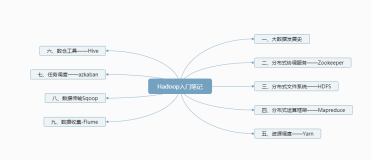
课程目录
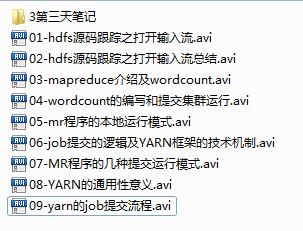
01-hdfs源码跟踪之打开输入流
02-hdfs源码跟踪之打开输入流总结
03-mapreduce介绍及wordcount
04-wordcount的编写和提交集群运行
05-mr程序的本地运行模式
06-job提交的逻辑及YARN框架的技术机制
07-MR程序的几种提交运行模式
08-YARN的通用性意义
09-yarn的job提交流程
本文转自大数据躺过的坑博客园博客,原文链接:http://www.cnblogs.com/zlslch/p/5894876.html,如需转载请自行联系原作者