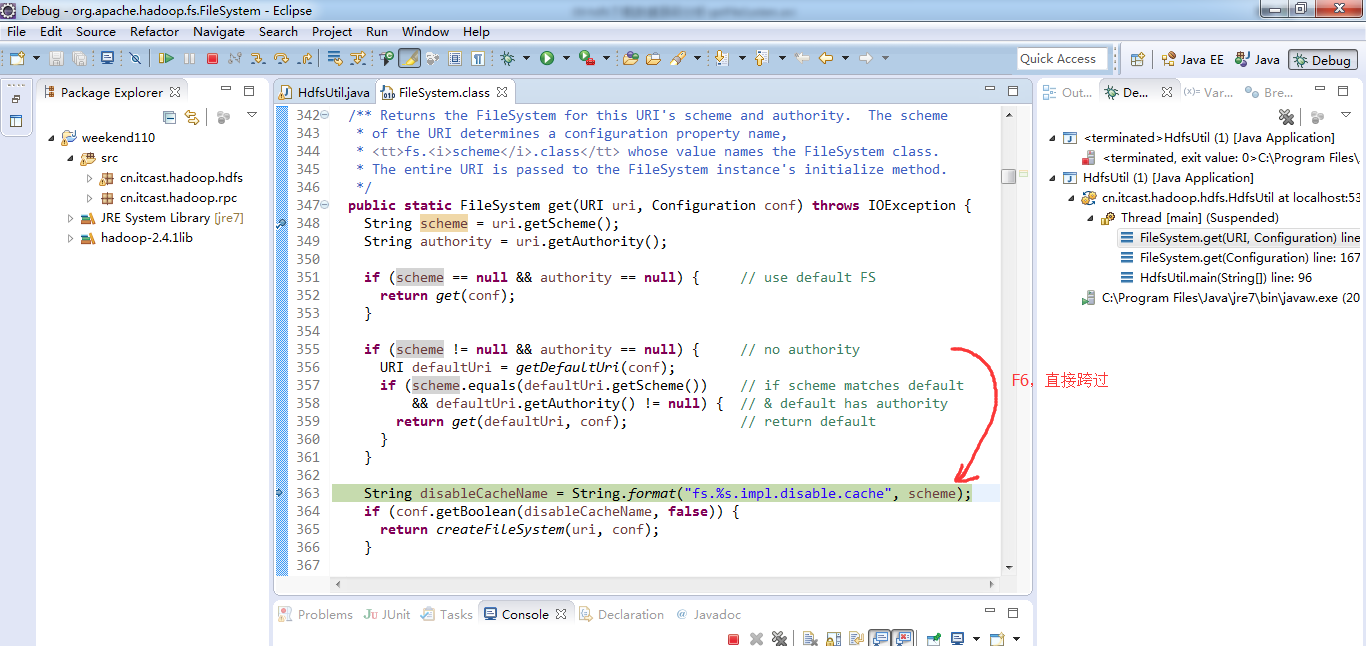
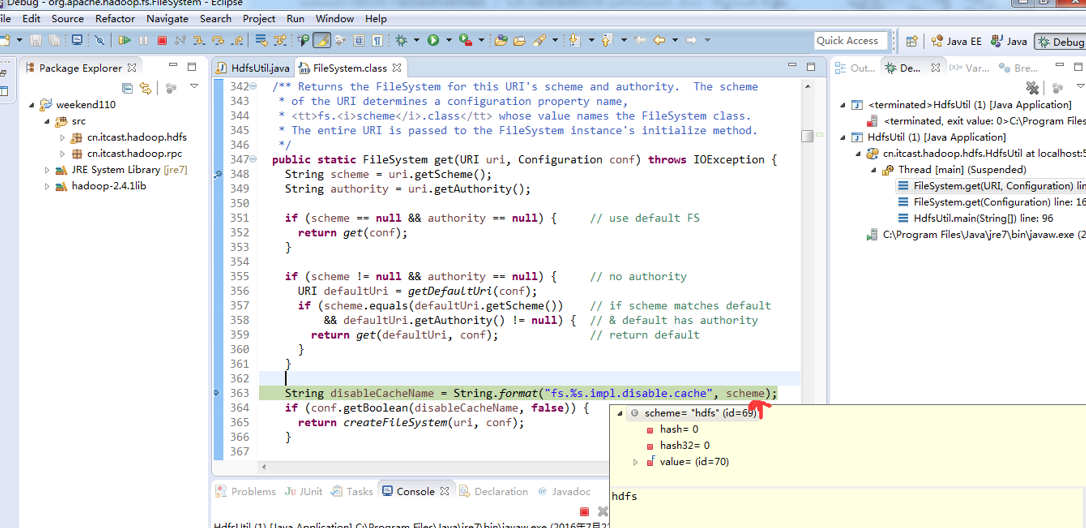
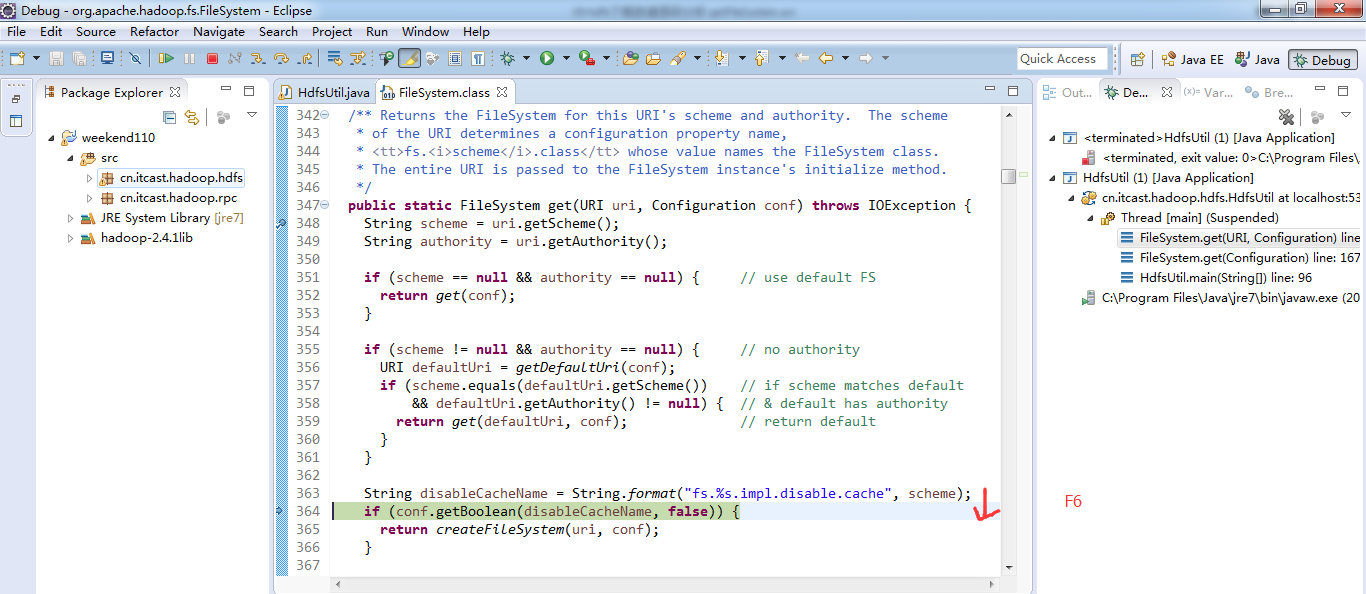


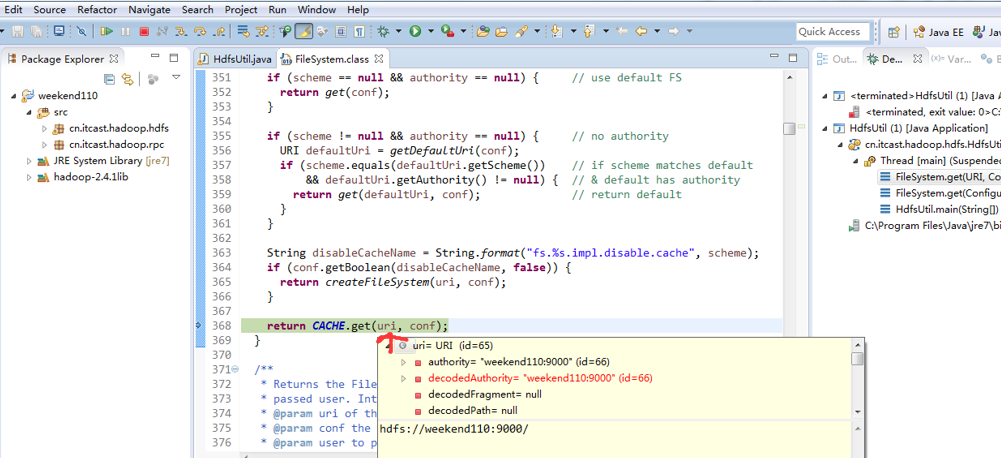
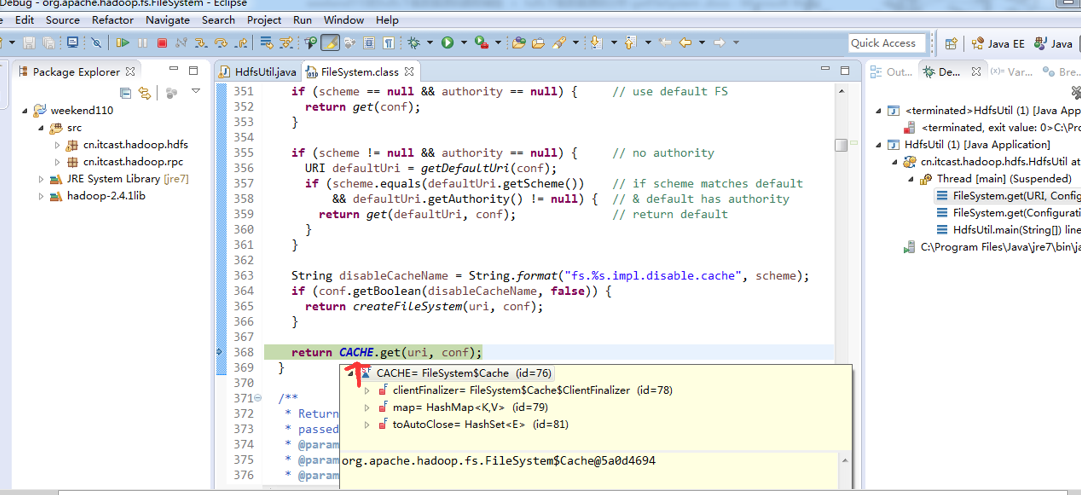

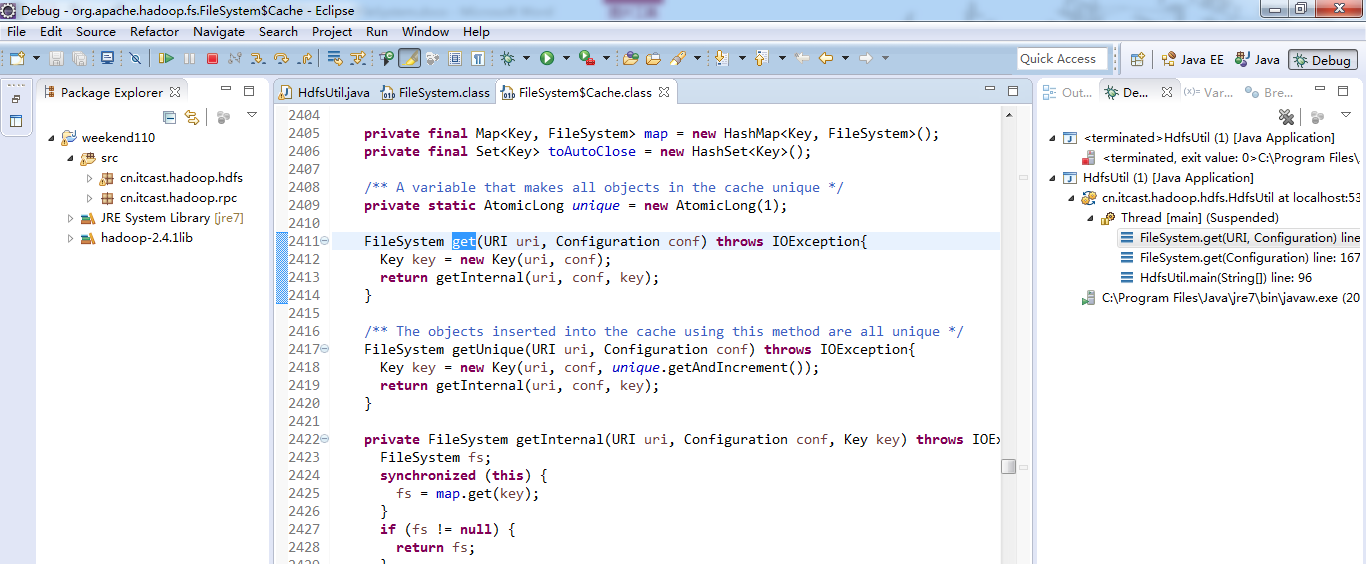

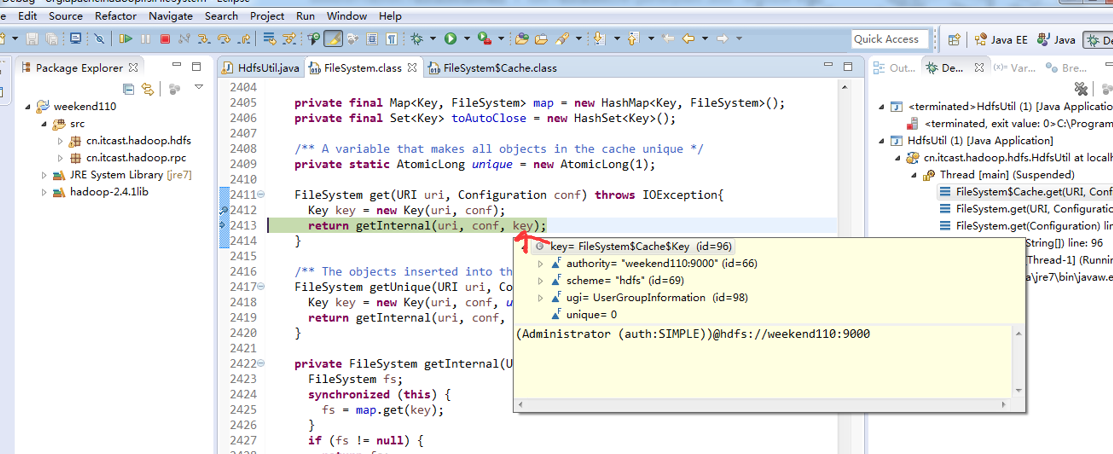
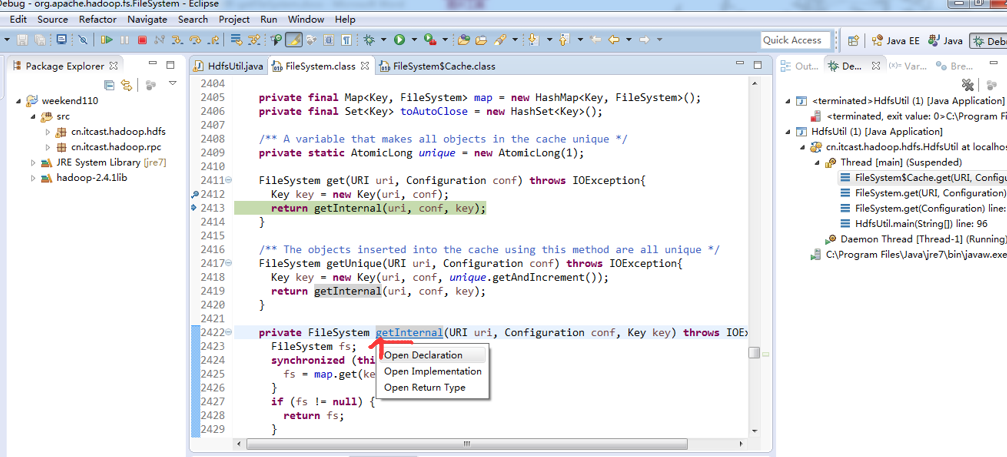
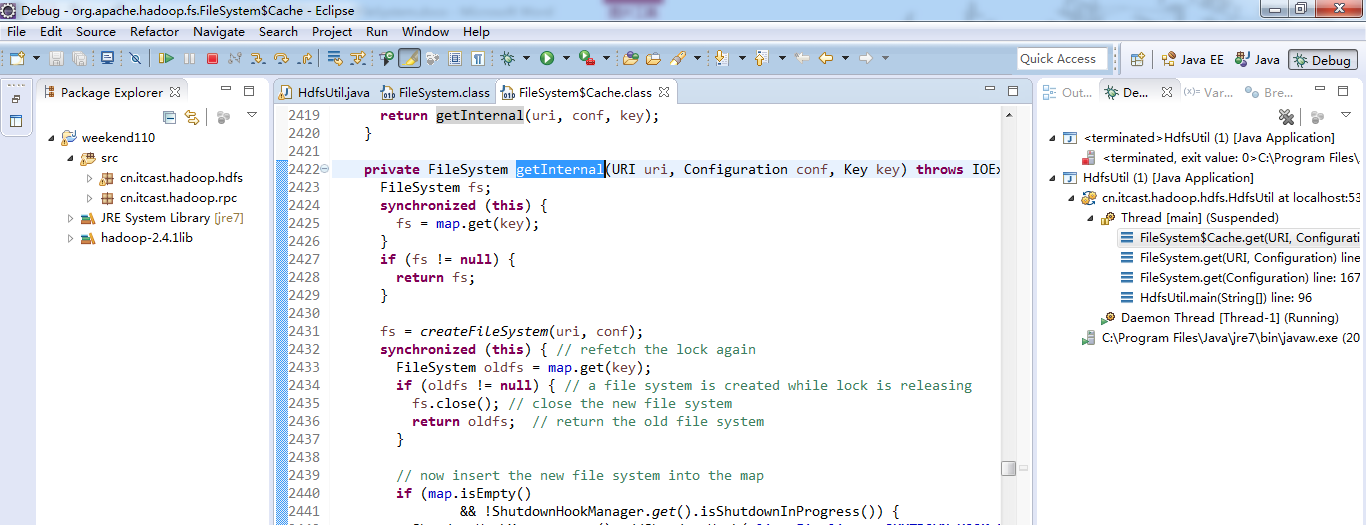
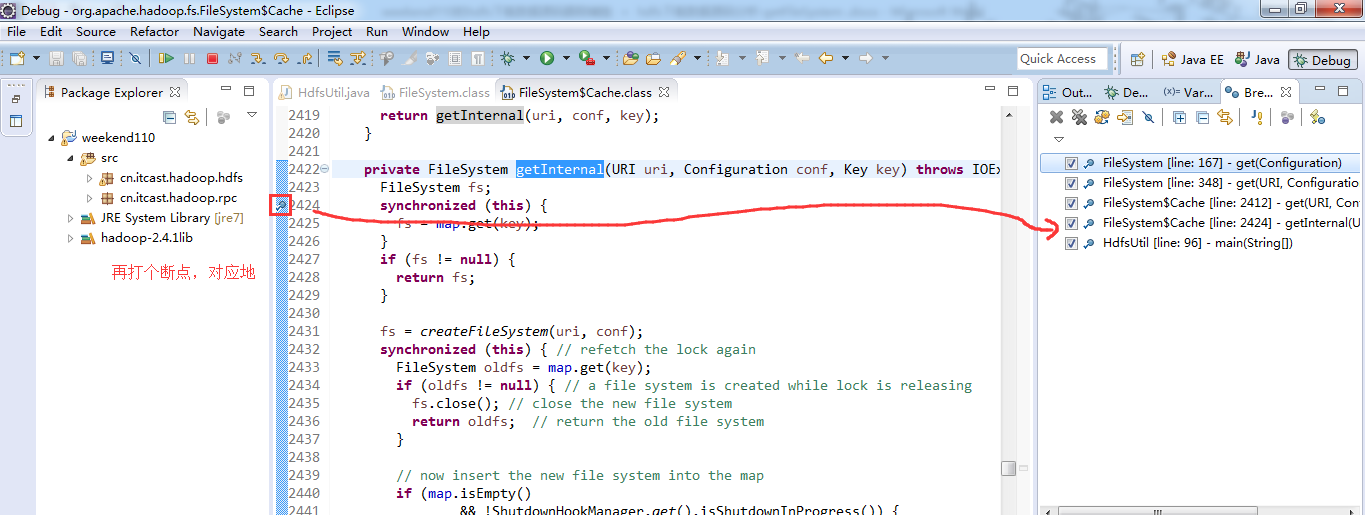
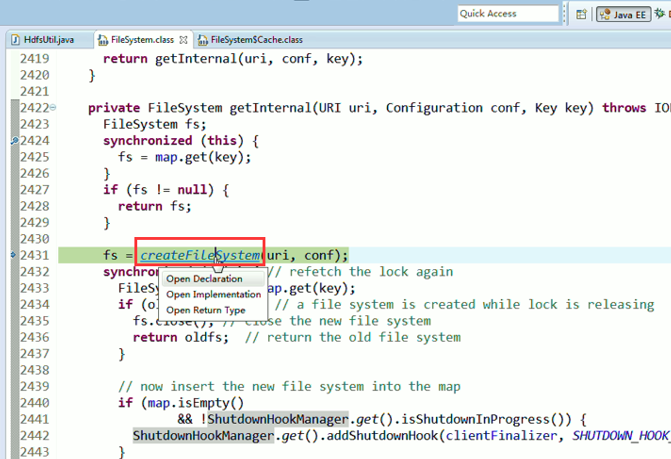
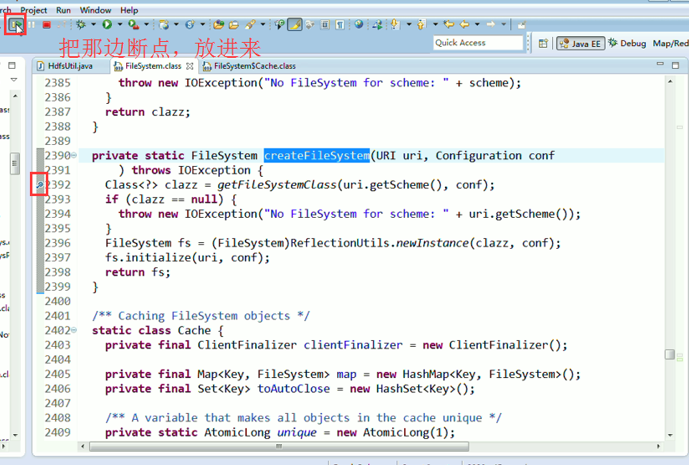
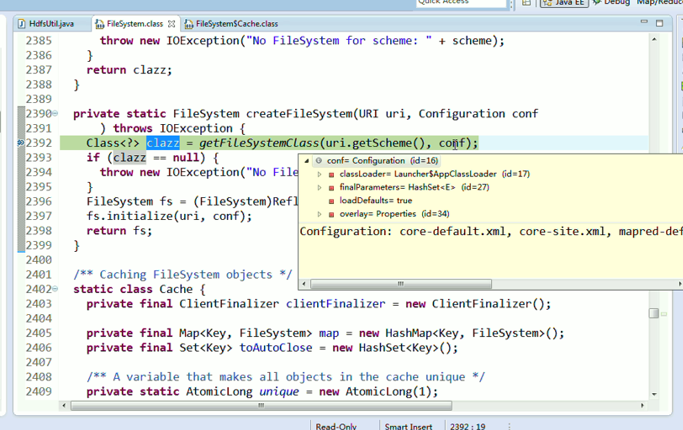
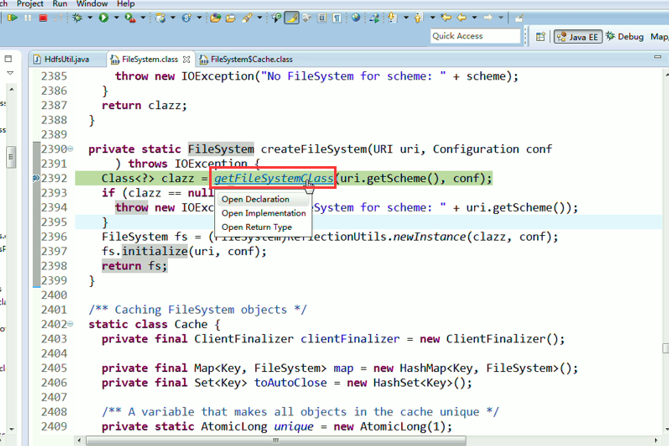

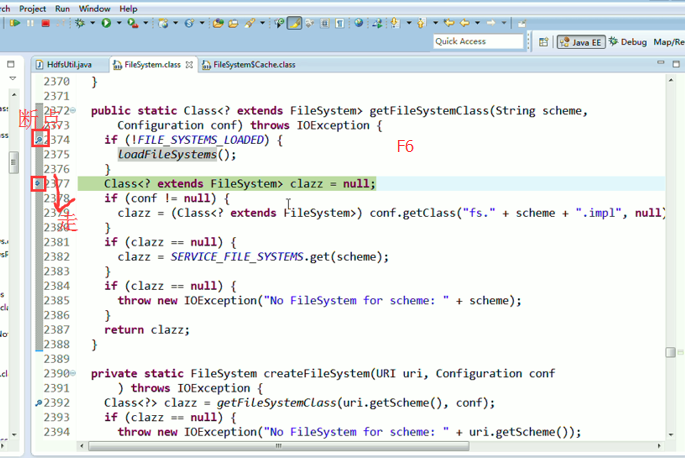



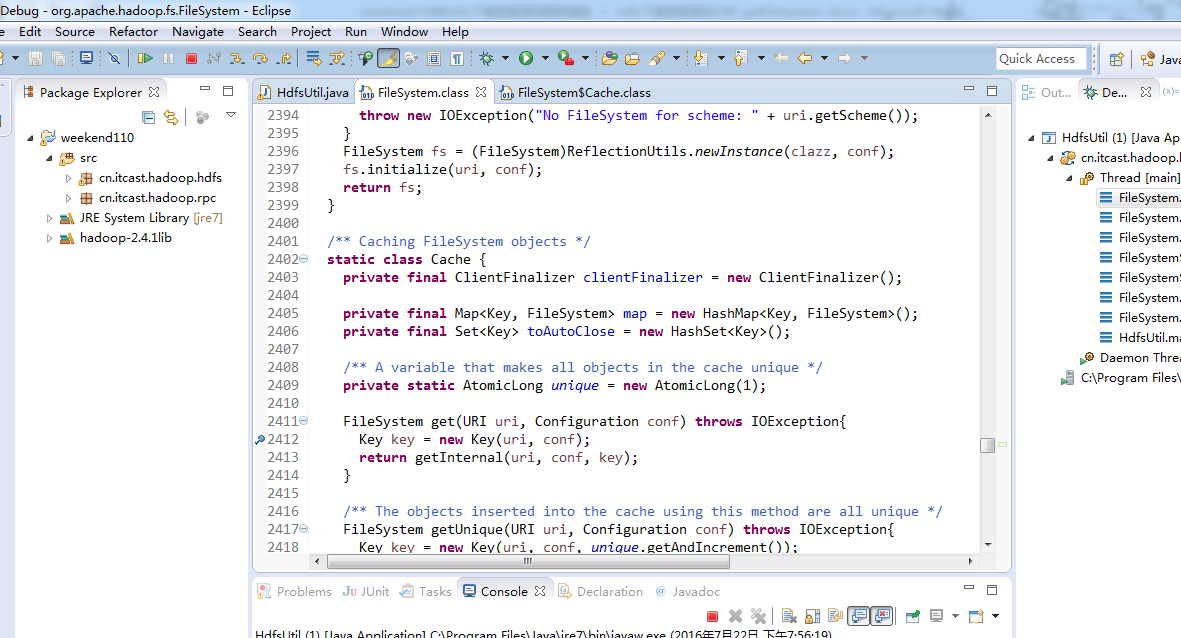




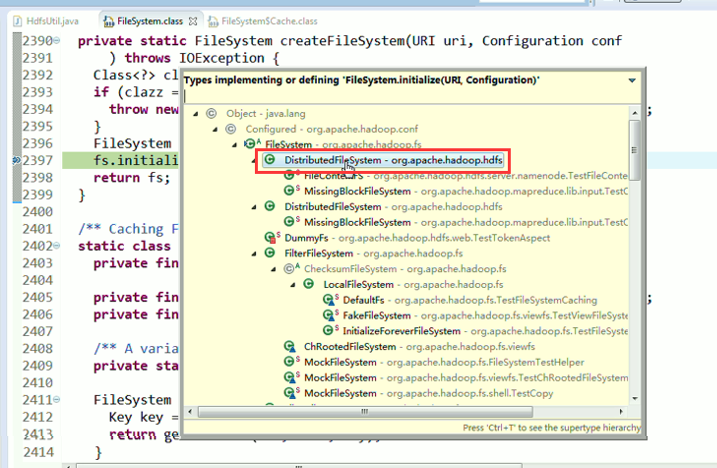
或者,Ctrl + T


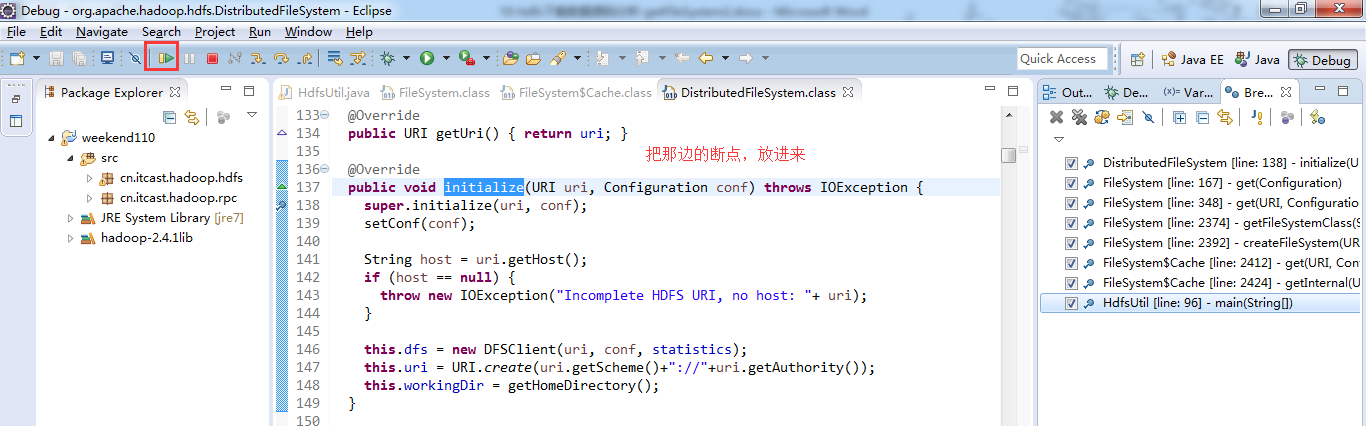
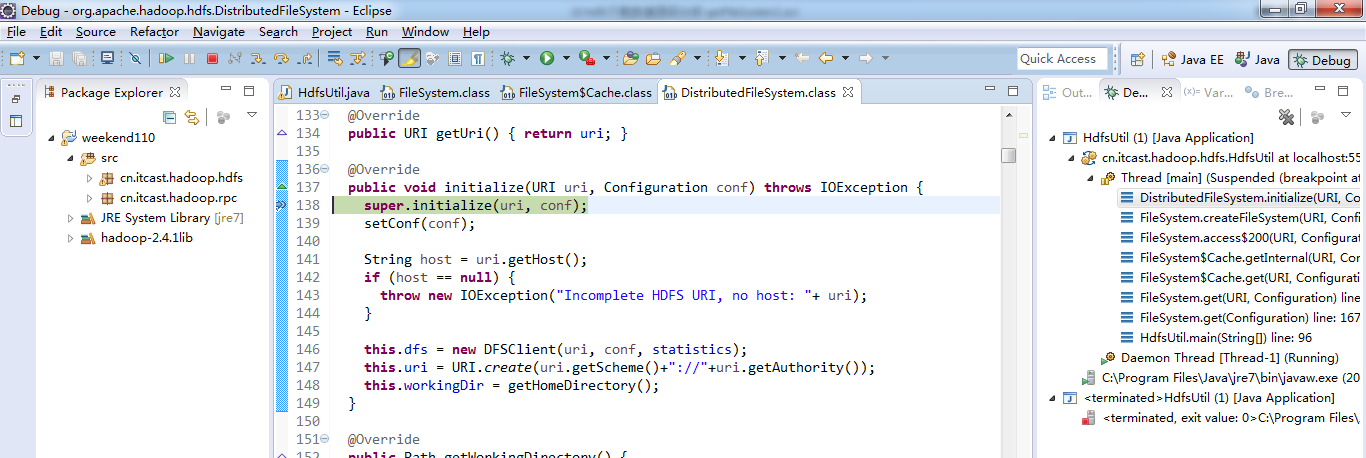

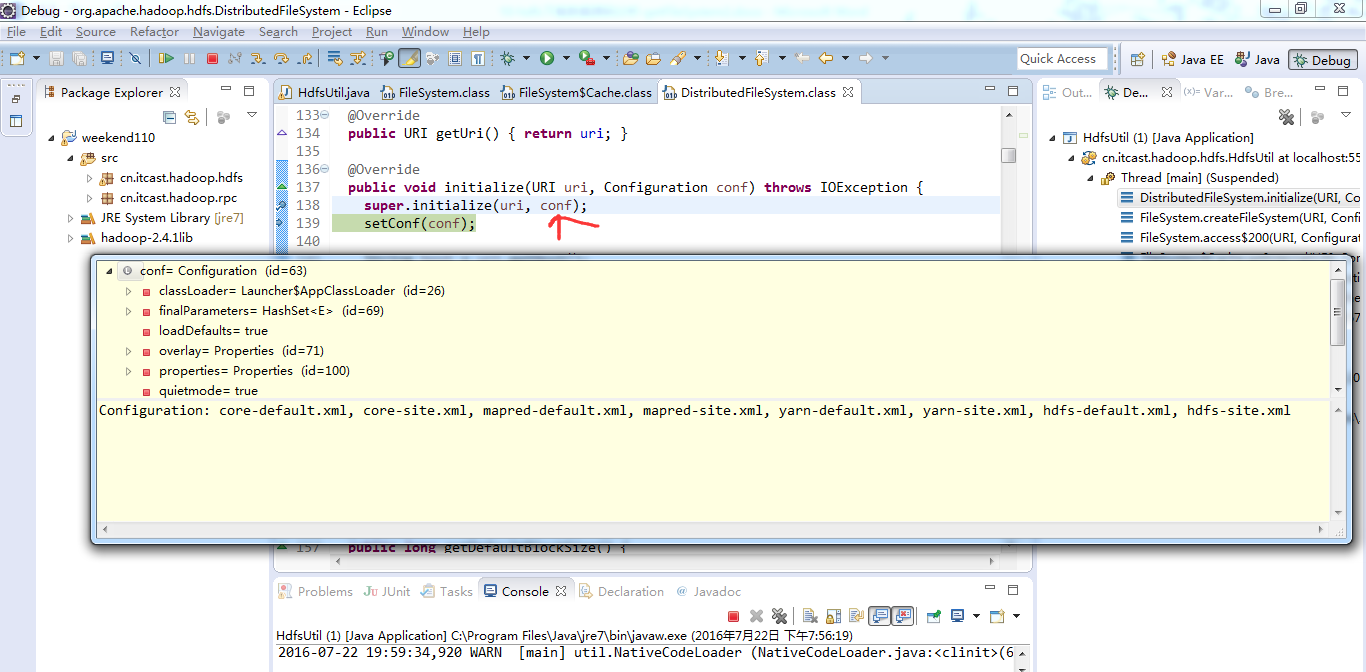
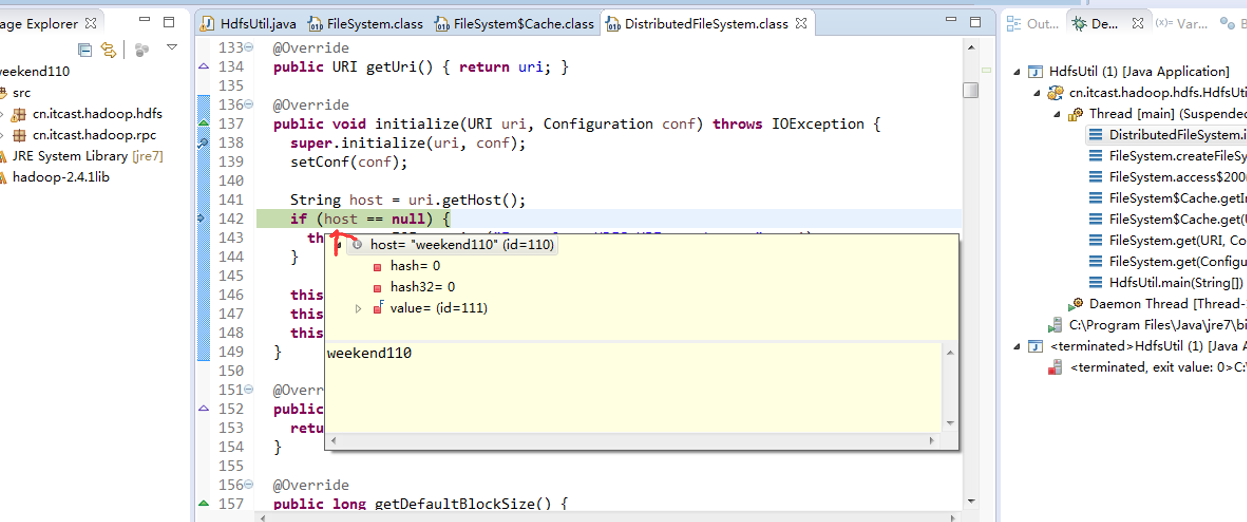



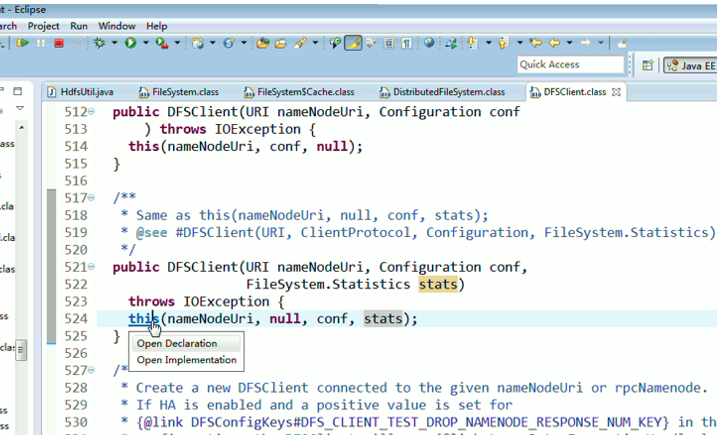

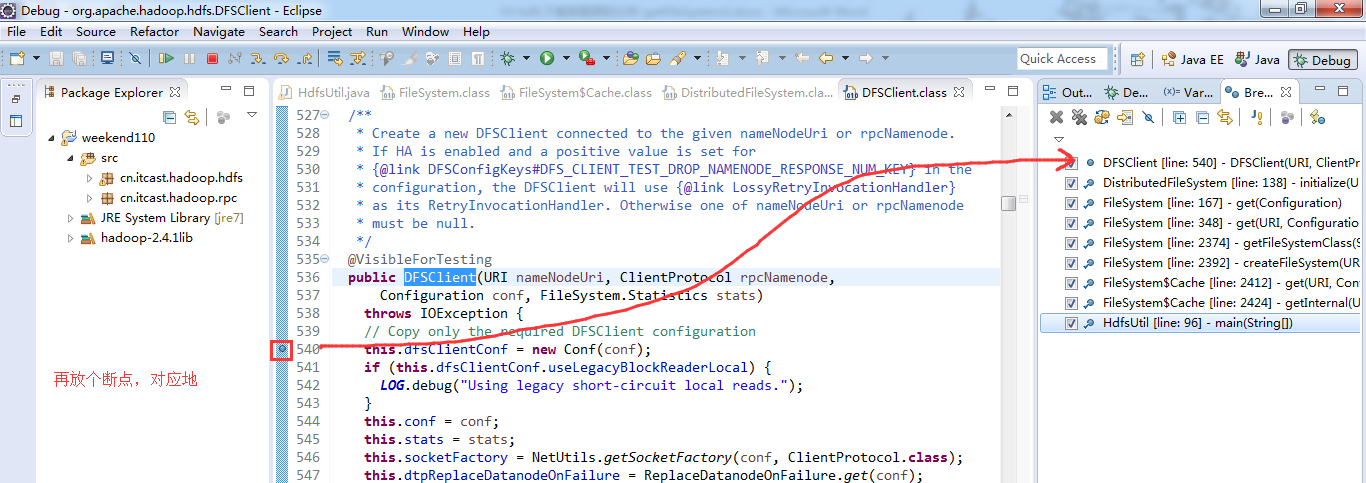


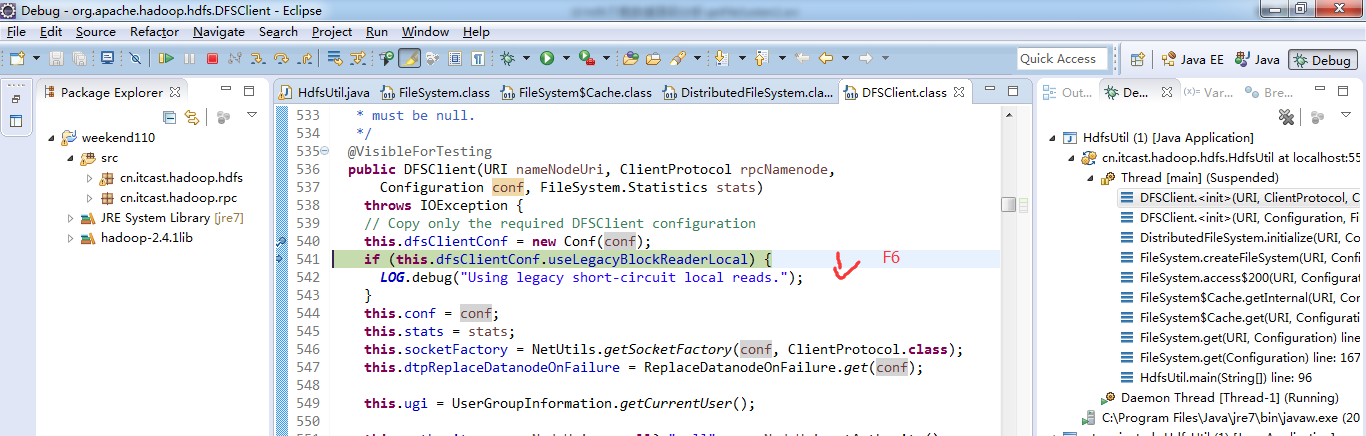
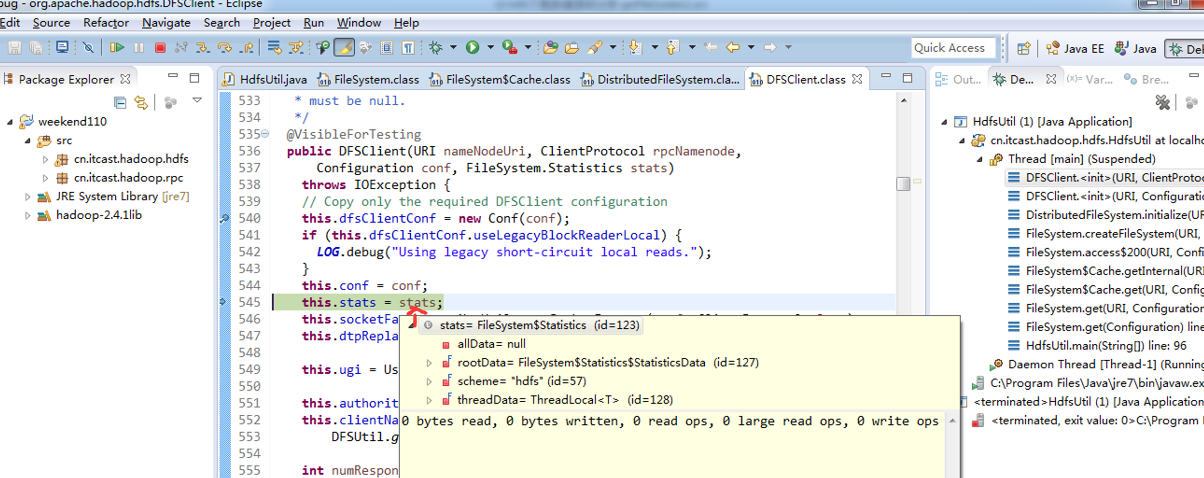

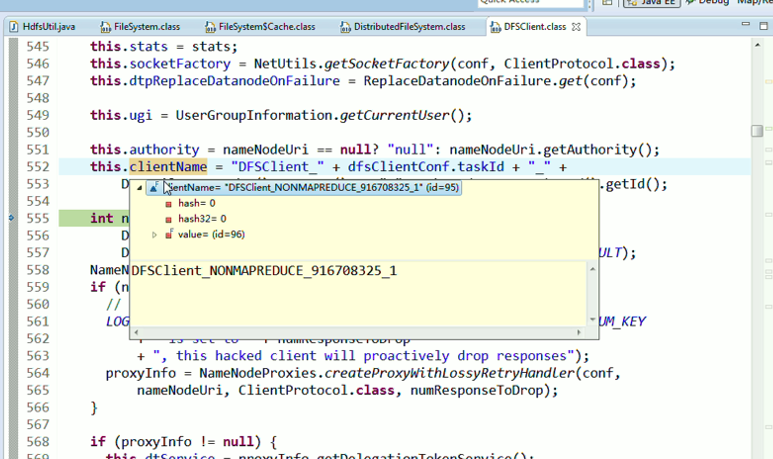
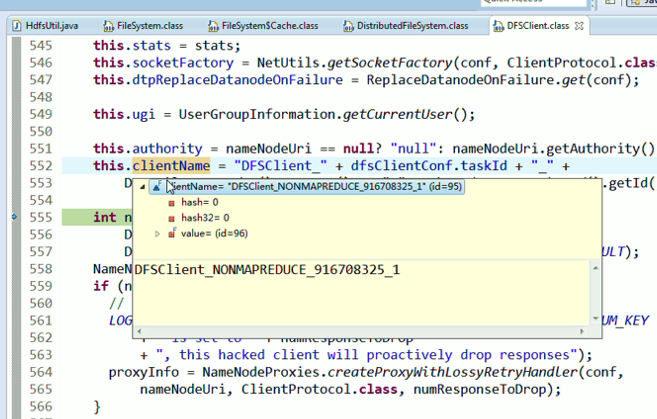
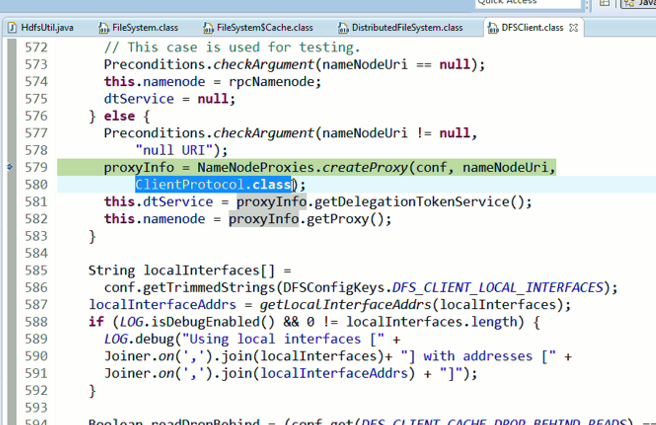
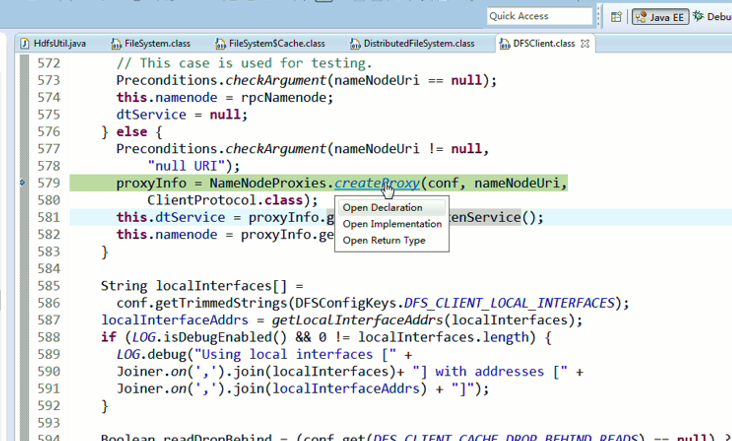
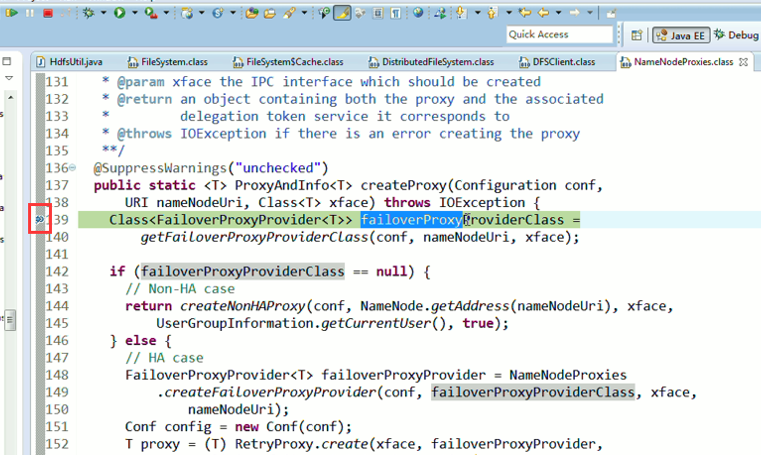
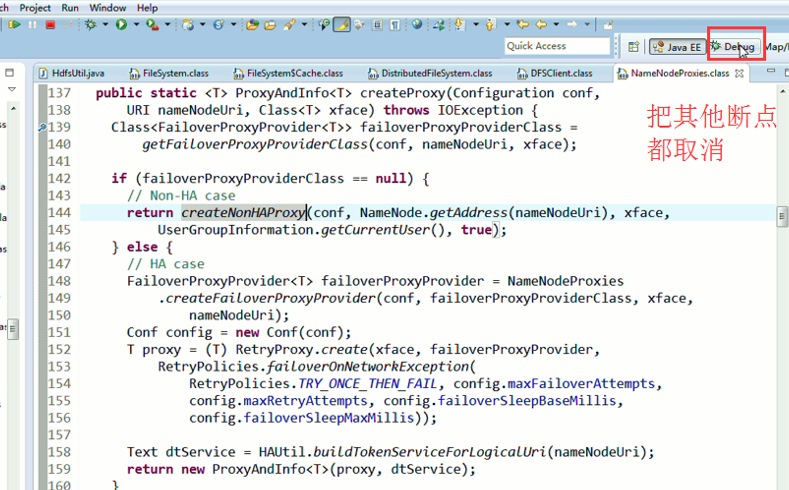
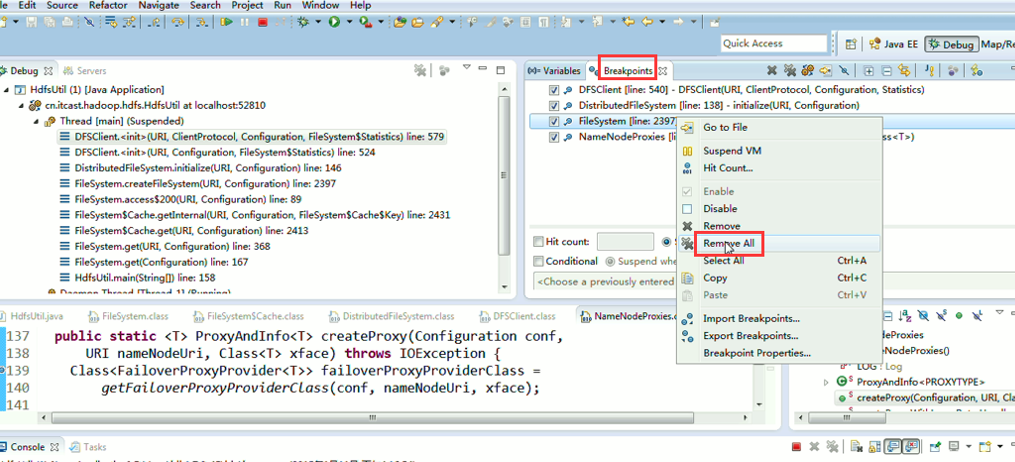
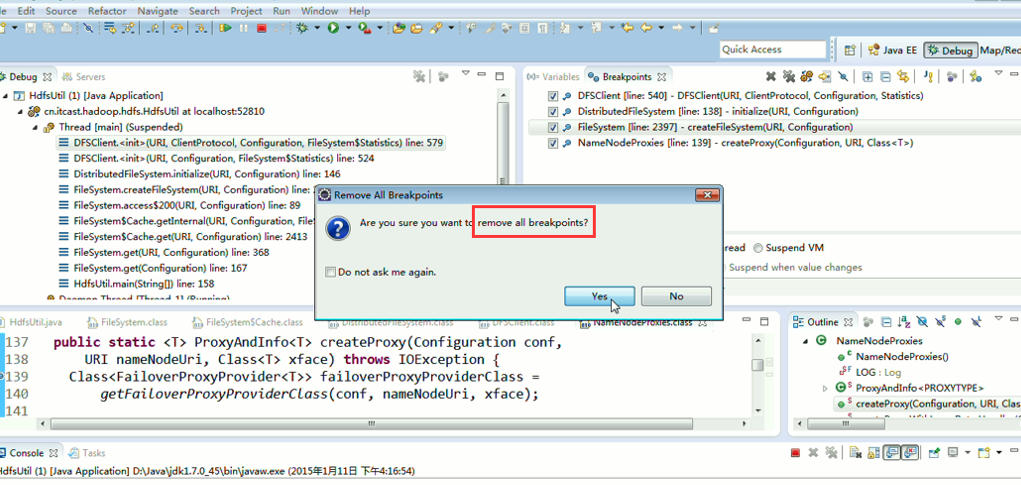
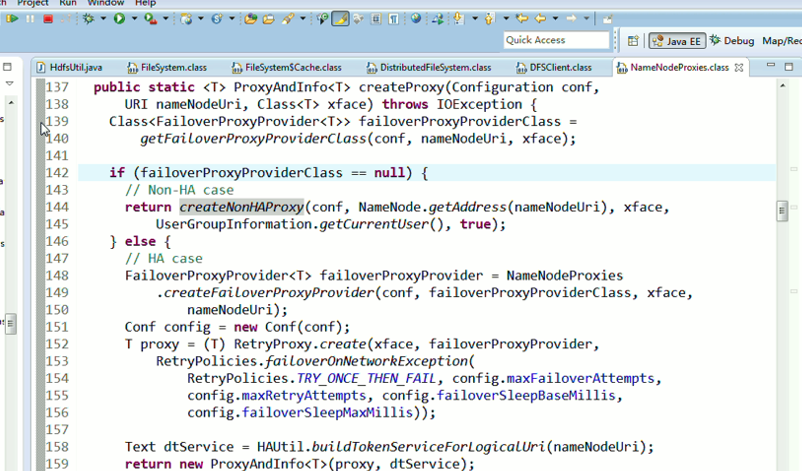
重新建立断点,

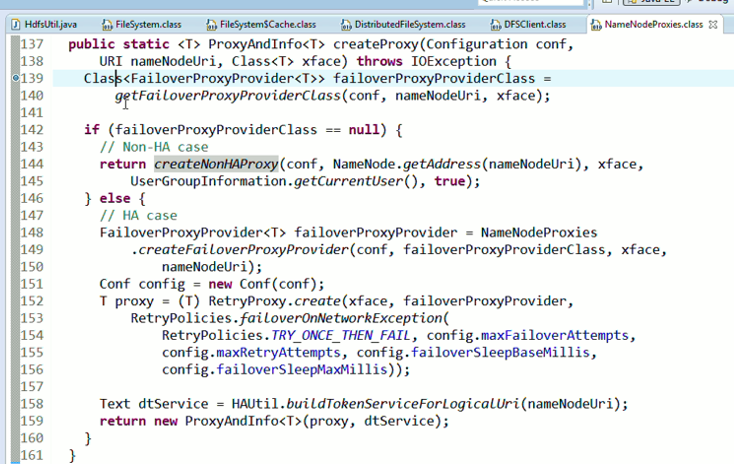
停下,然后,重新运行,到断点那,

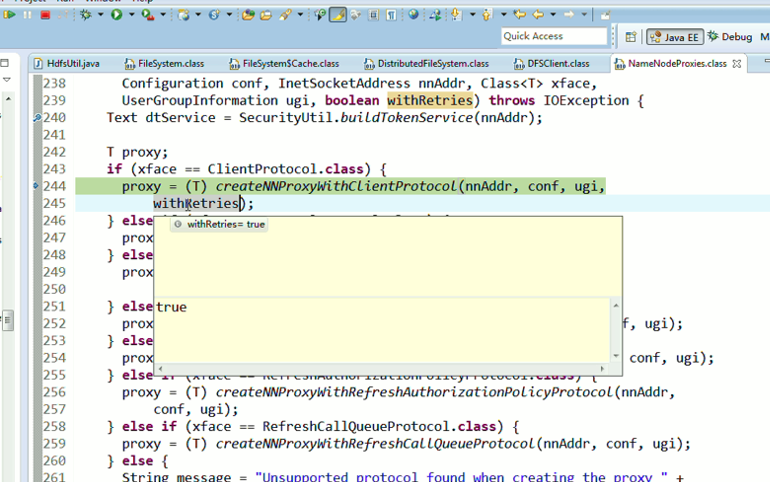
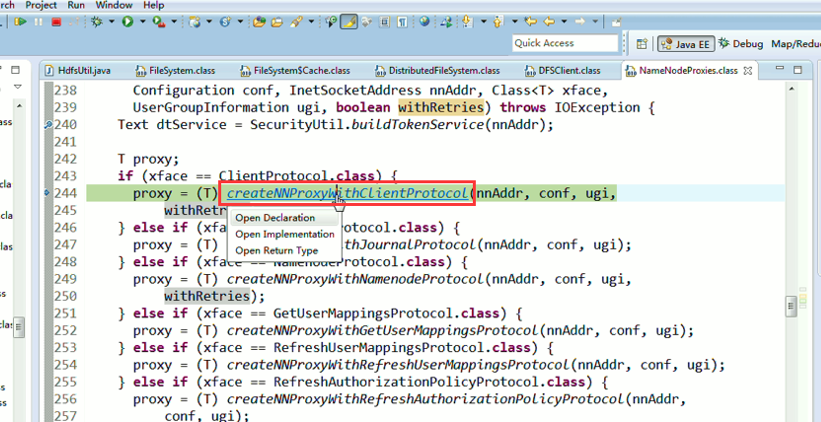
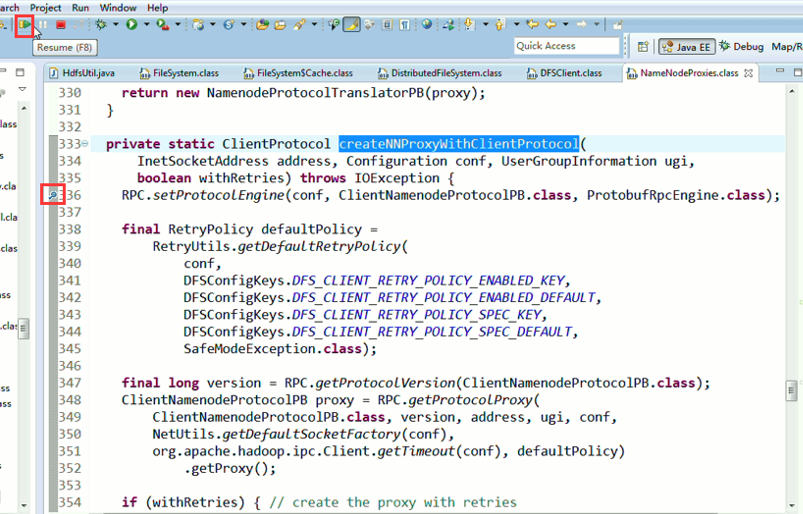
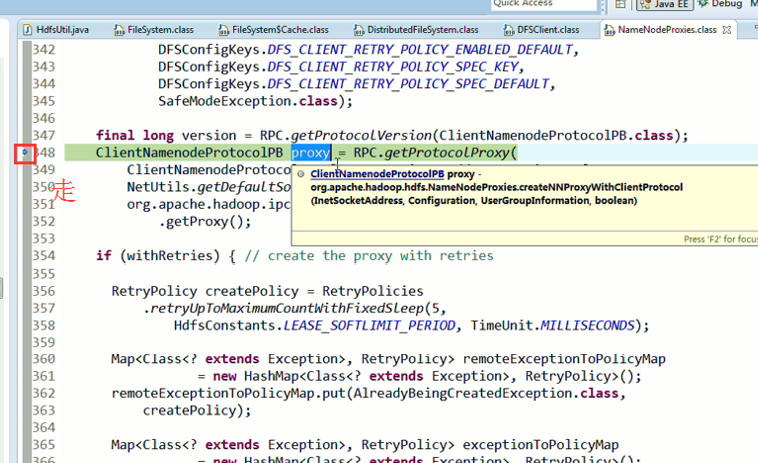

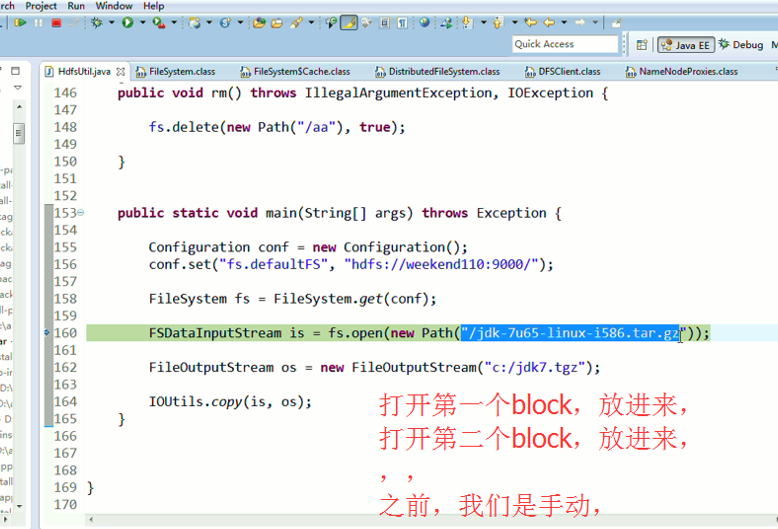
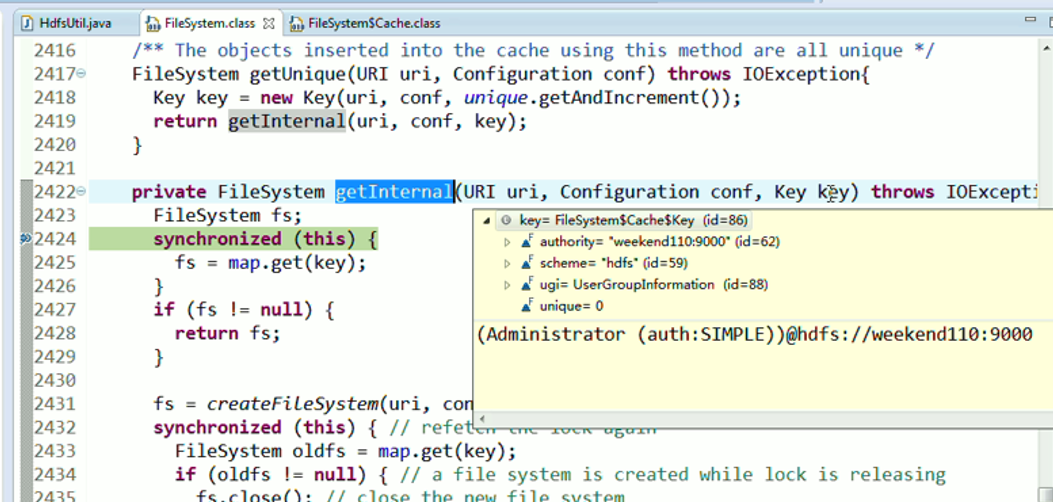
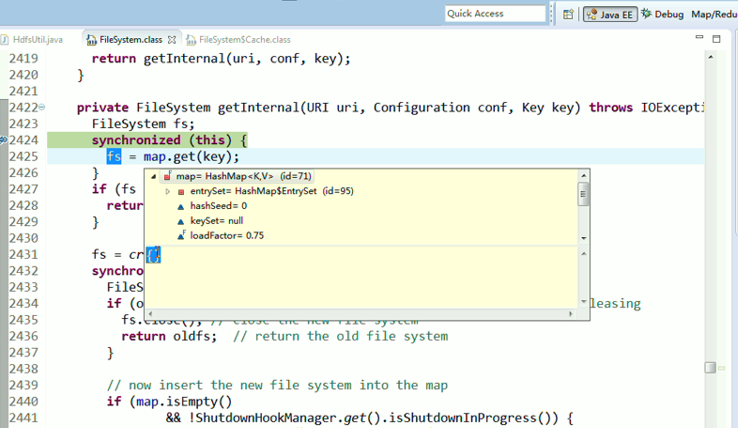
还记得如下吗,就是我们之前手动,
这里,我们试一下,
FSDataInputStream is = fs.open(new Path("hdfs://weekend110:9000/jdk-7u65-linux-i586.tar.gz"));
与,
FSDataInputStream is = fs.open(new Path("/jdk-7u65-linux-i586.tar.gz"));
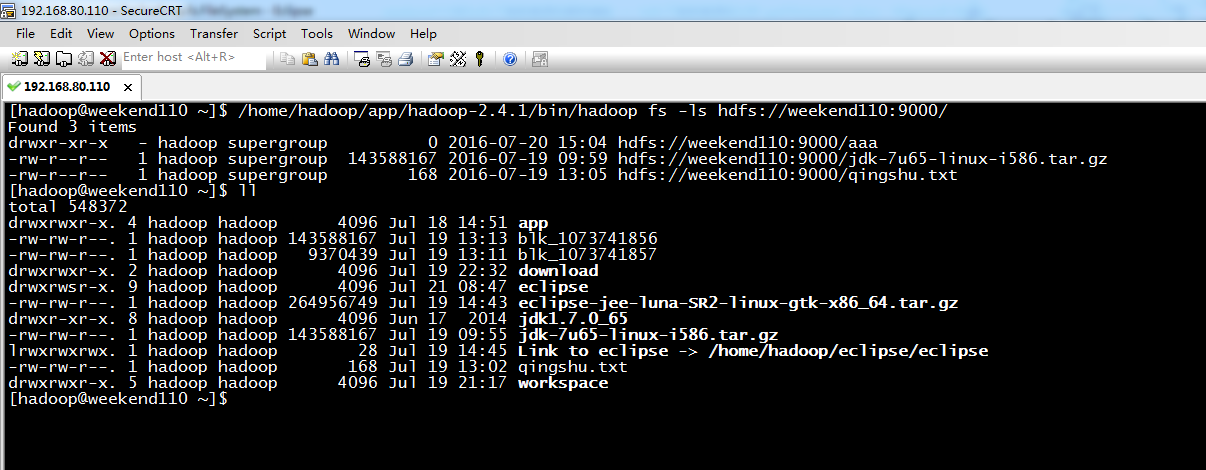
还记得如下吗,就是我们之前手动,

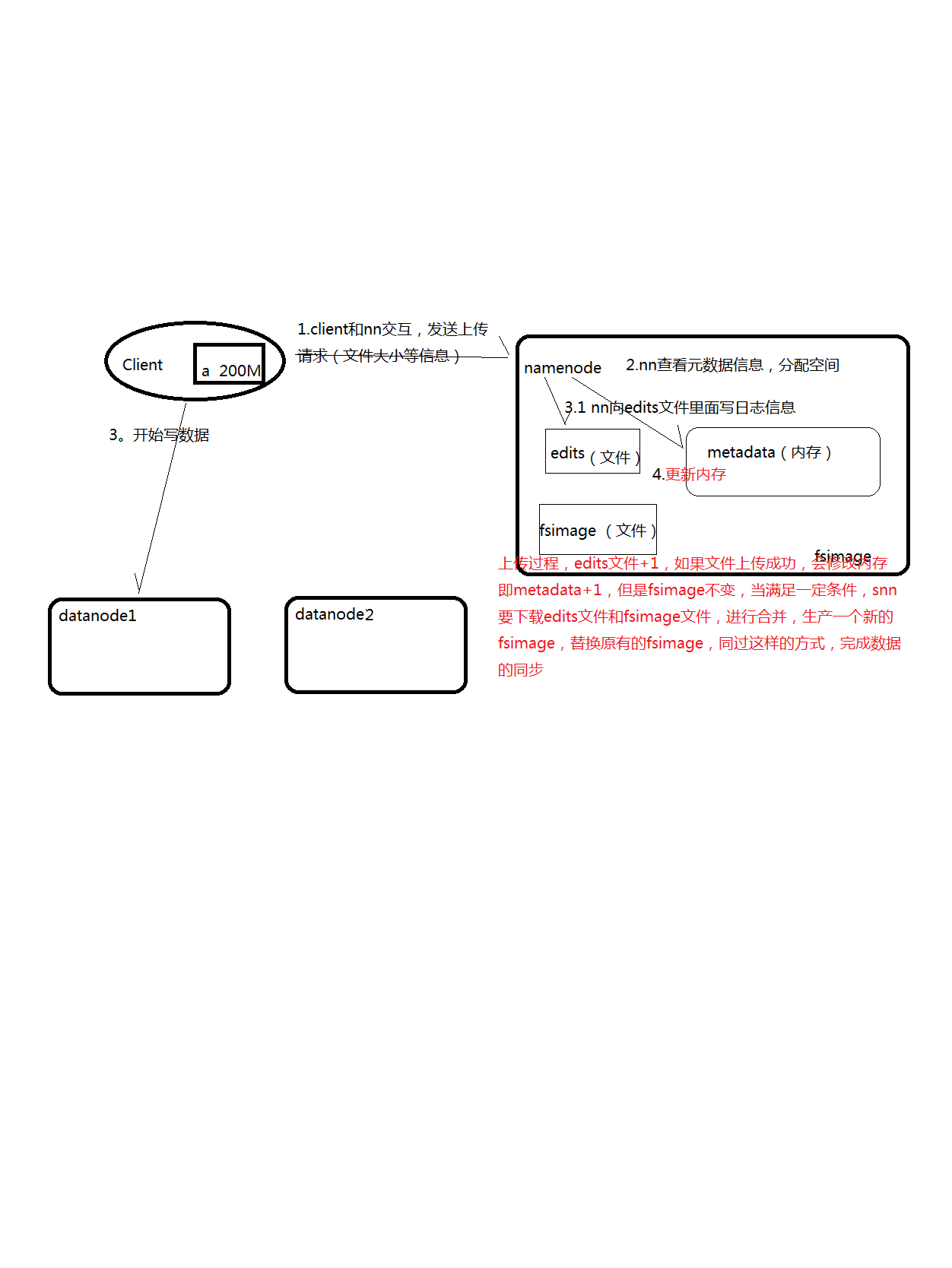
上传完了之后,在hdfs的虚拟路径下,有这个文件,其实,是切分成很多block,放到公共的datanode文件夹下。

134217728/1024/1024=128M,所以,分成2个Block。
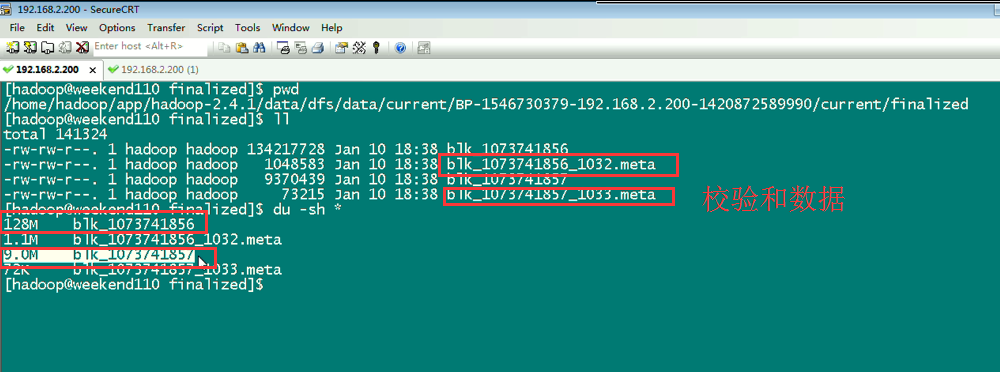


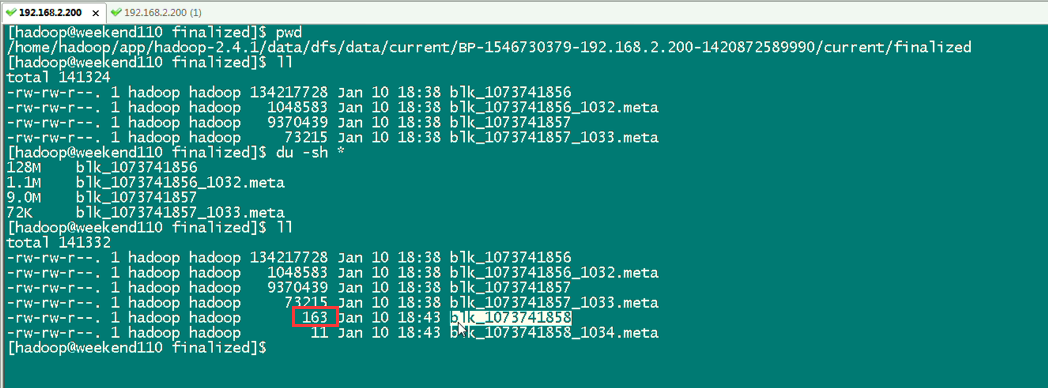
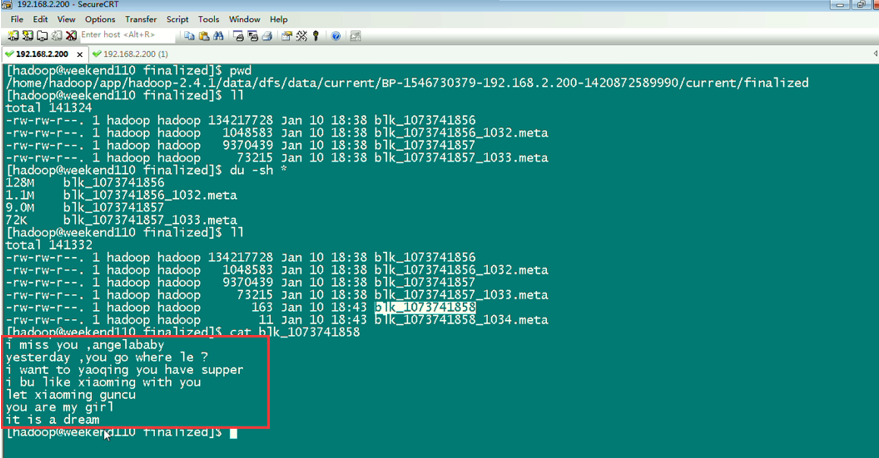
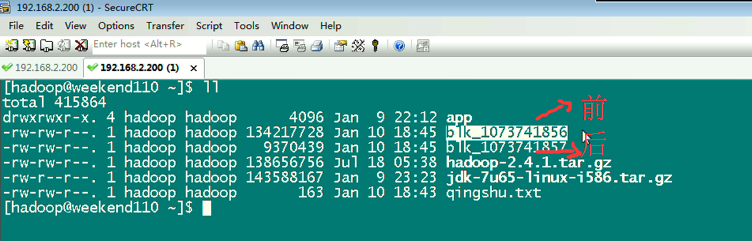



所以,文件被是切分成很多block,放到公共的datanode文件夹下。也可以合并,上述,就是合并,照样,达到复原。。。
总结:对于这块的hdfs下载数据源码分析,值得反复推敲。
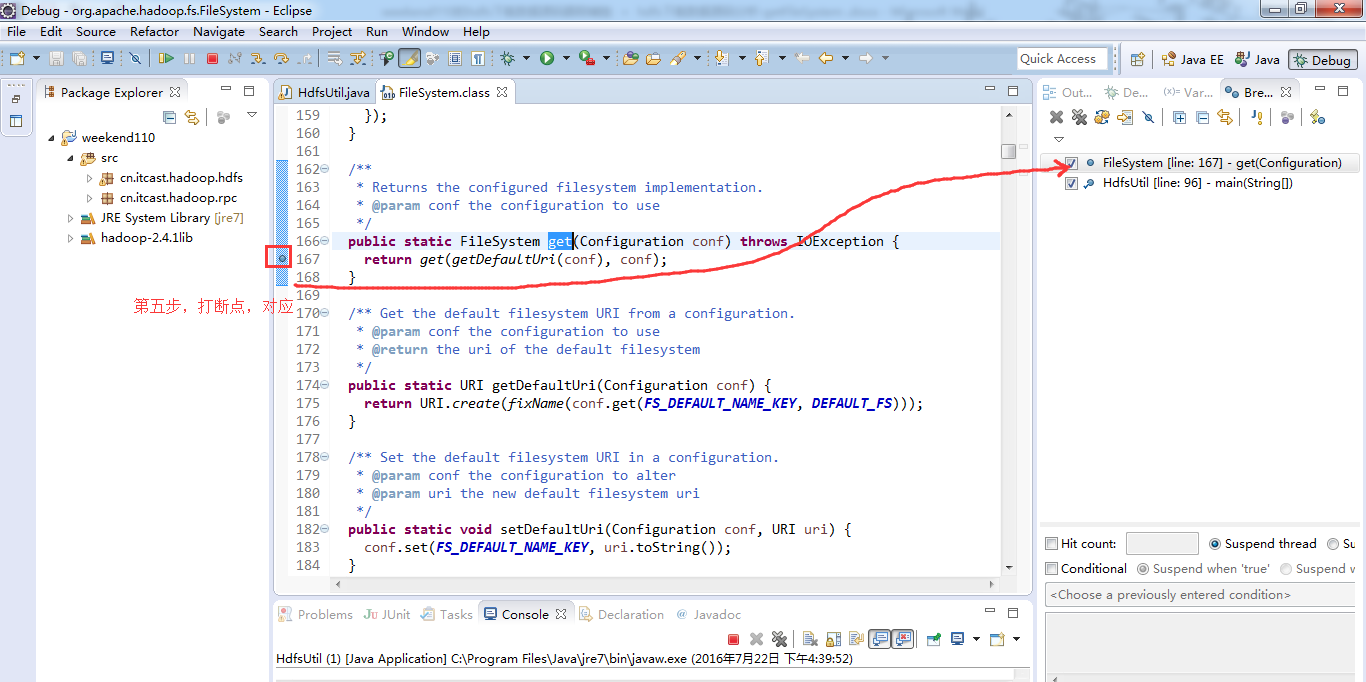
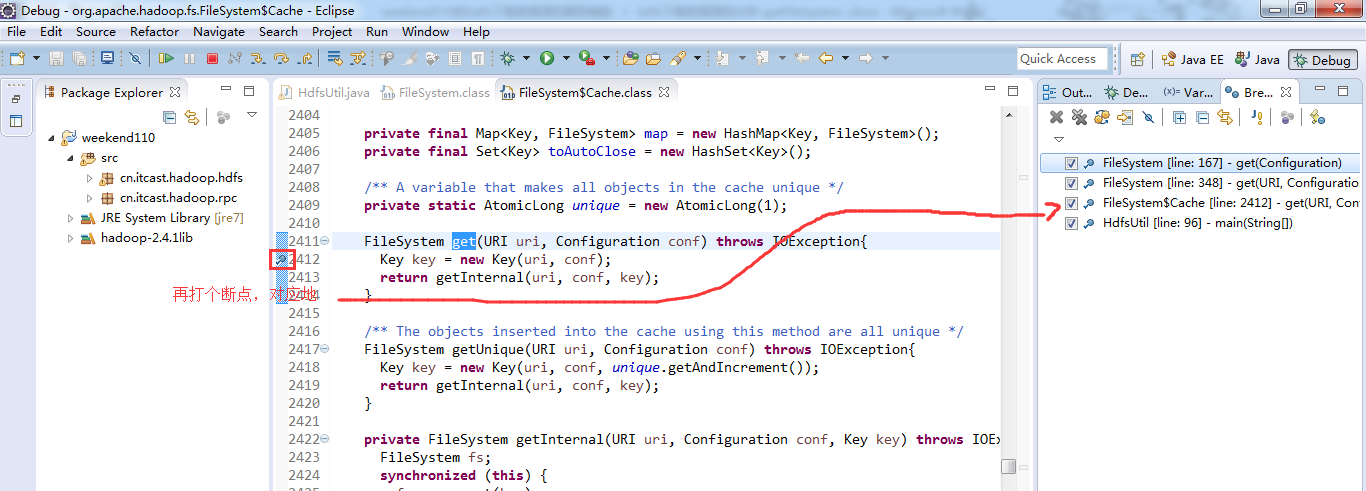
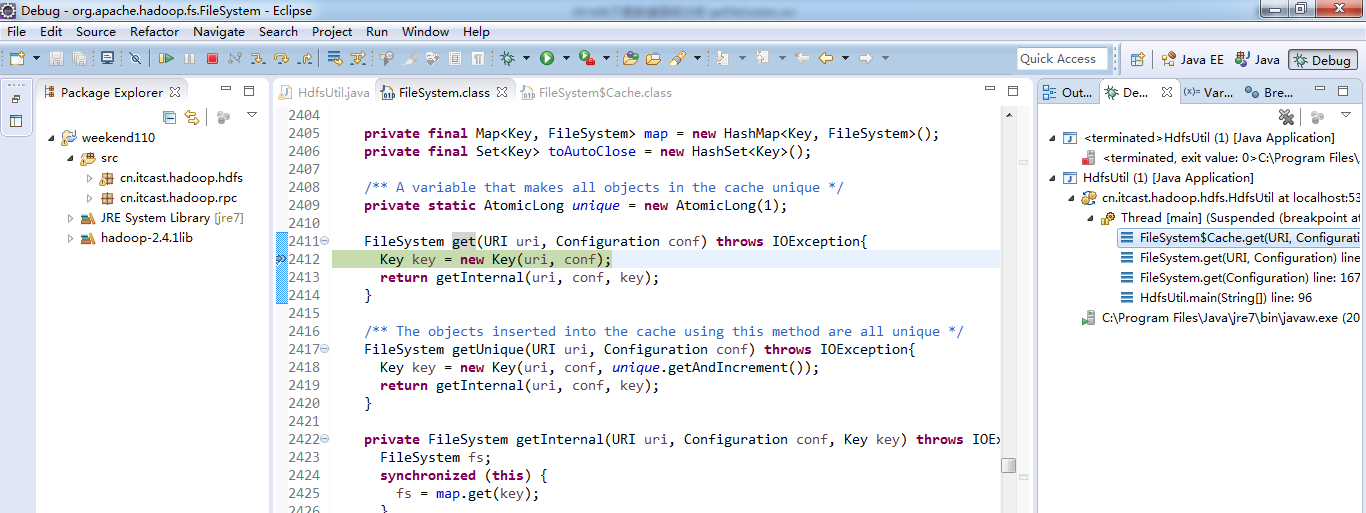
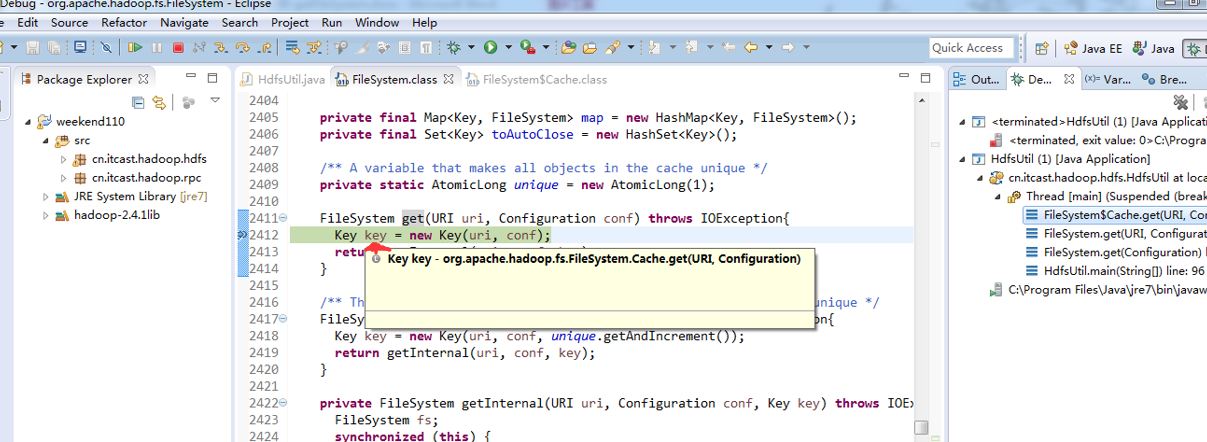
1、 先清除之前所有的断点,不管有还是没有
2、 打一个断点,一步一步下来
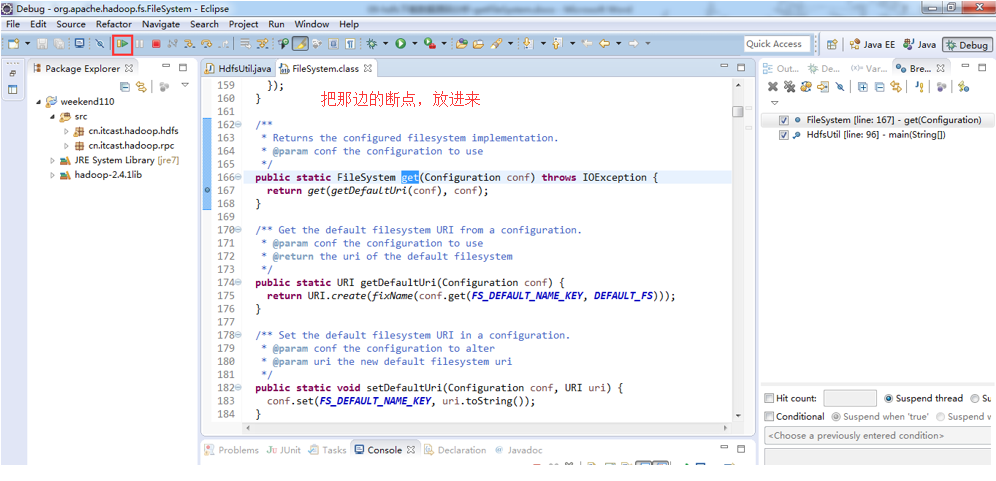
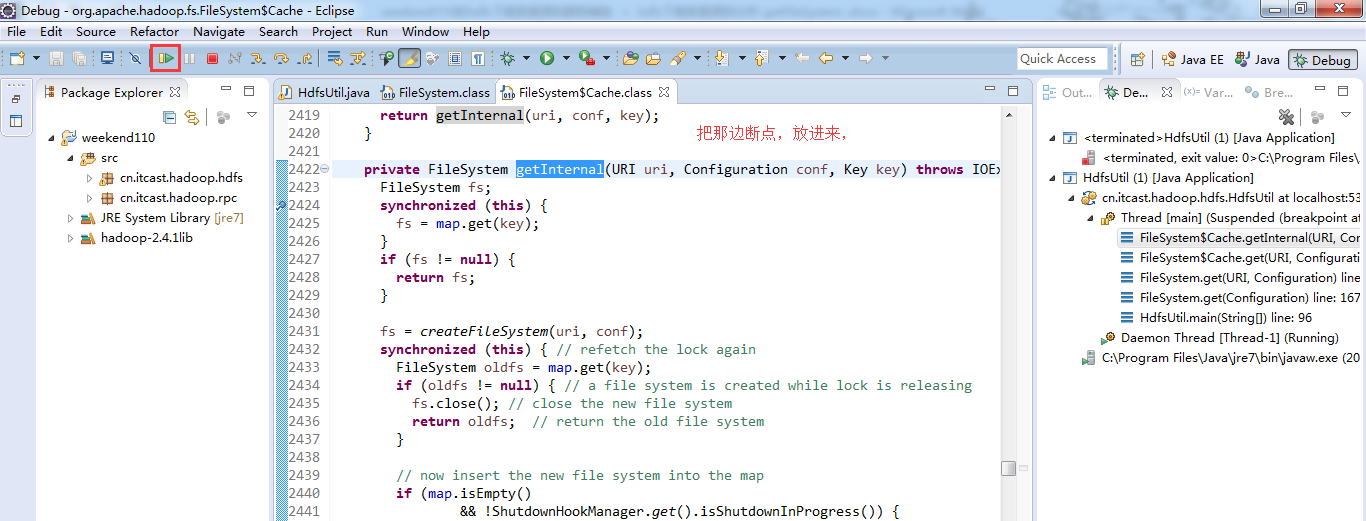
3、 把那边的断点,放进来,
4、 这部分的常用快捷键,F5,F6,F7,Ctrl + o,Ctrl + T,Ctrl + Shift + I,,,
5、 不断提升
本文转自大数据躺过的坑博客园博客,原文链接:http://www.cnblogs.com/zlslch/p/5894558.html,如需转载请自行联系原作者
