Cloudera Kudu是什么?
kudu是cloudera在2012开始秘密研发的一款介于hdfs和hbase之间的高速分布式列式存储数据库。兼具了hbase的实时性、hdfs的高吞吐,以及传统数据库的sql支持。作为一款实时、离线之间的存储系统。定位和spark在计算系统中的地位非常相似。如果把mr+hdfs作为离线计算标配,storm+hbase作为实时计算标配。spark+kudu有可能成为未来最有竞争力的一种架构。
也就是kafka -> spark -> kudu这种架构,未来此架构是否会风靡,暂且不言论。让我们拭目以待吧!
Kudu是Cloudera开源的新型列式存储系统,是Apache Hadoop生态圈的新成员之一(incubating),专门为了对快速变化的数据进行快速的分析,填补了以往Hadoop存储层的空缺。
Kudu是Todd Lipcon@Cloudera带头开发的存储系统,其整体应用模式和HBase比较接近,即支持行级别的随机读写,并支持批量顺序检索功能。
Kudu 是一个针对 Apache Hadoop 平台而开发的列式存储管理器。Kudu 共享 Hadoop 生态系统应用的常见技术特性:它在commodity hardware(商品硬件)上运行,horizontally scalable(水平可扩展),并支持 highly available(高可用)性操作。
Kudu的目标是:提供快速的全量数据分析与实时处理功能;充分利用先进CPU与IO资源;支持数据更新;简单、可扩展的数据模型。
Kudu的官网
http://kudu.apache.org/

A new addition to the open source Apache Hadoop ecosystem, Apache Kudu completes Hadoop's storage layer to enablefast analytics on fast data.
背景——功能上的空白
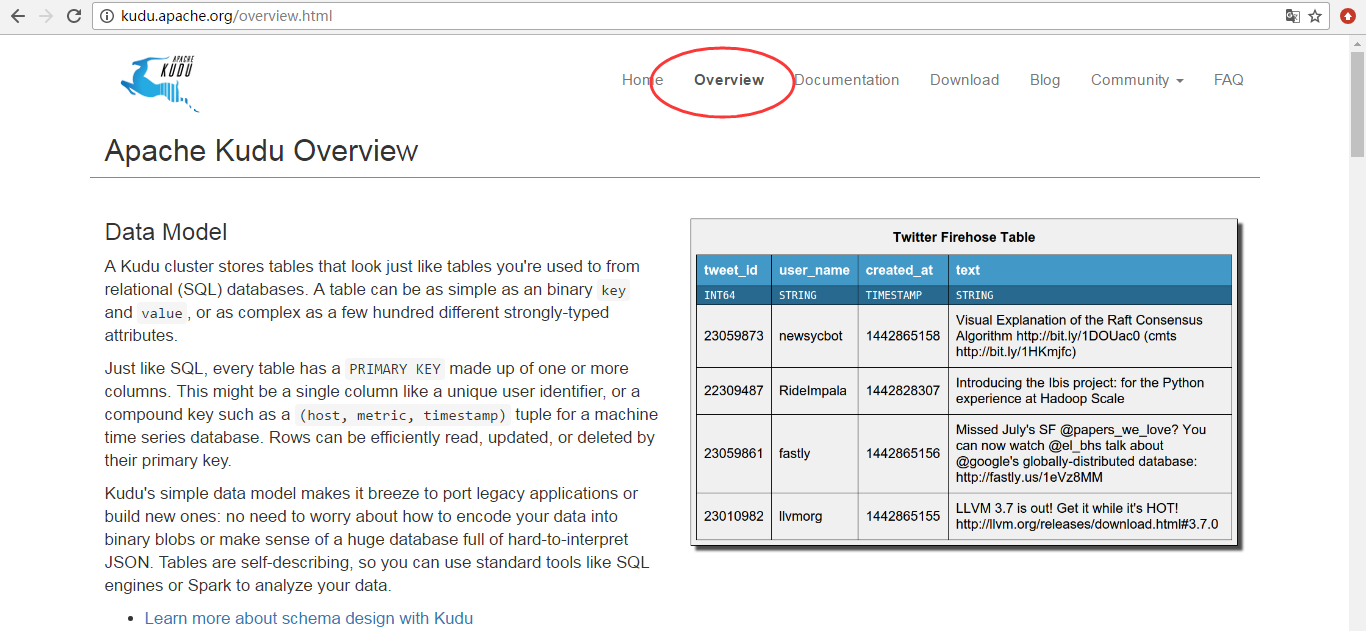
Hadoop 生态系统有很多组件,每一个组件有不同的功能。在现实场景中,用户往往需要同时部署很多 Hadoop 工具来解决同一个问题,这种架构称为 混合架构 (hybrid architecture) 。 比如,用户需要利用 Hbase 的快速插入、快读 random access 的特性来导入数据, HBase 也允许用户对数据进行修改, HBase 对于大量小规模查询也非常迅速。同时,用户使用 HDFS/Parquet + Impala/Hive 来对超大的数据集进行查询分析,对于这类场景, Parquet 这种列式存储文件格式具有极大的优势。
很多公司都成功地部署了 HDFS/Parquet + HBase 混合架构,然而这种架构较为复杂,而且在维护上也十分困难。首先,用户用 Flume 或 Kafka 等数据 Ingest 工具将数据导入 HBase ,用户可能在 HBase 上对数据做一些修改。然后每隔一段时间 ( 每天或每周 ) 将数据从 Hbase 中导入到 Parquet 文件,作为一个新的 partition 放在 HDFS 上,最后使用 Impala 等计算引擎进行查询,生成最终报表。
这样一条工具链繁琐而复杂,而且还存在很多问题,比如:
(1)如何处理某一过程出现失败?
(2)从 HBase 将数据导出到文件,多久的频率比较合适?
(3)当生成最终报表时,最近的数据并无法体现在最终查询结果上。
(4)维护集群时,如何保证关键任务不失败?
(5)Parquet 是 immutable ,因此当 HBase 中删改某些历史数据时,往往需要人工干预进行同步。
这时候,用户就希望能够有一种优雅的存储解决方案,来应付不同类型的工作流,并保持高性能的计算能力。 Cloudera 很早就意识到这个问题,在 2012 年就开始计划开发 Kudu 这个存储系统,终于在 2015 年发布并开源出来。 Kudu 是对 HDFS 和 HBase 功能上的补充,能提供快速的分析和实时计算能力,并且充分利用 CPU 和 I/O 资源,支持数据原地修改,支持简单的、可扩展的数据模型。
背景——新的硬件设备
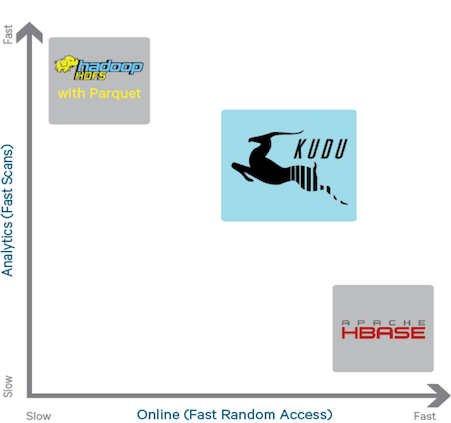
RAM 的技术发展非常快,它变得越来越便宜,容量也越来越大。 Cloudera 的客户数据显示,他们的客户所部署的服务器, 2012 年每个节点仅有 32GB RAM ,现如今增长到每个节点有 128GB 或 256GB RAM 。存储设备上更新也非常快, 在很多普通服务器中部署 SSD 也是屡见不鲜。 HBase 、 HDFS 、以及其他的 Hadoop 工具都在不断自我完善,从而适应硬件上的升级换代。然而,从根本上, HDFS 基于 03 年 GFS , HBase 基于 05 年 BigTable ,在当时系统瓶颈主要取决于底层磁盘速度。当磁盘速度较慢时, CPU 利用率不足的根本原因是磁盘速度导致的瓶颈,当磁盘速度提高了之后, CPU 利用率提高,这时候 CPU 往往成为系统的瓶颈。 HBase 、 HDFS 由于年代久远,已经很难从基本架构上进行修改,而 Kudu 是基于全新的设计,因此可以更充分地利用 RAM 、 I/O 资源,并优化 CPU 利用率。我们可以理解为, Kudu 相比与以往的系统, CPU 使用降低了, I/O 的使用提高了, RAM 的利用更充分了。
1. Kudu的简介
Kudu 设计之初,是为了解决一下问题:
- 对数据扫描 (scan) 和随机访问 (random access) 同时具有高性能,简化用户复杂的混合架构;
- 高 CPU 效率,使用户购买的先进处理器的的花费得到最大回报;
- 高 IO 性能,充分利用先进存储介质;
- 支持数据的原地更新,避免额外的数据处理、数据移动。
2. Kudu支持跨数据中心 replication
Kudu 的很多特性跟 HBase 很像,它支持索引键的查询和修改。 Cloudera 曾经想过基于 Hbase 进行修改,然而结论是对 HBase 的改动非常大, Kudu 的数据模型和磁盘存储都与 Hbase 不同。 HBase 本身成功的适用于大量的其它场景,因此修改 HBase 很可能吃力不讨好。最后 Cloudera 决定开发一个全新的存储系统。
3. Kudu的对外接口
Kudu 提供 C++ 和 JAVA API ,可以进行单条或批量的数据读写, schema 的创建修改。除此之外, Kudu 还将与 hadoop 生态圈的其它工具进行整合。目前, kudu beta 版本对 Impala 支持较为完善,支持用 Impala 进行创建表、删改数据等大部分操作。 Kudu 还实现了 KuduTableInputFormat 和 KuduTableOutputFormat ,从而支持 Mapreduce 的读写操作。同时支持数据的 locality(本地性) 。目前对 spark 的支持还不够完善, spark 只能进行数据的读操作。
4. 节点
Kudu-master:主节点,维护存储表元数据,跟踪协调所有的tserver的状态和数据,安装奇数节点(最少三个)。
Kudu-tserver:从节点,存储具体表数据的节点,一个表数据可以有多个副本,但只有一个leader才能负责写请求,leader和follower都可以负责读请求。安装最少三个节点。
使用案例——小米
为什么这里用小米来作为案例,是因为小米在Kudu走在前列。
小米是Hbase的重度用户,他们每天有约50亿条用户记录。小米目前使用的也是HDFS + HBase这样的混合架构。可见该流水线相对比较复杂,其数据存储分为SequenceFile,Hbase和Parquet。
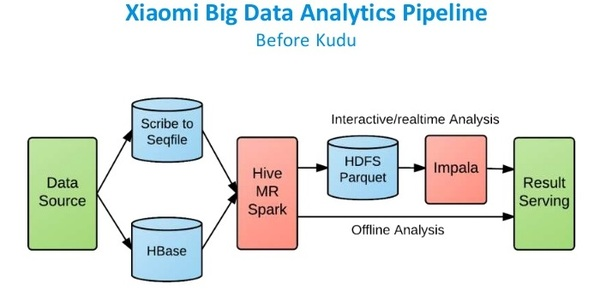
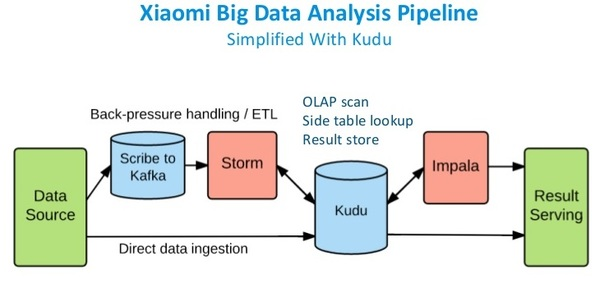
在使用Kudu以后,Kudu作为统一的数据仓库,可以同时支持离线分析和实时交互分析。如下:
本文转自大数据躺过的坑博客园博客,原文链接:http://www.cnblogs.com/zlslch/p/7606997.html,如需转载请自行联系原作者