我们在写Hadoop--map/reduce程序时,遇到使用按文件url来分析文件----------多表连接的DistributedCache方式,看不懂使用extends Configured implements Tool的方式,就查了一下http://hadoop.apache.org 上面对该Tool接口及其使用做了说明:
- @InterfaceAudience.Public
- @InterfaceStability.Stable
- public interface Tool //Tool接口继承了Configurable
- extends Configurable
- //Tool接口可以支持处理通用的命令行选项,它是所有Map-Reduce程序的都可用的一个标准接口,下面是一个典型用例:
- public class MyApp extends Configured implements Tool {
- public int run(String[] args) throws Exception {
- //ToolRunner要处理的Configuration,Tool通过ToolRunner调用ToolRunner.run时,传入参数Configuration
- Configuration conf = getConf();
- JobConf job = new JobConf(conf, MyApp.class);
- Path in = new Path(args[1]);
- Path out = new Path(args[2]);
- // 设置job的各种详细参数
- job.setJobName("my-app");
- job.setInputPath(in);
- job.setOutputPath(out);
- job.setMapperClass(MyMapper.class);
- job.setReducerClass(MyReducer.class);
- //提交job
- JobClient.runJob(job);
- return 0;
- }
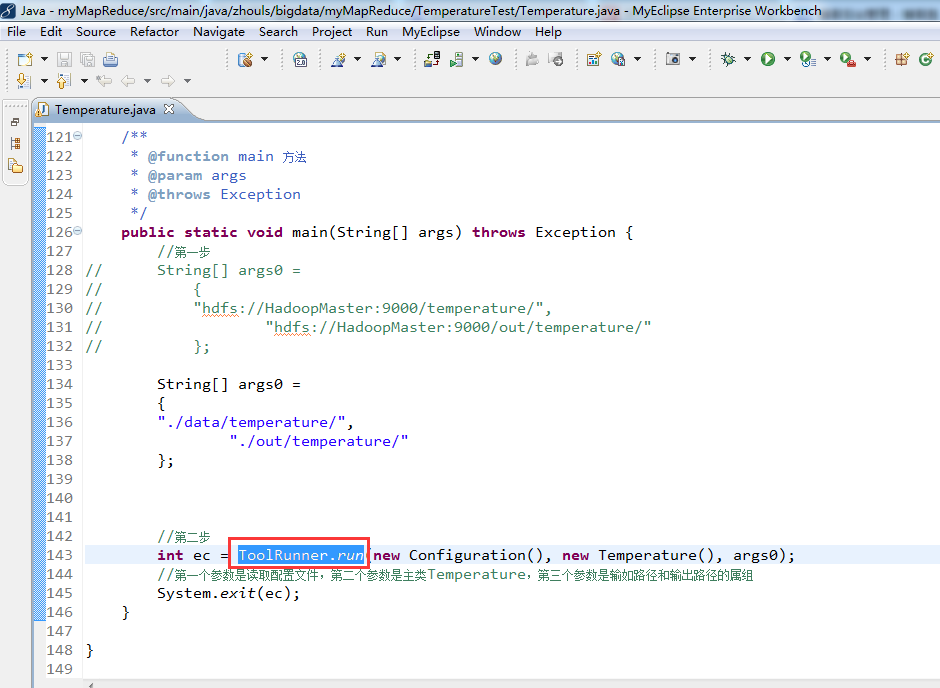
- public static void main(String[] args) throws Exception {
- // 让ToolRunner执行
- int res = ToolRunner.run(new Configuration(), new MyApp(), args);
- System.exit(res);
- }
- }

本文转自大数据躺过的坑博客园博客,原文链接:http://www.cnblogs.com/zlslch/p/6431833.html,如需转载请自行联系原作者