Hive可以通过实现用户定义函数(User-Defined Functions,UDF)进行扩展(事实上,大多数Hive功能都是通过扩展UDF实现的)。想要开发UDF程序,需要继承org.apache.hadoop.ql.exec.UDF类,并重载evaluate方法。Hive API提供@Description声明,使用声明可以在代码中添加UDF的具体信息。在Hive中可以使用DESCRIBE语句来展现这些信息。
Hive的源码本身就是编写UDF最好的参考资料。在Hive源代码中很容易就能找到与需求功能相似的UDF实现,只需要复制过来,并加以适当的修改就可以满足需求。
下面是一个具体的UDF例子,该例子的功能是将字符串全部转化为小写字母
package com.madhu.udf;
import org.apache.hadoop.hive.ql.exec.Desription;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
//add jar samplecode.jar;
//create temporary function to_upper as 'com.madhu.udf.UpercaseUDF';
@Desription(
name="to_upper",
value="_FUNC_(str) -Converts a string to uppercase",
extended="Example:\n" +
" > select to_upper(producer) from videos_ex;\n" +
" JOHN MCTIERNAN"
)
public class UpercaseUDF extends UDF{
public Text evaluate(Text input){
Text result = new Text("");
if (input != null){
result.set(input.toString().toUpperCase());
}
return result;
}
}
UDF只有加入到Hive系统路径,并且使用唯一的函数名注册后才能在Hive中使用。UDF应该被打成JAR包。
上传打好的 samplecode.jar,然后如下
下面的语句可以把JAR条件放入Hive系统路径,并注册相关函数:
hive > add jar samplecode.jar 这个目录,根据自己的情况而定
Added samplecode.jar to class path
Added resource:samplecode.jar
hive> create temporary function to_upper as 'com.madhu.udf.UppercaseUDF';
现在可以在Hive中使用这个函数了:
hive > describe function to_upper;
OK
to_upper(str) -Converts a string to uppercase
Time taken:0.039 seconds,Fetched:1 row(s)
hive > describe function extended to_upper;
OK
to_upper(str) - Converts a string to uppercase
Example:
> select to_upper(producer) from videos_ex;
JOHN MCTIERNAN
Time taken:0.07 seconds,Fetched:4 row(s)
手动的话,见
3 hql语法及自定义函数 + hive的java api
自动的话,见
Hive项目开发环境搭建(Eclipse\MyEclipse + Maven)

这里,我自己写了一个hiveEvaluateUDF 自定义函数,实现某一个我们自己想要的功能。比如,我这里是转换功能。开始编写代码
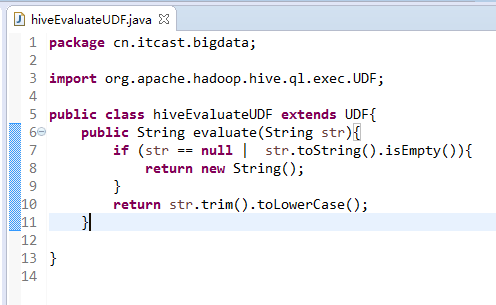
package cn.itcast.bigdata;
import org.apache.hadoop.hive.ql.exec.UDF;
public class hiveEvaluateUDF extends UDF{
public String evaluate(String str){
if (str == null | str.toString().isEmpty()){
return new String();
}
return str.trim().toLowerCase();
}
}
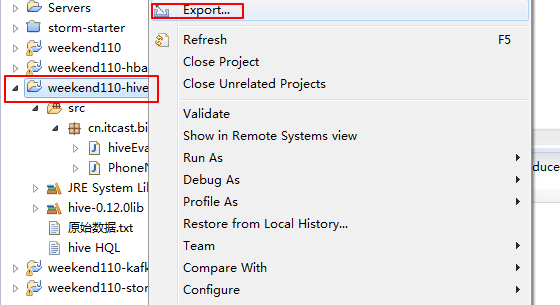
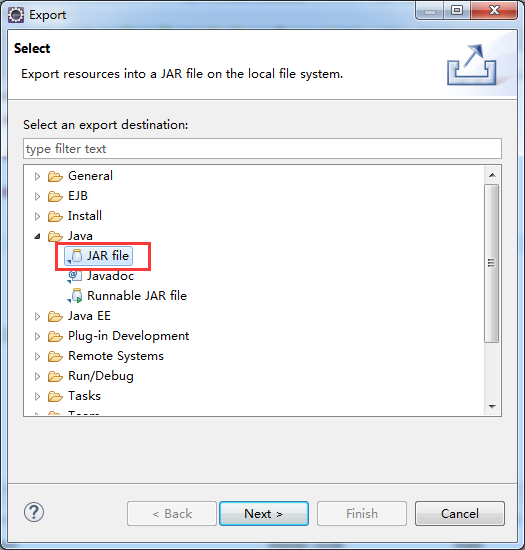
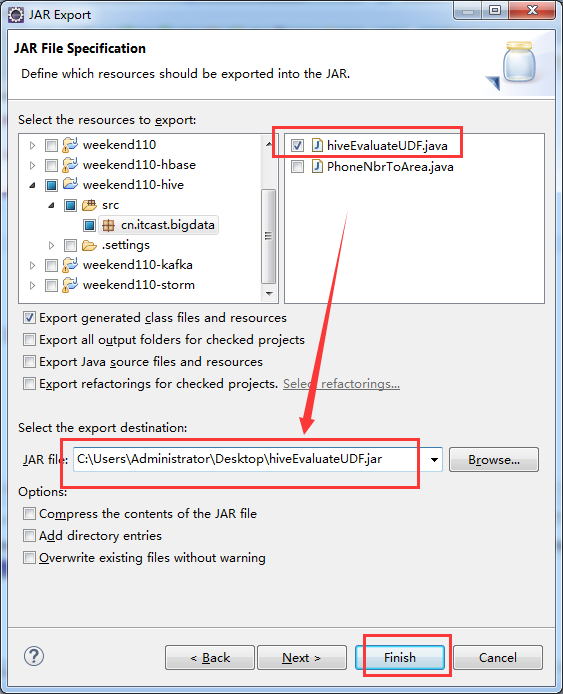


hive> add jar hiveEvaluateUDF.jar;

得到 cn.itcast.bigdata.hiveEvaluateUDF
hive> create temporary function to_lower as 'cn.itcast.bigdata.hiveEvaluateUDF';
剩下的,自行去尝试。
如何用好自己写好的自定义UDF函数
方法一:
比如,我这里,有个转大写的自定义UDF函数,自己写个vi hiveupperrc文件。每次执行这个文件,这个自定义的转大写函数能用了。
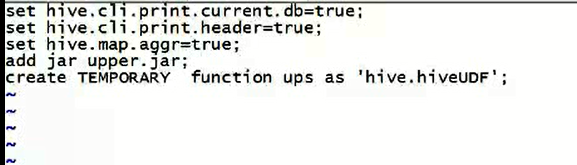
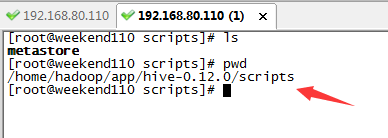
方法二:
在$HIVE_HOME/scripts目录下,写个如 hiveupperrc.sh脚本。
本文转自大数据躺过的坑博客园博客,原文链接:http://www.cnblogs.com/zlslch/p/6106218.html,如需转载请自行联系原作者




