



代码

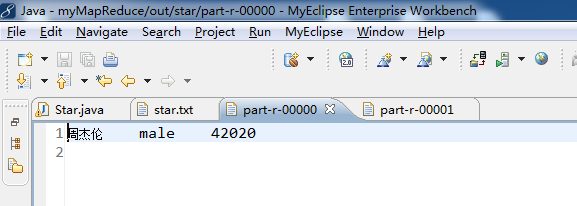
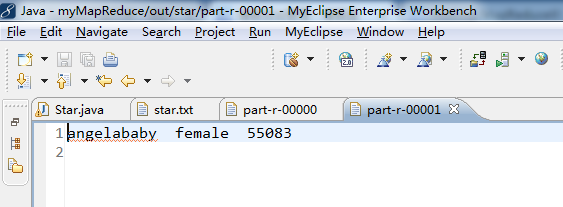
1 package zhouls.bigdata.myMapReduce.Star; 2 3 4 import java.io.IOException; 5 import org.apache.hadoop.conf.Configuration; 6 import org.apache.hadoop.conf.Configured; 7 import org.apache.hadoop.fs.FileSystem; 8 import org.apache.hadoop.fs.Path; 9 import org.apache.hadoop.io.Text; 10 import org.apache.hadoop.mapreduce.Job; 11 import org.apache.hadoop.mapreduce.Mapper; 12 import org.apache.hadoop.mapreduce.Partitioner; 13 import org.apache.hadoop.mapreduce.Reducer; 14 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 15 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 16 import org.apache.hadoop.util.Tool; 17 import org.apache.hadoop.util.ToolRunner; 18 /** 19 * 20 * @function 统计分别统计出男女明星最大搜索指数 21 * @author 小讲 22 */ 23 24 /* 25 姓名 性别 搜索指数 26 李易峰 male 32670 27 朴信惠 female 13309 28 林心如 female 5242 29 黄海波 male 5505 30 成龙 male 7757 31 刘亦菲 female 14830 32 angelababy female 55083 33 王宝强 male 9472 34 郑爽 female 9279 35 周杰伦 male 42020 36 莫小棋 female 13978 37 朱一龙 male 10524 38 宋智孝 female 12494 39 吴京 male 6684 40 赵丽颖 female 24174 41 尹恩惠 female 5985 42 李金铭 female 5925 43 关之琳 female 7668 44 邓超 male 11532 45 钟汉良 male 8289 46 周润发 male 4808 47 甄子丹 male 5479 48 林妙可 female 5306 49 柳岩 female 8221 50 蔡琳 female 7320 51 张佳宁 female 6628 52 裴涩琪 female 5658 53 李晨 male 9559 54 周星驰 male 11483 55 杨紫 female 11094 56 全智贤 female 5336 57 张柏芝 female 9337 58 孙俪 female 7295 59 鲍蕾 female 5375 60 杨幂 female 20238 61 刘德华 male 19786 62 柯震东 male 6398 63 张国荣 male 5013 64 王阳 male 5169 65 李小龙 male 6859 66 林志颖 male 4512 67 林正英 male 5832 68 吴秀波 male 5668 69 陈伟霆 male 12817 70 陈奕迅 male 10472 71 赵又廷 male 5190 72 张馨予 female 35062 73 陈晓 male 17901 74 赵韩樱子 female 7077 75 乔振宇 male 8877 76 宋慧乔 female 5708 77 韩艺瑟 female 5426 78 张翰 male 7012 79 谢霆锋 male 6654 80 刘晓庆 female 5553 81 陈翔 male 7999 82 陈学冬 male 8829 83 秋瓷炫 female 6504 84 王祖蓝 male 6662 85 吴亦凡 male 16472 86 陈妍希 female 32590 87 倪妮 female 9278 88 高梓淇 male 7101 89 赵奕欢 female 7197 90 赵本山 male 12655 91 高圆圆 female 13688 92 陈赫 male 6820 93 鹿晗 male 32492 94 贾玲 female 5304 95 宋佳 female 6202 96 郭碧婷 female 5295 97 唐嫣 female 12055 98 杨蓉 female 10512 99 李钟硕 male 26278 100 郑秀晶 female 10479 101 熊黛林 female 26732 102 金秀贤 male 11370 103 古天乐 male 4954 104 黄晓明 male 10964 105 李敏镐 male 10512 106 王丽坤 female 5501 107 谢依霖 female 7000 108 陈冠希 male 9135 109 范冰冰 female 13734 110 姚笛 female 6953 111 彭于晏 male 14136 112 张学友 male 4578 113 谢娜 female 6886 114 胡歌 male 8015 115 古力娜扎 female 8858 116 黄渤 male 7825 117 周韦彤 female 7677 118 刘诗诗 female 16548 119 郭德纲 male 10307 120 郑恺 male 21145 121 赵薇 female 5339 122 李连杰 male 4621 123 宋茜 female 11164 124 任重 male 8383 125 李若彤 female 9968 126 127 128 得到: 129 angelababy female 55083 130 周杰伦 male 42020 131 */ 132 public class Star extends Configured implements Tool{ 133 /** 134 * @function Mapper 解析明星数据 135 * @input key=偏移量 value=明星数据 136 * @output key=gender value=name+hotIndex 137 */ 138 public static class ActorMapper extends Mapper<Object,Text,Text,Text>{ 139 //在这个例子里,第一个参数Object是Hadoop根据默认值生成的,一般是文件块里的一行文字的行偏移数,这些偏移数不重要,在处理时候一般用不上 140 public void map(Object key,Text value,Context context) throws IOException,InterruptedException{ 141 //拿:周杰伦 male 42020 142 //value=name+gender+hotIndex 143 String[] tokens = value.toString().split("\t");//使用分隔符\t,将数据解析为数组 tokens 144 String gender = tokens[1].trim();//性别,trim()是去除两边空格的方法 145 //tokens[0] tokens[1] tokens[2] 146 //周杰伦 male 42020 147 String nameHotIndex = tokens[0] + "\t" + tokens[2];//名称和关注指数 148 //输出key=gender value=name+hotIndex 149 context.write(new Text(gender), new Text(nameHotIndex));//写入gender是k2,nameHotIndex是v2 150 // context.write(gender,nameHotIndex);等价 151 //将gender和nameHotIndex写入到context中 152 } 153 } 154 155 156 157 /** 158 * @function Partitioner 根据sex选择分区 159 */ 160 public static class ActorPartitioner extends Partitioner<Text, Text>{ 161 @Override 162 public int getPartition(Text key, Text value, int numReduceTasks){ 163 String sex = key.toString();//按性别分区 164 165 // 默认指定分区 0 166 if(numReduceTasks==0) 167 return 0; 168 169 //性别为male 选择分区0 170 if(sex.equals("male")) 171 return 0; 172 //性别为female 选择分区1 173 if(sex.equals("female")) 174 return 1 % numReduceTasks; 175 //其他性别 选择分区2 176 else 177 return 2 % numReduceTasks; 178 179 } 180 } 181 182 183 184 /** 185 * @function 定义Combiner 合并 Mapper 输出结果 186 */ 187 public static class ActorCombiner extends Reducer<Text, Text, Text, Text>{ 188 private Text text = new Text(); 189 @Override 190 public void reduce(Text key, Iterable<Text> values, Context context)throws IOException, InterruptedException{ 191 int maxHotIndex = Integer.MIN_VALUE; 192 int hotIndex = 0; 193 String name=""; 194 for (Text val : values){//星型for循环,即把values的值传给Text val 195 String[] valTokens = val.toString().split("\\t"); 196 hotIndex = Integer.parseInt(valTokens[1]); 197 if(hotIndex>maxHotIndex){ 198 name = valTokens[0]; 199 maxHotIndex = hotIndex; 200 } 201 } 202 text.set(name+"\t"+maxHotIndex); 203 context.write(key, text); 204 } 205 } 206 207 208 209 /** 210 * @function Reducer 统计男、女明星最高搜索指数 211 * @input key=gender value=name+hotIndex 212 * @output key=name value=gender+hotIndex(max) 213 */ 214 public static class ActorReducer extends Reducer<Text,Text,Text,Text>{ 215 @Override 216 public void reduce(Text key, Iterable<Text> values, Context context)throws IOException, InterruptedException{ 217 int maxHotIndex = Integer.MIN_VALUE; 218 219 String name = " "; 220 int hotIndex = 0; 221 // 根据key,迭代 values 集合,求出最高搜索指数 222 for (Text val : values){//星型for循环,即把values的值传给Text val 223 String[] valTokens = val.toString().split("\\t"); 224 hotIndex = Integer.parseInt(valTokens[1]); 225 if (hotIndex > maxHotIndex){ 226 name = valTokens[0]; 227 maxHotIndex = hotIndex; 228 } 229 } 230 context.write(new Text(name), new Text(key + "\t"+ maxHotIndex));//写入name是k3,key + "\t"+ maxHotIndex是v3 231 // context.write(name,key + "\t"+ maxHotIndex);//等价 232 } 233 } 234 235 /** 236 * @function 任务驱动方法 237 * @param args 238 * @return 239 * @throws Exception 240 */ 241 242 public int run(String[] args) throws Exception{ 243 // TODO Auto-generated method stub 244 245 Configuration conf = new Configuration();//读取配置文件,比如core-site.xml等等 246 Path mypath = new Path(args[1]);//Path对象mypath 247 FileSystem hdfs = mypath.getFileSystem(conf);//FileSystem对象hdfs 248 if (hdfs.isDirectory(mypath)){ 249 hdfs.delete(mypath, true); 250 } 251 252 Job job = new Job(conf, "star");//新建一个任务 253 job.setJarByClass(Star.class);//主类 254 255 job.setNumReduceTasks(2);//reduce的个数设置为2 256 job.setPartitionerClass(ActorPartitioner.class);//设置Partitioner类 257 258 job.setMapperClass(ActorMapper.class);//Mapper 259 job.setMapOutputKeyClass(Text.class);//map 输出key类型 260 job.setMapOutputValueClass(Text.class);//map 输出value类型 261 262 job.setCombinerClass(ActorCombiner.class);//设置Combiner类 263 264 job.setReducerClass(ActorReducer.class);//Reducer 265 job.setOutputKeyClass(Text.class);//输出结果 key类型 266 job.setOutputValueClass(Text.class);//输出结果 value类型 267 268 FileInputFormat.addInputPath(job, new Path(args[0]));// 输入路径 269 FileOutputFormat.setOutputPath(job, new Path(args[1]));// 输出路径 270 job.waitForCompletion(true);//提交任务 271 return 0; 272 } 273 274 275 /** 276 * @function main 方法 277 * @param args 278 * @throws Exception 279 */ 280 public static void main(String[] args) throws Exception{ 281 // String[] args0 = { "hdfs://HadoopMaster:9000/star/star.txt", 282 // "hdfs://HadoopMaster:9000/out/star/" }; 283 String[] args0 = { "./data/star/star.txt", 284 "./out/star" }; 285 286 int ec = ToolRunner.run(new Configuration(), new Star(), args0); 287 System.exit(ec); 288 } 289 }
本文转自大数据躺过的坑博客园博客,原文链接:http://www.cnblogs.com/zlslch/p/6165047.html,如需转载请自行联系原作者




