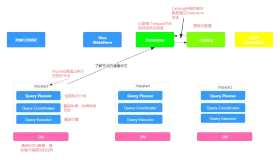
Hive与Impala都是构建在Hadoop之上的数据查询工具,那么在实际的应用中,它们是如何加载和存储数据的呢?
Hive和Impala存储和加载表,和所有的关系型数据库一样,有自己的数据管理结构,从它的Server到Database再到表和视图。
在其他的数据库中,表都是以自己特定的文件格式来存储的,比如Oracle有自己的存储格式,而对Hive而言,一个表就是包含一个或多个文件的HDFS目录,这个文件是属于表下面的内容,默认存储路径:/user/hive/warehouse/<table_name>,支持多种存储格式。
以上就是数据的存储,那么每一个表、每一个结构都有自己的列或者类型定义的信息,这些信息该如何去保存呢?它们存储在Metastore里,而所有的数据都存储在HDFS之上,所以我们想要获得表结构信息,就需要知道hive的元数据中每个表的含义和结构。在hive中,有简单的命令可以大概的查看表的结构信息:describe formatted tableName; hive metastore表结构如下:

因为Hive和Impala使用相同的数据,表在HDFS,元数据在Metastore,所以以上的存储及结构介绍同样适用于Impala。
数据加载及存储示例:

在这里呢我们必须要区分两个概念:数据和元数据。数据指的是你存储和处理的信息,比如账单记录、传感器读数和服务日志等。而元数据用来描述数据的形态,比如字段名和顺序等。

Hive与Impala都是构建在Hadoop之上的数据查询工具,那么在实际的应用中,它们是如何加载和存储数据的呢?
Hive和Impala存储和加载表,和所有的关系型数据库一样,有自己的数据管理结构,从它的Server到Database再到表和视图。
本文转自大数据躺过的坑博客园博客,原文链接:http://www.cnblogs.com/zlslch/p/6785707.html,如需转载请自行联系原作者