热门
让你的文档从静态展示到一键部署可操作验证
一键生成视频!用 PAI-EAS 部署 AI 视频生成模型 SVD 工作流
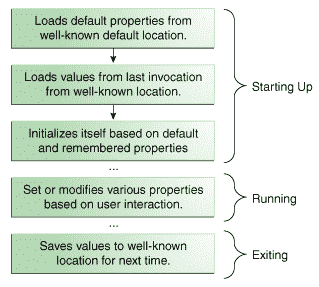
Java 中文官方教程 2022 版(十三)(1)
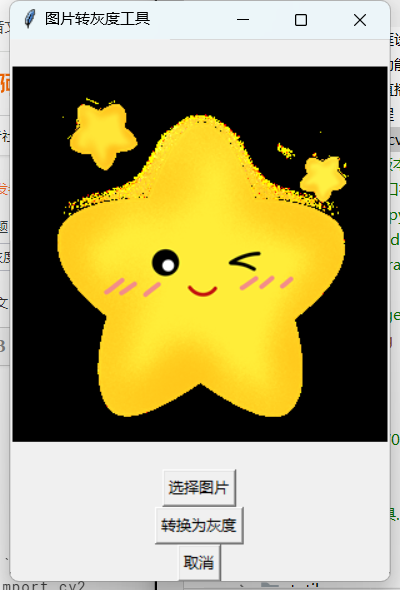
灰度转换工具
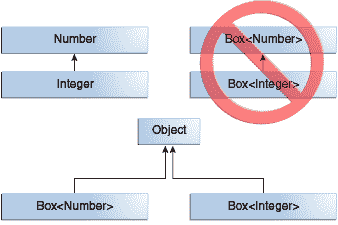
Java 中文官方教程 2022 版(十二)(3)
Java 中文官方教程 2022 版(十二)(1)
Java 中文官方教程 2022 版(十)(4)
Java 中文官方教程 2022 版(十)(3)
Java 中文官方教程 2022 版(十)(2)
Java 中文官方教程 2022 版(十)(1)
人工智能的发展趋势
Java 中文官方教程 2022 版(九)(4)
Java 中文官方教程 2022 版(九)(3)
Java 中文官方教程 2022 版(九)(2)
Java 中文官方教程 2022 版(九)(1)
Java 中文官方教程 2022 版(八)(4)
Java 中文官方教程 2022 版(八)(3)
Java 中文官方教程 2022 版(八)(2)
一阶优化算法启发,北大林宙辰团队提出具有万有逼近性质的神经网络架构的设计方法
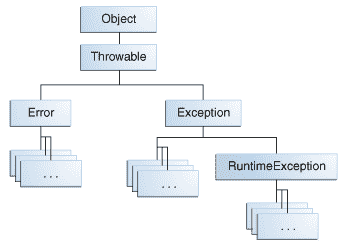
Java基础教程(10)-Java中的异常处理机制
2万亿训练数据,120亿参数!开源大模型Stable LM 2-12B
性能超ChatGPT-3.5,专用金融分析的多模态大语言模型
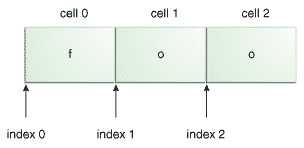
java 数组转字符串 和字符串转int
探索移动应用开发的未来:跨平台工具与原生系统之争
移动应用开发的未来:跨平台框架与原生系统协同进化
构建未来:移动应用中的增强现实技术
Java中的多线程并发编程实践
Java 中文官方教程 2022 版(八)(1)
移动应用开发的未来:跨平台框架与原生系统之争
构建高效微服务架构:从理论到实践
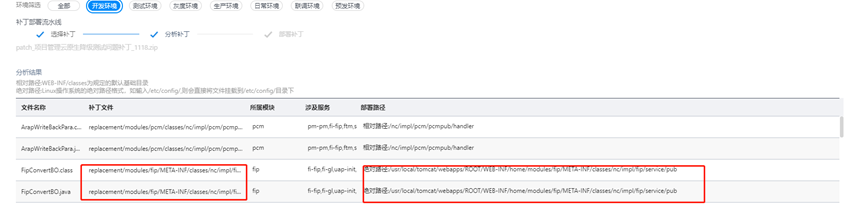
查看补丁有没有生效
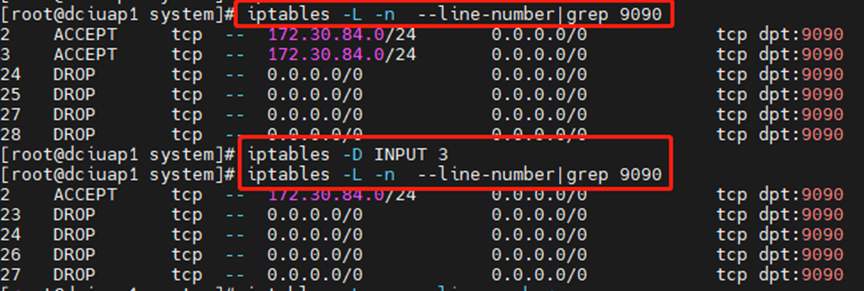
linux白名单设置
Java 中文官方教程 2022 版(七)(4)
构建未来:云原生架构在企业数字化转型中的关键作用
Java 中文官方教程 2022 版(七)(3)
Java 中文官方教程 2022 版(七)(2)
Java 中文官方教程 2022 版(七)(1)
安装技术中台添加主机报错:“免密登录失败”和“hostname设置失败“
深入理解操作系统:进程管理与调度策略
创建oracle备份路径
利用深度学习优化图像识别系统
oracle 修改表空间文件路径方法
oracle阻塞会话与kill
PLSQL查看实际执行计划
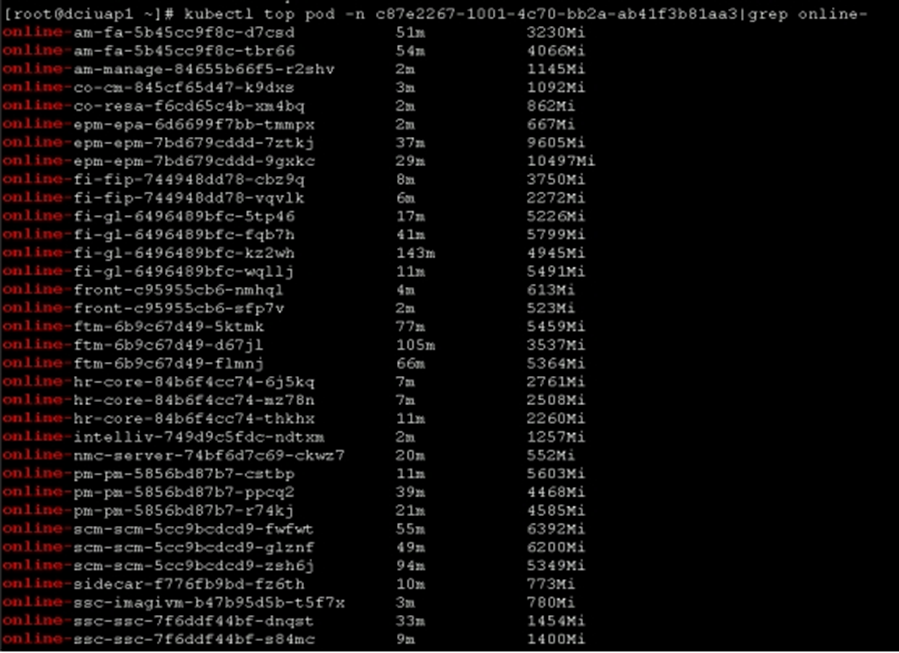
查看pod资源使用情况
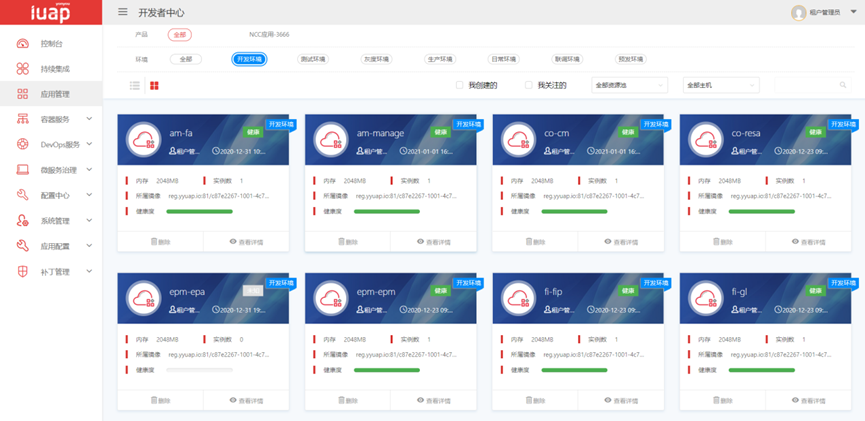
浙江电网ERP系统运维手册
Java 中文官方教程 2022 版(六)(4)
Java 中文官方教程 2022 版(六)(3)
Java 中文官方教程 2022 版(六)(2)
Java 中文官方教程 2022 版(六)(1)