第一种:普通做法
首先,编号写WordCount.scala程序。
然后,打成jar包,命名为WC.jar。比如,我这里,是导出到windows桌面。
其次,上传到linux的桌面,再移动到hdfs的/目录。
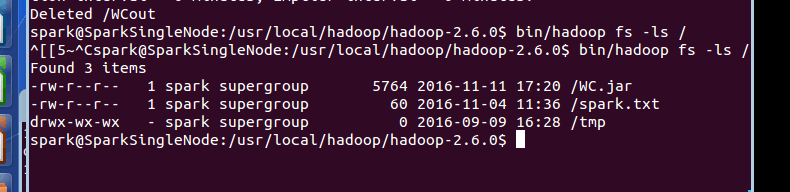
最后,在spark安装目录的bin下,执行
spark-submit \
> --class cn.spark.study.core.WordCount \
> --master local[1] \
> /home/spark/Desktop/WC.jar \
> hdfs://SparkSingleNode:9000/spark.txt \
> hdfs://SparkSingleNode:9000/WCout
第二种:高级做法
有时候我们在Linux中运行Java程序时,需要调用一些Shell命令和脚本。而Runtime.getRuntime().exec()方法给我们提供了这个功能,而且Runtime.getRuntime()给我们提供了以下几种exec()方法:
不多说,直接进入。
步骤一: 为了规范起见,命名为JavaShellUtil.java。在本地里写好

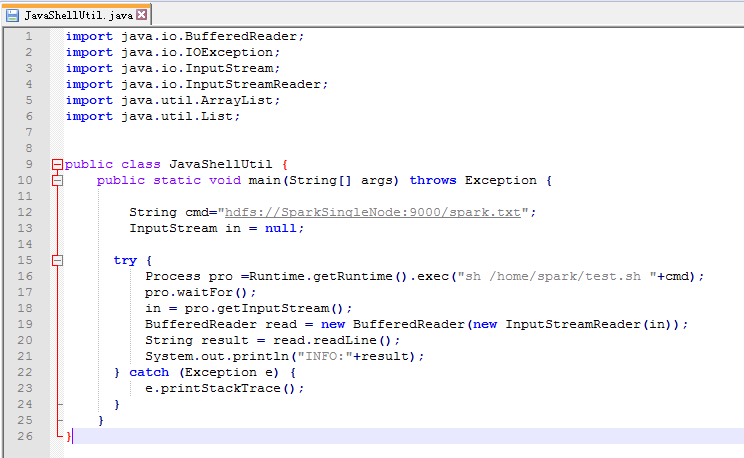
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.List;
public class JavaShellUtil {
public static void main(String[] args) throws Exception {
String cmd="hdfs://SparkSingleNode:9000/spark.txt";
InputStream in = null;
try {
Process pro =Runtime.getRuntime().exec("sh /home/spark/test.sh "+cmd);
pro.waitFor();
in = pro.getInputStream();
BufferedReader read = new BufferedReader(new InputStreamReader(in));
String result = read.readLine();
System.out.println("INFO:"+result);
} catch (Exception e) {
e.printStackTrace();
}
}
}
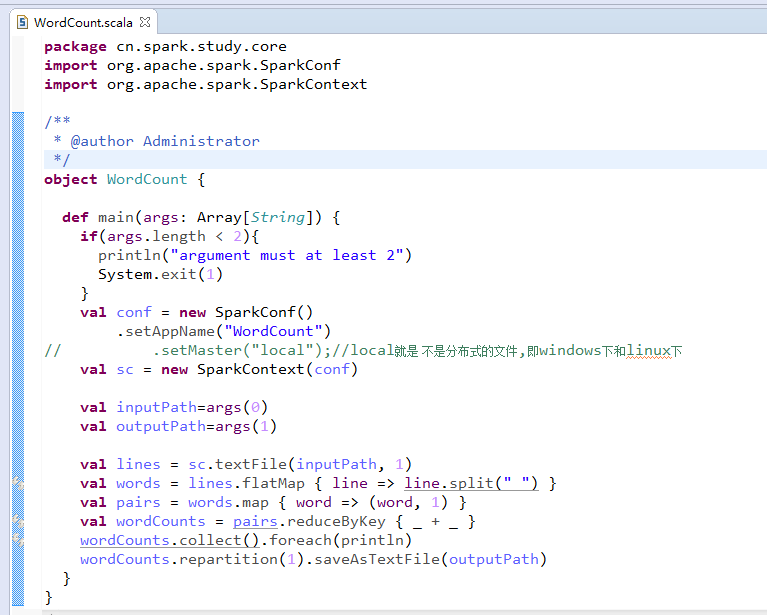
package cn.spark.study.core
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
/**
* @author Administrator
*/
object WordCount {
def main(args: Array[String]) {
if(args.length < 2){
println("argument must at least 2")
System.exit(1)
}
val conf = new SparkConf()
.setAppName("WordCount")
// .setMaster("local");//local就是 不是分布式的文件,即windows下和linux下
val sc = new SparkContext(conf)
val inputPath=args(0)
val outputPath=args(1)
val lines = sc.textFile(inputPath, 1)
val words = lines.flatMap { line => line.split(" ") }
val pairs = words.map { word => (word, 1) }
val wordCounts = pairs.reduceByKey { _ + _ }
wordCounts.collect().foreach(println)
wordCounts.repartition(1).saveAsTextFile(outputPath)
}
}
步骤二:编写好test.sh脚本

spark@SparkSingleNode:~$ cat test.sh
#!/bin/sh
/usr/local/spark/spark-1.5.2-bin-hadoop2.6/bin/spark-submit \
--class cn.spark.study.core.WordCount \
--master local[1] \
/home/spark/Desktop/WC.jar \
$1 hdfs://SparkSingleNode:9000/WCout
步骤三:上传JavaShellUtil.java,和打包好的WC.jar
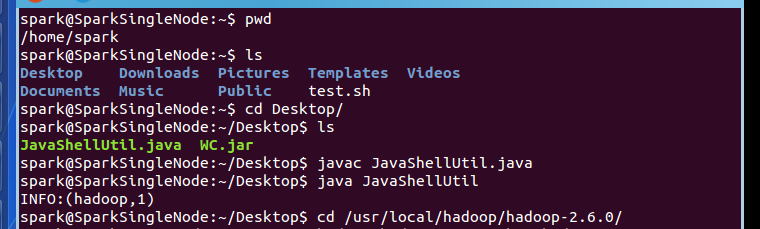
spark@SparkSingleNode:~$ pwd
/home/spark
spark@SparkSingleNode:~$ ls
Desktop Downloads Pictures Templates Videos
Documents Music Public test.sh
spark@SparkSingleNode:~$ cd Desktop/
spark@SparkSingleNode:~/Desktop$ ls
JavaShellUtil.java WC.jar
spark@SparkSingleNode:~/Desktop$ javac JavaShellUtil.java
spark@SparkSingleNode:~/Desktop$ java JavaShellUtil
INFO:(hadoop,1)
spark@SparkSingleNode:~/Desktop$ cd /usr/local/hadoop/hadoop-2.6.0/
步骤四:查看输出结果
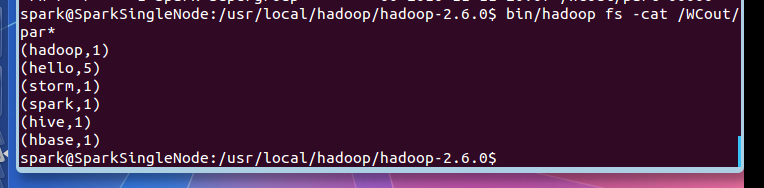
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0$ bin/hadoop fs -cat /WCout/par*
(hadoop,1)
(hello,5)
(storm,1)
(spark,1)
(hive,1)
(hbase,1)
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0$
成功!
关于
Shell 传递参数
见
http://www.runoob.com/linux/linux-shell-passing-arguments.html
最后说的是,不局限于此,可以穿插在以后我们生产业务里的。作为调用它即可,非常实用!
本文转自大数据躺过的坑博客园博客,原文链接:http://www.cnblogs.com/zlslch/p/6055518.html,如需转载请自行联系原作者