一,介绍
Oozie是一个基于Hadoop的工作流调度器,它可以通过Oozie Client 以编程的形式提交不同类型的作业,如MapReduce作业和Spark作业给底层的计算平台(如 Cloudera Hadoop)执行。
Quartz是一个开源的调度软件,它为任务的调度执行提供了各种触发器以及监听器
下面使用Quartz + Oozie 将一个MapReduce程序提交给Cloudera Hadoop执行
二,调度思路
①为什么要用Quartz呢?主要是借助Quartz强大的触发器功能。它可以允许满足不同的调度需求,如每周执行作业一次、重复执行作业多少次。这里有一个重要的问题:假设我有一个作业需要重复执行,当第一次把该作业提交到CDH上执行后,以后需要执行该作业时不再是又一次把该作业上传到CDH上然后执行,而是把提交过的作业记录下来,下次需要运行时,直接让CDH再运行该作业。
②使用Quartz还有一个好处就是:在作业提交的时候可以做一些控制。比如,某种类型的作业提交的频率很高,或者运行时间较短(根据它上次执行完的情况来判断),那么下次运行它时,让它具有更高的优先级。
③使用Oozie的目的很明确,就是让它把作业发送给底层的计算平台,如CDH去执行作业。
三,Eclipse开发环境搭建
主要是需要Quartz和Oozie的依赖包。具体如下:

四,实现思路
a) 调度系统目前只考虑调度两种类型的作业:Mapreduce作业和Spark作业。先把这二种作业通过Quartz传递给Oozie,然后再让Oozie把作业提交给CDH计算平台去执行。
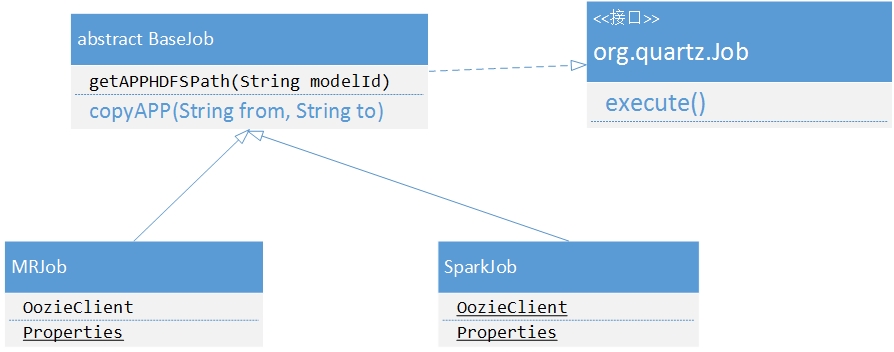
b) Quartz提供了一个公共的Job接口。里面只有一个execute()方法,该方法负责完成Quartz所调度的作业的具体功能:把作业传递给Oozie
c) 定义一个抽象类BaseJob,它里面定义了二个方法。这二个方法主要是用来做一些准备工作,即使用Quartz把作业传递给Oozie时需要找到作业在HDFS上的存储目录,并将之复制执行目录下。
d) 最后是两个具体的实现类,MRJob和SparkJob,它们分别代表Mapreduce作业和Spark作业。在实现类里面完成作业的配置,然后将作业提交到CDH计算平台上执行。
相关类图如下:
五,具体代码分析
MRJob.java
实现了org.quartz.Job接口的execute(),该方法当触发器被触发时,会自动地被Quartz Schedule 调度执行。这样,就可以根据需要定义触发器,控制作业何时提交给Oozie。

1 @Override 2 public void execute(JobExecutionContext arg0) throws JobExecutionException { 3 try{ 4 String jobId = wc.run(conf); 5 System.out.println("Workflow job submitted");//submit job to oozie and get the jobId 6 7 //wait until the workflow job finishes 8 while(wc.getJobInfo(jobId).getStatus() == Status.RUNNING){ 9 System.out.println("Workflow job running..."); 10 try{ 11 Thread.sleep(10*1000); 12 }catch(InterruptedException e){e.printStackTrace();} 13 } 14 System.out.println("Workflow job completed!"); 15 System.out.println(wc.getJobId(jobId)); 16 }catch(OozieClientException e){e.printStackTrace();} 17 }
测试的main函数程序如下:可以看出对于客户端而言,只需要按照编写常规的Quartz作业方式,就可以调试MapReduce作业了。要想运行该程序,当然还得提前准备到作业的运行环境。具体参考
1 import static org.quartz.JobBuilder.newJob; 2 import static org.quartz.TriggerBuilder.newTrigger; 3 4 import java.util.Date; 5 6 import org.quartz.JobDetail; 7 import org.quartz.Scheduler; 8 import org.quartz.SchedulerFactory; 9 import org.quartz.SimpleTrigger; 10 import org.quartz.impl.StdSchedulerFactory; 11 import org.slf4j.Logger; 12 import org.slf4j.LoggerFactory; 13 14 import com.quartz.job.MRJob; 15 16 17 public class QuartzOozieJobTest { 18 public static void main(String[] args) throws Exception{ 19 QuartzOozieJobTest test = new QuartzOozieJobTest(); 20 test.run(); 21 } 22 23 public void run() throws Exception{ 24 Logger log = LoggerFactory.getLogger(QuartzOozieJobTest.class); 25 26 log.info("------- Initializing ----------------------"); 27 28 SchedulerFactory sf = new StdSchedulerFactory(); 29 Scheduler sched = sf.getScheduler(); 30 31 long startTime = System.currentTimeMillis() + 20000L; 32 Date startTriggerTime = new Date(startTime); 33 34 JobDetail jobDetail = newJob(MRJob.class).withIdentity("job", "group1").build(); 35 SimpleTrigger trigger = (SimpleTrigger) newTrigger().withIdentity("trigger", "group1").startAt(startTriggerTime).build(); 36 37 Date ft = sched.scheduleJob(jobDetail, trigger); 38 39 log.info(jobDetail.getKey() + " will submit at " + ft + " only once."); 40 41 sched.start(); 42 // sched.shutdown(true); 43 } 44 }
本文转自hapjin博客园博客,原文链接:http://www.cnblogs.com/hapjin/p/4943592.html,如需转载请自行联系原作者

