Tachyon命令行使用
-
Tachyon接口说明
-
接口操作示例
-
copyFromLocal
-
copyToLocal
-
ls和lsr
-
count
-
cat
-
mkdir、rm、rmr和touch
-
pin和unpin
-
1、Tachyon命令行使用
Tachyon的命令行界面让用户可以对文件系统进行基本的操作。调用命令行工具使用以下脚本:
$./tachyon tfs
文件系统访问的路径格式如下:
tachyon://<master node address>:<master node port>/<path>
在Tachyon命令行使用中tachyon://<master node address>:<master node port>前缀可以省略,该信息从配置文件中读取。
1.1 接口说明
可以通过如下命令查看Tachyon所有接口命令
$cd /app/hadoop/tachyon-0.5.0/bin $./tachyon tfs -help

其中大部分的命令含义可以参考Linux下同名命令,命令含义:
| 命令 |
含义 |
| cat |
将文件内容输出到控制台 |
| count |
显示匹配指定的前缀“路径”的文件夹和文件的数量。 |
| ls |
列出指定路径下所有的文件和目录信息,如大小等。 |
| lsr |
递归地列出指定路径下所有的文件和目录信息,如大小等。 |
| mkdir |
在给定的路径创建一个目录,以及任何必要的父目录。如果路径已经存在将会失败。 |
| rm |
删除一个文件。如果是一个目录的路径将会失败。 |
| rmr(0.5.0版本不包含) |
删除一个文件或目录,以及该目录下的所有文件夹和文件 |
| tail |
输出指定文件的最后1 kb到控制台。 |
| touch |
在指定的路径创建一个0字节的文件。 |
| mv |
移动指定的源文件或源目录到一个目的路径。如果目的路径已经存在将会失败。 |
| copyFromLocal |
将本地指定的路径复制到Tachyon中指定的路径。如果Tachyon中指定的路径已经存在将会失败。 |
| copyToLocal |
从Tachyon中指定的路径复制本地指定的路径。 |
| fileinfo |
输出指定文件的块信息。 |
| location |
输出存放指定文件的所在节点列表信息。 |
| report |
向master报告文件丢失 |
| request |
根据指定的dependency ID,请求文件。 |
| pin |
将指定的路径常驻在内存中。如果指定的是一个文件夹,会递归地包含所有文件以及任何在这个文件夹中新创建的文件。 |
| unpin |
撤销指定路径的常驻内存状态。如果指定的是一个文件夹,会递归地包含所有文件以及任何在这个文件夹中新创建的文件。 |
| Free(0.5.0版本不包含) |
释放一个文件或一个文件夹下的所有文件的内存。文件/文件夹在underfs仍然是可用的。 |
1.2 接口操作示例
在操作之前需要把$TACHYON_HOME/bin配置到/etc/profile 配置文件的PATH中,并通过source /etc/profile生效

1.2.1 copyFromLocal
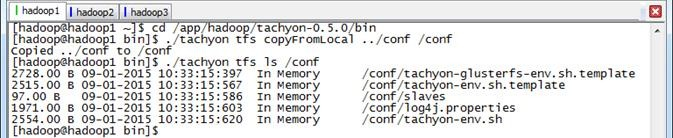
将本地$TACHYON_HOME/conf目录拷贝到Tachyon文件系统的根目录下的conf子目录
$cd /app/hadoop/tachyon-0.5.0/bin $./tachyon tfs copyFromLocal ../conf /conf $./tachyon tfs ls /conf
1.2.2 copyToLocal
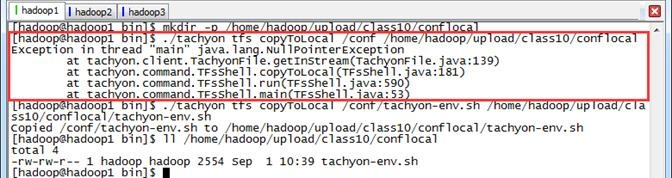
把Tachyon文件系统文件复制到本地,需要注意的是命令中的src必须是Tachyon文件系统中的文件不支持目录拷贝,否则报错无法复制
$mkdir -p /home/hadoop/upload/class10/conflocal $./tachyon tfs copyToLocal /conf /home/hadoop/upload/class10/conflocal $./tachyon tfs copyToLocal /conf/tachyon-env.sh /home/hadoop/upload/class10/conflocal/tachyon-env.sh $ll /home/hadoop/upload/class10/conflocal
1.2.3 ls和lsr
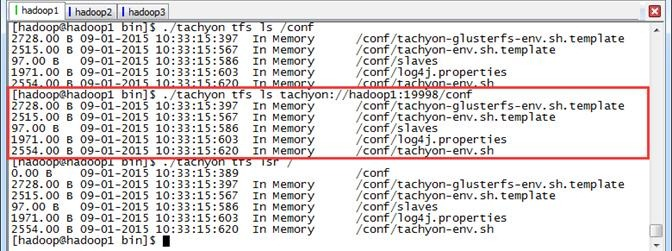
使用ls和lsr命令查看Tachyon文件系统下的文件信息,其中lsr命令可以递归地查看子目录。
$./tachyon tfs ls /conf $./tachyon tfs ls tachyon://hadoop1:19998/conf $./tachyon tfs lsr /
1.2.4 count
统计当前路径下的目录、文件信息,包括文件数、目录树以及总的大小
$./tachyon tfs count /

1.2.5 cat
查看指定文件的内容
$./tachyon tfs cat /conf/slaves $./tachyon tfs cat tachyon://hadoop1:19998/conf/slaves

1.2.6 mkdir、rm、rmr和touch
(1)mkdir:创建目录,支持自动创建不存在的父目录;
(2)rm:删除文件,不能删除目录,注意,递归删除根目录是无效的
(3)rmr:删除目录,支持递归,包含子目录和文件,其中0.5.0版本不提供该命令
(4)touch:创建文件,不能创建已经存在的文件。
$./tachyon tfs mkdir /mydir $./tachyon tfs ls / $./tachyon tfs rm /mydir

$./tachyon tfs touch /mydir/my.txt $./tachyon tfs lsr /mydir $./tachyon tfs rm /mydir/my.txt

$./tachyon tfs touch /mydir2/2/2/my.txt $./tachyon tfs lsr /mydir2 $./tachyon tfs rm /mydir2 $./tachyon tfs rm / $./tachyon tfs ls /

1.2.7 pin和unpin
pin命令将指定的路径常驻在内存中,如果指定的是一个文件夹会递归地包含所有文件以及任何在这个文件夹中新创建的文件。unpin命令撤销指定路径的常驻内存状态。

pin执行前或unpin执行后的Web Interface界面
$./tachyon tfs pin /conf/log4j.properties
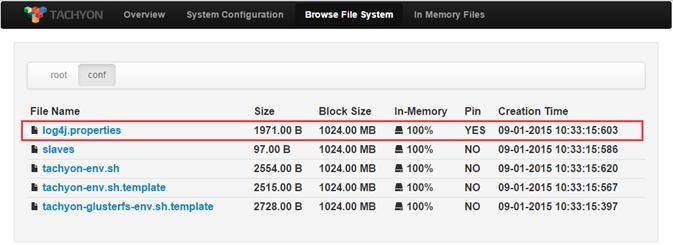
$./tachyon tfs unpin /conf/log4j.properties

本文转自大数据躺过的坑博客园博客,原文链接:http://www.cnblogs.com/zlslch/p/6786338.html,如需转载请自行联系原作者
