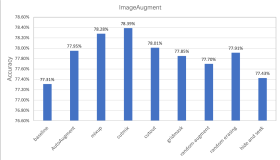
1.准备训练样本图片,包括正例及反例样本
1)正样本的采集:
所谓正样本,是指只包含待识别的物体的图片,一般是一些局部的图片,且最好能转化为灰度图。比如,若你想识别人脸,则正样本应尽可能只包含人脸,可以留一点周边的背景但不要过多。在正样本的采集上,我们有两种图形标定工具可以使用:(1)opencv的imageClipper (2)objectMarker。这两个工具都支持傻瓜式地对图片中的物体进行矩形标定,可以自动生成样本说明文件,自动逐帧读取文件夹内的下一帧。我用的是objectMarker。如果你找不到这个软件,可以留下邮箱,我发给你。
在标定的时候尽量保持长宽比例一致,也就是尽量用接近正方形的矩形去标定待识别的物体,至于正方形的大小影响并不大。尽管OpenCV推荐训练样本的最佳尺寸是20x20,但是在下一步生成样本描述文件时可以轻松地将其它尺寸缩放到20x20。标定完成后生成的样本说明文件info.txt内容举例如下:
|
1
2
3
4
5
|
rawdata/ (1).bmp 1 118 26 81 72
rawdata/ (10).bmp 2 125 72 48 46 0 70 35 43
rawdata/ (11).bmp 1 105 87 43 42
rawdata/ (12).bmp 2 1 70 34 38 105 87 41 44
...
|
其中rawdata文件夹存放了所有待标定的大图,objectMarker.exe与rawdata文件夹同级。这个描述文件的格式已经很接近opencv所要求的了。
2)负样本的采集:
所谓负样本,是指不包含待识别物体的任何图片,因此你可以将天空、海滩、大山等所有东西都拿来当负样本。但是,很多时候你这样做是事倍功半的。大多数模式识别问题都是用在视频监控领域,摄像机的角度跟高度都相对固定。如果你知道你的项目中摄像机一般都在拍什么,那负样本可以非常有针对性地选取,而且可以事半功倍。举个例子,你现在想做火车站广场的异常行为检测,在这个课题中行人检测是必须要做的。而视频帧的背景基本都是广场的地板、建筑物等。那你可以在人空旷的时候选择取一张图,不同光照不同时段下各取一张图,然后在这些图上随机取图像块,每个块20x20,每个块就是一个负样本。这几张图就能缠上数以千计数以万计的负样本!而且针对性强。因为海洋、大山等东西对你的识别一点帮助也没有,还会增加训练的时间,吃力不讨好的事还是少做为好。我写了一段小程序,功能是根据背景图片自动随机生成指定数量指定尺寸的负样本:
 负样本生成代码
负样本生成代码
这里的负样本尺寸我设定为40x40,是因为在我的应用环境下待识别的物体差不多是这个尺寸的。具体可以分析一下你的info.txt文件。生成文件后,开cmd.exe cd到该目录,然后运行“dir /b > neg_sample.dat”,打开.dat,用editplus替换bmp为bmp 1 0 0 40 40。这样负样本说明文件就产生了。
对于负样本,我还有一点要说明:负样本图像的大小只要不小于正样本就可以。opencv在使用你提供的一张负样本图片时会自动从其中抠出一块与正样本同样大小的图像作为负样本,具体的函数可见opencv系统函数cvGetNextFromBackgroundData()。
2.生成样本描述文件
样本描述文件也即.vec文件,里面存放二进制数据,是为opencv训练做准备的。只有正样本需要生成.vec文件,负样本不用,负样本用.dat文件就够。在生成描述文件过程中,我们需要用到opencv自带的opencv_createsamples.exe可执行文件。这个文件一般存放在opencv安装目录的/bin文件夹下(请善用ctrl+F搜索)。如果没有,可以自己编译一遍也很快。这里提供懒人版:http://en.pudn.com/downloads204/sourcecode/graph/texture_mapping/detail958471_en.html 这是别人编译出来的opencv工程,在bin底下可以找到该exe文件。要注意,该exe依赖于cv200.dll、cxcore200.dll、highgui200.dll这三个动态库,要保持这四个文件在同个目录下。

现在我们开始生成描述文件。新建文件夹pos、neg分别存放正样本及负样本图片,此处是指没标定的大图。
1)修改样本说明文件的格式:
在第1步中我们用objectMarker完成标定后会自动生成info.txt,现在我们需要对其格式做一定的微调,通过editplus或者ultraedit将路径信息rawdata都替换掉,并命名为sample_pos.dat,也可自定义名字。
|
1
2
3
4
5
6
|
(1).bmp 1 118 26 81 72
(10).bmp 2 125 72 48 46 0 70 35 43
(11).bmp 1 105 87 43 42
(12).bmp 2 1 70 34 38 105 87 41 44
(13).bmp 1 102 93 43 41
(14).bmp 1 104 86 45 47
|
2)使用opencv_createsamples.exe创建样本描述文件:
打开cmd.exe,cd到opencv_createsamples.exe所在的目录,执行命令:
|
1
|
opencv_createsamples.exe -info ./pos/sample_pos.dat -vec ./pos/sample_pos.vec -num 17 -w 20 -h 20 -show YES
|
参数说明:-info,指样本说明文件
-vec,样本描述文件的名字及路径
-num,总共几个样本,要注意,这里的样本数是指标定后的20x20的样本数,而不是大图的数目,其实就是样本说明文件第2列的所有数字累加 和。
-w -h 指明想让样本缩放到什么尺寸。这里的奥妙在于你不必另外去处理第1步中被矩形框出的图片的尺寸,因为这个参数帮你统一缩放!
-show 是否显示每个样本。样本少可以设为YES,要是样本多的话最好设为NO,或者不要显式地设置,因为关窗口会关到你哭
done表示创建成功,若创建不成功会报错,大部分会提示你sample.dat pars error,一般是说明文件格式有错,或者num设置过大
|
1
2
|
Create training samples
from
images collection...
Done. Created 17 samples
|
总结
总结并延伸以上内容:
1.样本图片最好使用灰度图,且最好能根据实际情况做一定的预处理
2.样本选择的原则是:数量越多越好,尽量高于1000;样本间差异性越大越好
3.正负样本比例为1:3最佳,尺寸为20x20最佳
本文转自编程小翁博客园博客,原文链接:http://www.cnblogs.com/wengzilin/p/3845271.html,如需转载请自行联系原作者