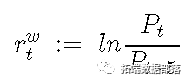热门
提升团队工程交付能力,从“看见”工程活动和研发模式开始
阿里云实时计算Flink的产品化思考与实践【下】
社区供稿 | FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
更优性能与性价比,从自建 ELK 迁移到 SLS 开始
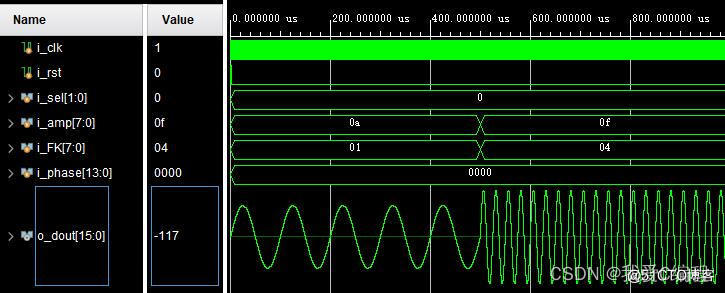
m基于FPGA的多功能信号发生器verilog实现,包含testbench,可以调整波形类型,幅度,频率,初始相位等
xiaodisec day22
【视频】R语言逻辑回归(Logistic回归)模型分类预测病人冠心病风险|数据分享
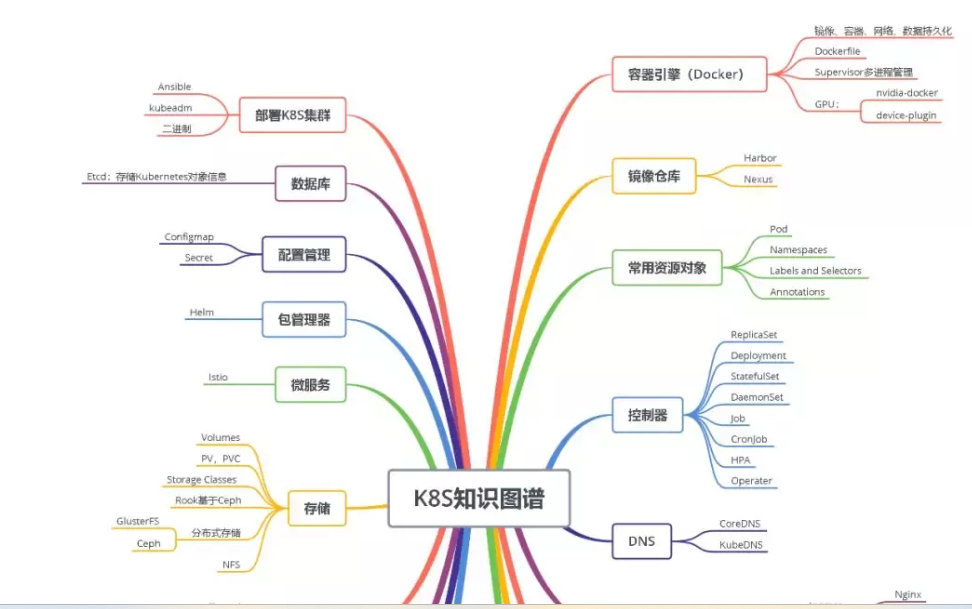
高分通过Kubernetes/k8s CKS认证考试!
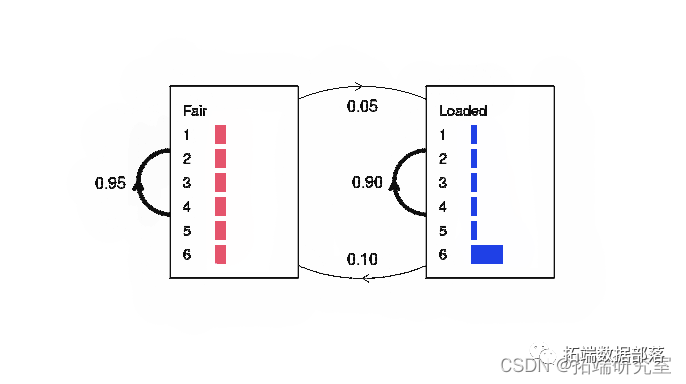
R语言用隐马尔可夫Profile HMM模型进行生物序列分析和模拟可视化
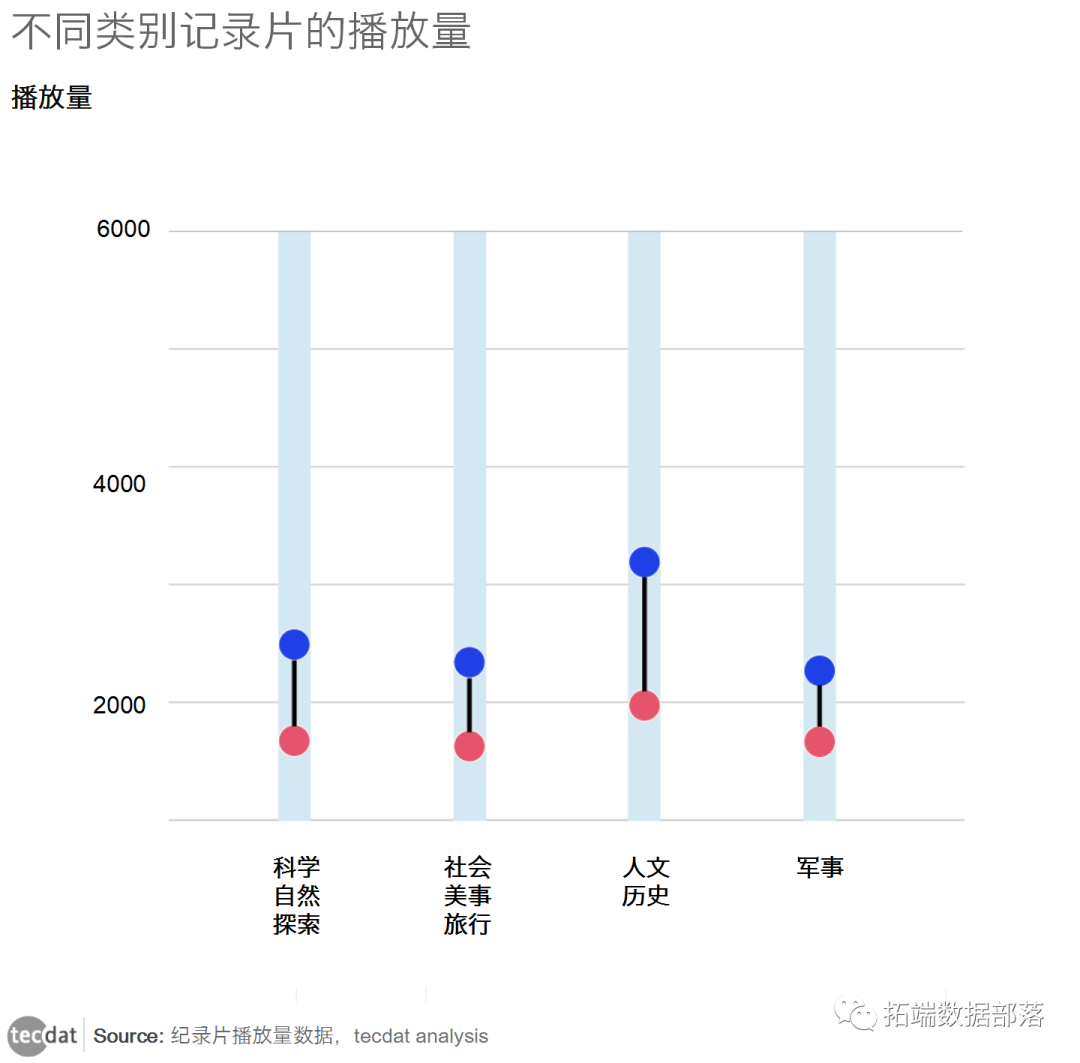
回归树模型分析纪录片播放量影响因素|数据分享
Matlab用向量误差修正VECM模型蒙特卡洛Monte Carlo预测债券利率时间序列和MMSE 预测
【Redis系列笔记】Redis集群
BigDecimal 详解
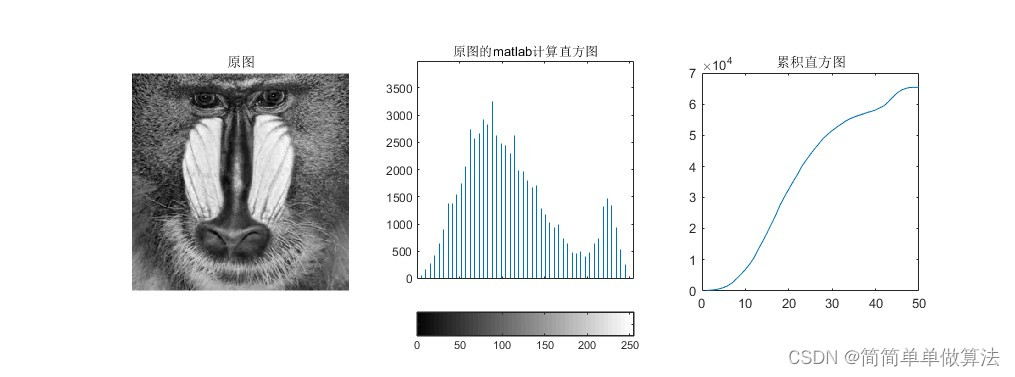
基于FPGA的图像累积直方图verilog实现,包含tb测试文件和MATLAB辅助验证
xiaodisec day021
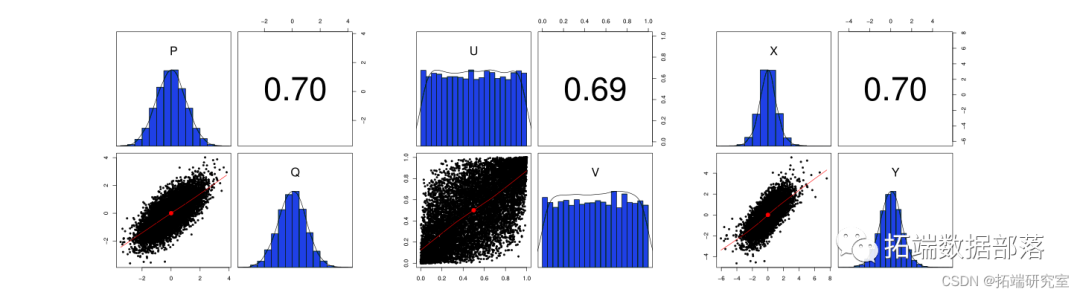
R语言和Python对copula模型Gaussian、t、Clayton 和Gumbel族可视化理论概念和文献计量使用情况
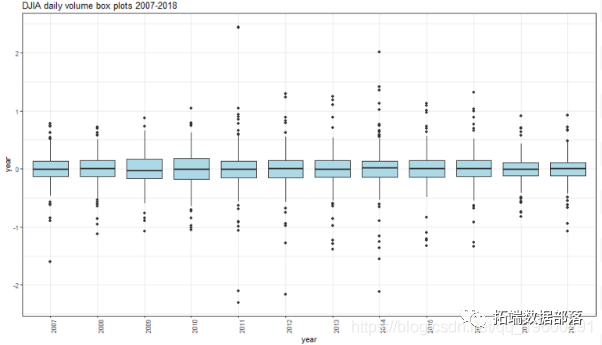
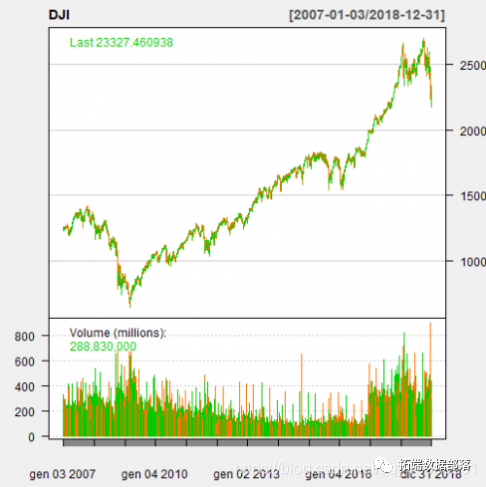
R语言股票市场指数:ARMA-GARCH模型和对数收益率数据探索性分析(下)
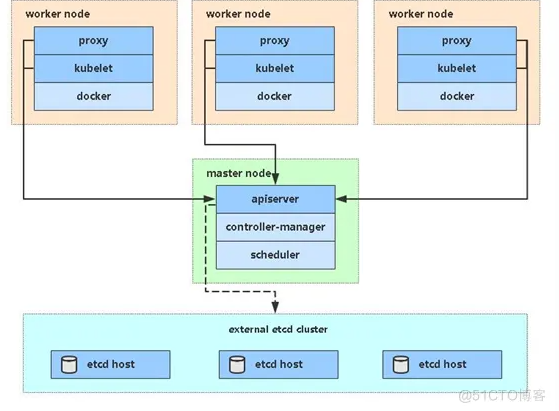
【博客大赛】搭建一套完整的企业级Kubernetes高可用集群(v1.20,二进制)
Docker+Kubernetes/K8s+Jenkins视频资料【干货分享】
R语言股票市场指数:ARMA-GARCH模型和对数收益率数据探索性分析(中)
JavaSE&异常
R语言股票市场指数:ARMA-GARCH模型和对数收益率数据探索性分析(上)
【视频】广义相加模型(GAM)在电力负荷预测中的应用(下)
滚雪球学Java(20):Java泛型与枚举:提升代码灵活性与可读性
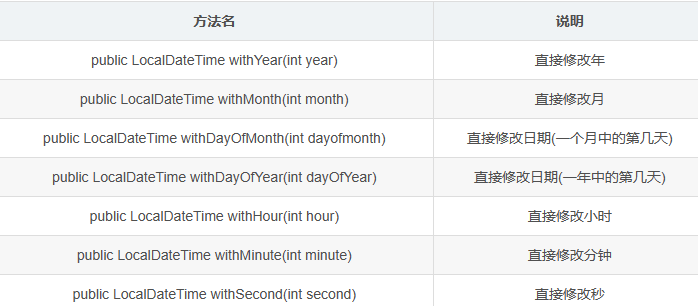
JavaSE&Java8 时间日期API + 使用心得
【视频】广义相加模型(GAM)在电力负荷预测中的应用(上)
如何用基于 Java 配置的方式配置 Spring?
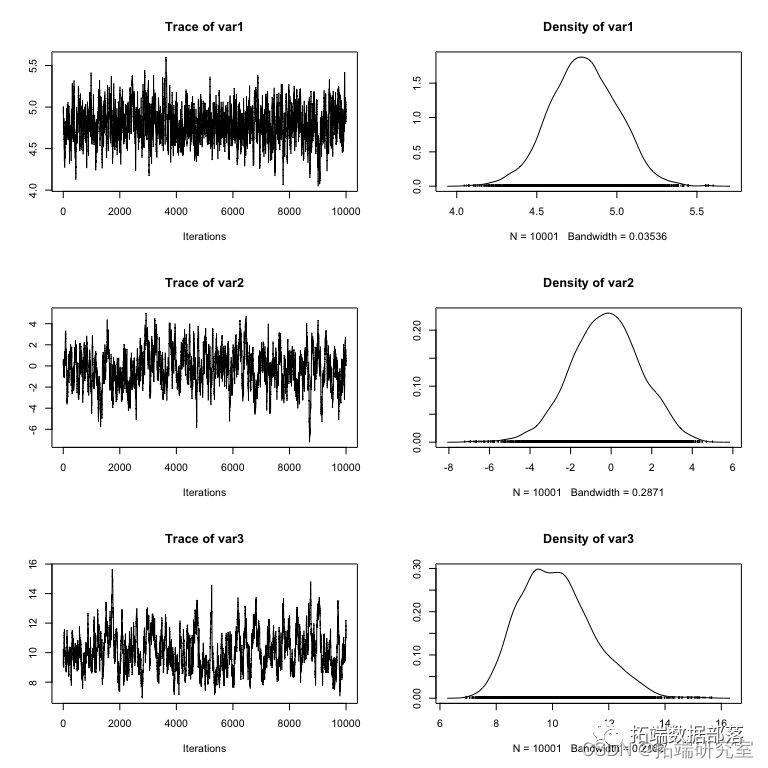
R语言coda贝叶斯MCMC Metropolis-Hastings采样链分析和收敛诊断可视化
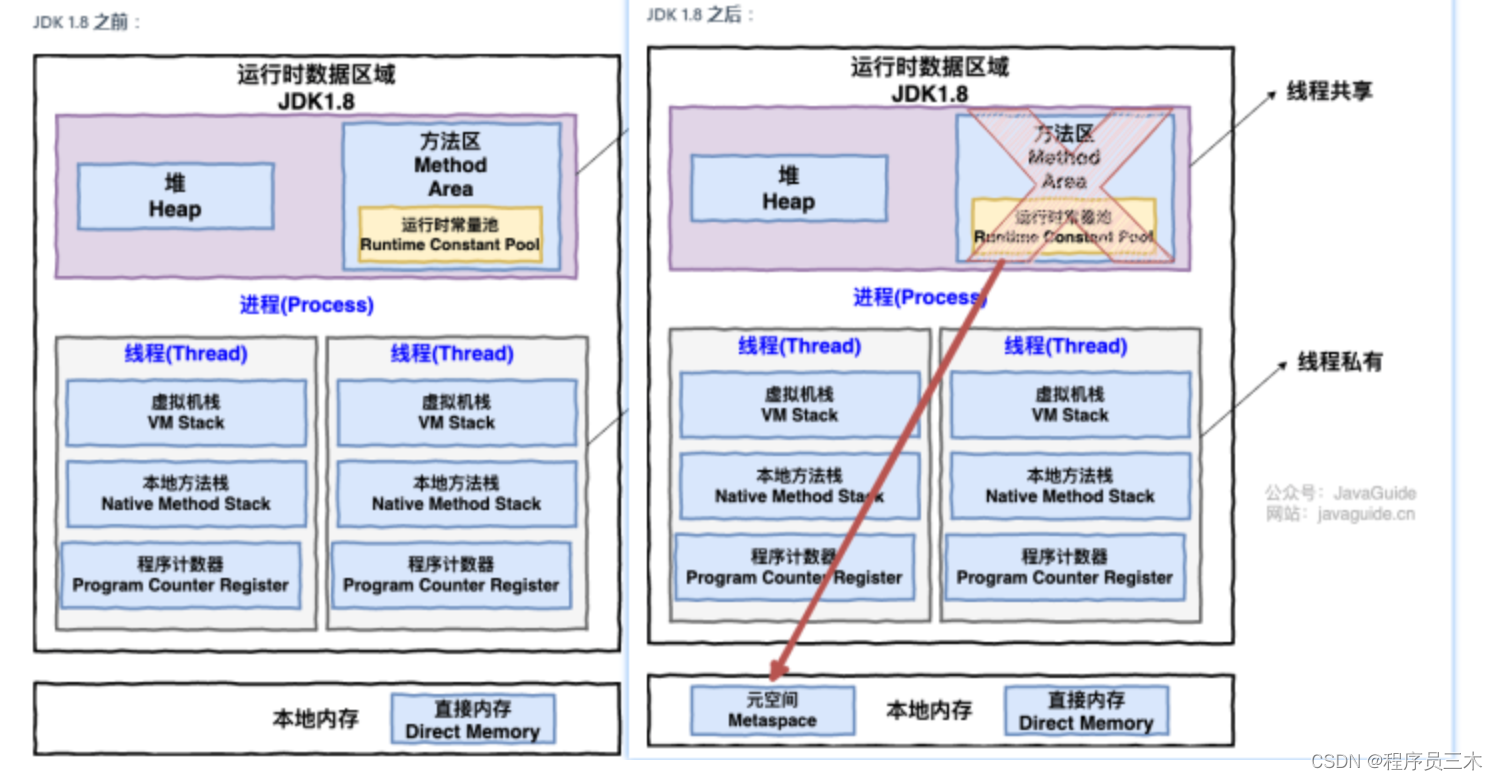
JVM 数据区域
R语言:EM算法和高斯混合模型聚类的实现
JVM 垃圾回收算法(重要)
Java 与垃圾回收有关的方法
JavaSE&Java8 Stream
【视频】KMEANS均值聚类和层次聚类:R语言分析生活幸福指数可视化|数据分享
遥控车模的电机控制器
Flutter 中优雅切换应用主题的组件
[Java 基础面试题] IO相关
【视频】KMEANS均值聚类和层次聚类:R语言分析生活幸福指数可视化|数据分享(上)
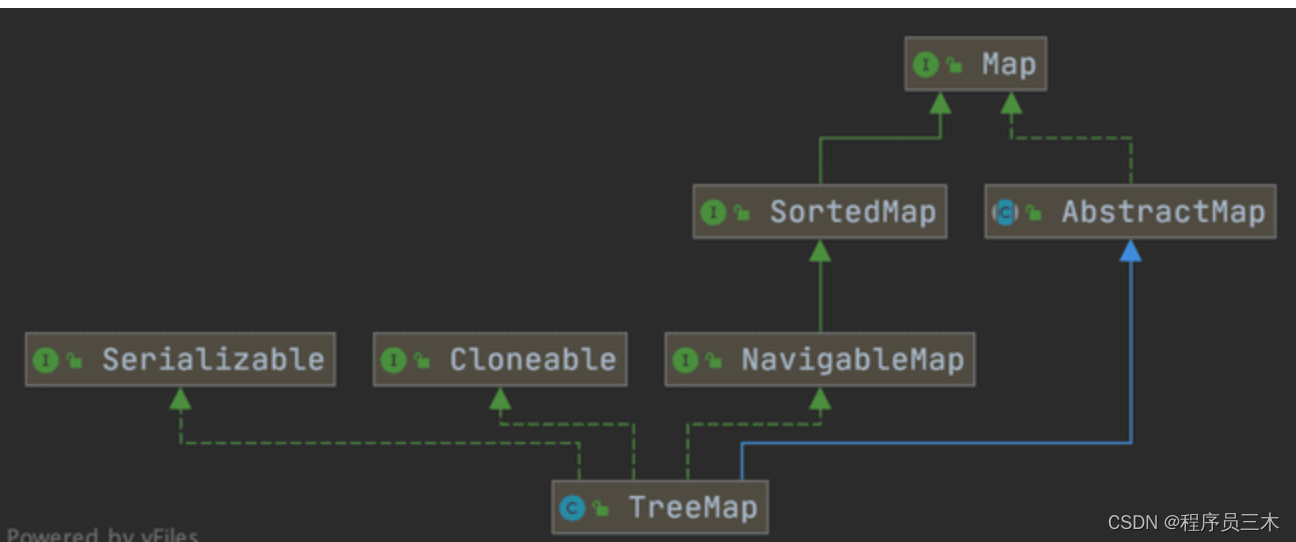
[Java基础面试题] Map 接口相关
R语言逻辑回归、Naive Bayes贝叶斯、决策树、随机森林算法预测心脏病
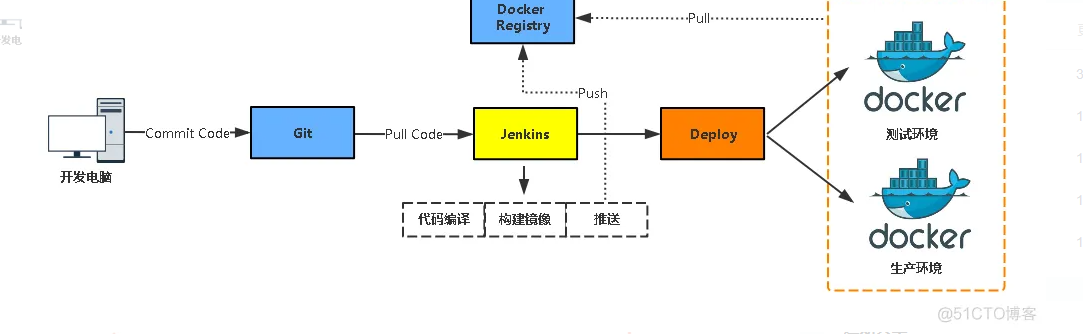
Jenkins与Docker的自动化CI/CD实战
[Java 面试题] ArrayList篇
[leetcode] 快乐数 E
JavaSE&泛型
[leetcode 链表] 反转链表 vs 链表相交
[leetcode] 705. 设计哈希集合
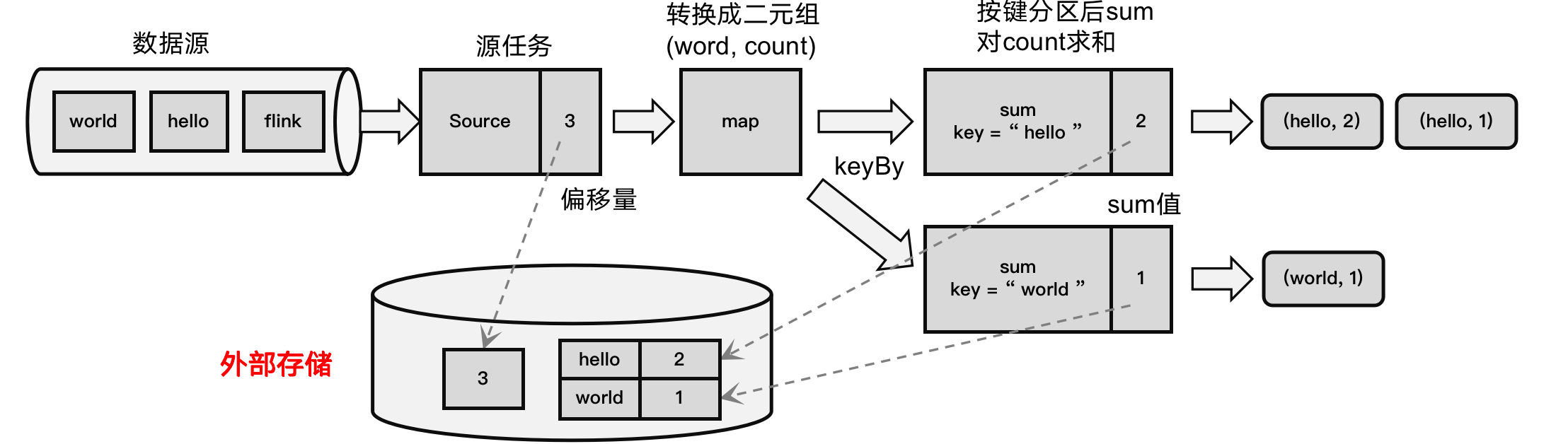
[尚硅谷flink] 检查点笔记
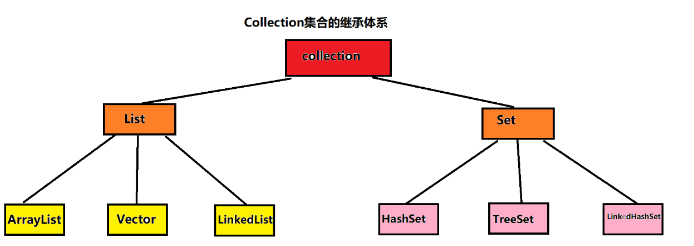
JavaSE&Collection集合
Java堆内存又溢出了!教你一招必杀技
深入理解Java异常处理机制