【简介】
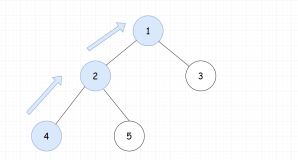
对于有根树T的两个结点u、v,最近公共祖先LCA(T,u,v)表示一个结点x,满足x是u、v的祖先且x的深度尽可能大。
另一种理解方式是把T理解为一个无向无环图,而LCA(T,u,v)即u到v的最短路上深度最小的点。
例如,对于下面的树,结点4和结点6的最近公共祖先LCA(T,4,6)为结点2。

求树中两个结点的最低公共祖先是面试中经常出现的一个问题。一般的做法,可能是针对是否为二叉查找树分情况讨论。
LCA问题的扩展主要在于结点是否只包含父结点指针,对于同一棵树是否进行多次LCA查询。下面分别进行说明。
【二叉查找树情况】
【创建二叉查找树】
// 二叉查找树节点
struct TreeNode {
int val;
TreeNode *left;
TreeNode *right;
TreeNode(int x) : val(x), left(NULL), right(NULL) {}
};
// 插入
void TreeInsert(TreeNode*& root,int val){
// 创建新节点
TreeNode* node = new TreeNode(val);
// 空树
if(root == NULL){
root = node;
return;
}//if
TreeNode *pre = NULL;
TreeNode *p = root;
// 寻找插入位置
while(p){
// 父节点
pre = p;
// 沿左子树方向下降
if(val < p->val){
p = p->left;
}//if
// 沿右子树方向下降
else{
p = p->right;
}//else
}//while
// 左子结点处插入
if(val < pre->val){
pre->left = node;
}//if
// 右子结点处插入
else{
pre->right = node;
}//else
}
【思路】
- 如果当前结点t 大于结点u、v,说明u、v都在t 的左侧,所以它们的共同祖先必定在t 的左子树中,故从t 的左子树中继续查找;
- 如果当前结点t 小于结点u、v,说明u、v都在t 的右侧,所以它们的共同祖先必定在t 的右子树中,故从t 的右子树中继续查找;
- 如果当前结点t 满足 u <t < v,说明u和v分居在t 的两侧,故当前结点t 即为最近公共祖先;
- 而如果u是v的祖先,那么返回u的父结点,同理,如果v是u的祖先,那么返回v的父结点。

【版本一递归版】
这个版本默认要查找节点u,v在root树中
// 最近公共祖先
TreeNode *LCA(TreeNode *root,TreeNode *u,TreeNode *v){
// 空树
if(root == nullptr || u == nullptr || v == nullptr){
return nullptr;
}//if
// u < t < v or v < t < u
if((u->val < root->val && root->val < v->val) ||
(v->val < root->val && root->val < u->val)){
return root;
}//if
// u < root and v < root left sub tree
if(u->val < root->val && v->val < root->val){
// u是v祖先 or v是u的祖先
if(root->left == u || root->left == v){
return root;
}//if
return LCA(root->left,u,v);
}//if
// u > root and v > root right sub tree
if(u->val > root->val && v->val > root->val){
// u是v祖先 or v是u的祖先
if(root->right == u || root->right == v){
return root;
}//if
return LCA(root->right,u,v);
}//if
return nullptr;
}
【版本二迭代版】
/**--------------------------------
* 日期:2015-02-02
* 作者:SJF0115
* 题目: 最近公共祖先(LCA)迭代版
* 博客:
------------------------------------**/
TreeNode *LCA(TreeNode *root,TreeNode *u,TreeNode *v){
// 空树
if (root == nullptr || u == nullptr || v == nullptr) {
return nullptr;
}//if
TreeNode *leftNode = u;
TreeNode *rightNode = v;
TreeNode *parentNode = nullptr;
//二叉查找树内,如果左结点大于右结点,不对,交换
if (leftNode->val > rightNode->val) {
TreeNode *tmp = leftNode;
leftNode = rightNode;
rightNode = tmp;
}//if
while(root){
// u < t < v or v < t < u 在root两侧
if(leftNode->val < root->val && root->val < rightNode->val){
return root;
}//if
// u < root v < root left sub tree
if(rightNode->val < root->val){
parentNode = root;
root = root->left;
}//if
// u > root v > root right sub tree
else if(leftNode->val > root->val){
parentNode = root;
root = root->right;
}
// u是v祖先 or v是u的祖先
else if(root == leftNode || root == rightNode){
return parentNode;
}
}//while
return nullptr;
}
【普通二叉树】
【版本一】
所谓共同的父结点,就是两个结点都出现在这个结点的子树中。因此我们可以定义一函数,来判断一个结点的子树中是不是包含了另外一个结点。
这不是件很难的事,我们可以用递归的方法来实现:
// root树中是否包含节点node
bool Exits(TreeNode *root,TreeNode *node){
// find the node
if(root == node){
return true;
}//if
// left sub tree
bool isExits = false;
if(root->left){
isExits = Exits(root->left,node);
}//if
// right sub tree
if(!isExits && root->right){
isExits = Exits(root->right,node);
}//if
return isExits;
}
我们可以从根结点开始,判断以当前结点为根的树中左右子树是不是包含我们要找的两个结点。如果两个结点都出现在它的左子树中,那最低的共同父结点也出现在它的左子树中。如果两个结点都出现在它的右子树中,那最低的共同父结点也出现在它的右子树中。如果两个结点一个出现在左子树中,一个出现在右子树中,那当前的结点就是最低的共同父结点。
// 最近公共祖先
TreeNode *LCA(TreeNode *root,TreeNode *u,TreeNode *v){
// 空树
if(root == nullptr || u == nullptr || v == nullptr){
return nullptr;
}//if
// check whether left child has u and v
bool leftHasNode1 = false;
bool leftHasNode2 = false;
if(root->left){
leftHasNode1 = Exits(root->left,u);
leftHasNode2 = Exits(root->left,v);
}//if
if(leftHasNode1 && leftHasNode2){
if(root->left == u || root->left == v){
return root;
}//if
return LCA(root->left,u,v);
}//if
// check whether right child has u and v
bool rightHasNode1 = false;
bool rightHasNode2 = false;
if(root->right){
if(!leftHasNode1){
rightHasNode1 = Exits(root->right,u);
}//if
if(!leftHasNode2){
rightHasNode2 = Exits(root->right,v);
}//if
}//if
if(rightHasNode1 && rightHasNode2){
if(root->right == u || root->right == v){
return root;
}//if
return LCA(root->right,u,v);
}//if
// both left and right child has
if((leftHasNode1 && rightHasNode2) || (leftHasNode2 && rightHasNode1)){
return root;
}//if
return nullptr;
}
接着我们来分析一下这个方法的效率。函数 Exits 的本质就是遍历一棵树,其时间复杂度是 O(n) ( n 是树中结点的数目)。由于我们根结点开始,要对每个结点调用函数 Exits 。因此总的时间复杂度是 O(n^2) 。
我们仔细分析上述代码,不难发现我们判断以一个结点为根的树是否含有某个结点时,需要遍历树的每个结点。
接下来我们判断左子结点或者右结点为根的树中是否含有要找结点,仍然需要遍历。第二次遍历的操作其实在前面的第一次遍历都做过了。
由于存在重复的遍历,本方法在时间效率上肯定不是最好的。
【版本二】
前面我们提过如果结点中有一个指向父结点的指针,我们可以把问题转化为求两个链表的共同结点。现在我们可以想办法得到这个链表。我们在本面试题系列的第4题中分析过如何得到一条中根结点开始的路径。我们在这里稍作变化即可:
/**--------------------------------
* 日期:2015-02-02
* 作者:SJF0115
* 题目: 从根节点到目标节点的路径
------------------------------------**/
bool NodePath (TreeNode* root,TreeNode* node,vector<TreeNode*> &path) {
if(root == node) {
return true;
}//if
path.push_back(root);
bool isExits = false;
// left sub tree
if(root->left) {
isExits = NodePath(root->left,node,path);
}//if
if(!isExits && root->right) {
isExits = NodePath(root->right,node,path);
}//if
if(!isExits) {
path.pop_back();
}//if
return isExits;
}
由于这个路径是从跟结点开始的。最低的共同父结点就是路径中的最后一个共同结点:
/*-------------------------------------
* 日期:2015-04-24
* 作者:SJF0115
* 题目: 最小公共祖先
* 博客:
------------------------------------*/
#include <iostream>
#include <vector>
using namespace std;
struct TreeNode{
int val;
TreeNode *left;
TreeNode *right;
TreeNode *parent;
TreeNode(int x):val(x),left(nullptr),right(nullptr),parent(nullptr){}
};
/*
题目:
给定两个节点,求它们在一棵二叉树中的最小公共祖先。
每个节点除了有左右节点之外,还有一个指向父节点的指针
*/
// 找到u,v在二叉树中对应的节点
bool FindPath(TreeNode* root,TreeNode* node,vector<TreeNode*> &path){
if(root == nullptr || node == nullptr){
return false;
}//if
path.push_back(root);
// 找到目标节点
if(root == node){
return true;
}//if
bool isFind = false;
// 左子树中查找
if(root->left){
isFind = FindPath(root->left,node,path);
}//if
// 右子树查找(左子树中未找到的情况下)
if(!isFind && root->right){
isFind = FindPath(root->right,node,path);
}//if
// 左右子树均未找到
if(!isFind){
path.pop_back();
}//if
return isFind;
}
TreeNode* LCA(TreeNode* root,TreeNode* u,TreeNode* v){
vector<TreeNode*> path1,path2;
// 根节点到u的路径
bool isFound1 = FindPath(root,u,path1);
// 根节点到v的路径
bool isFound2 = FindPath(root,v,path2);
// 二叉树中是否存在uv节点
if(!isFound1 || !isFound2){
return nullptr;
}//if
int size1 = path1.size();
int size2 = path2.size();
TreeNode* node = nullptr;
for(int i = 0,j = 0;i <= size1 && j <= size2;++i,++j){
if(i == size1 || j == size2 || path1[i] != path2[j]){
node = path1[i-1];
break;
}//if
}//for
return node;
}
int main(){
TreeNode* root = new TreeNode(0);
TreeNode* node1 = new TreeNode(1);
TreeNode* node2 = new TreeNode(2);
TreeNode* node3 = new TreeNode(3);
TreeNode* node4 = new TreeNode(4);
TreeNode* node5 = new TreeNode(5);
TreeNode* node6 = new TreeNode(6);
root->left = node1;
root->right = node2;
node1->left = node3;
node1->right = node4;
node2->right = node5;
node4->left = node6;
vector<TreeNode*> path;
if(FindPath(root,node5,path)){
for(int i = 0;i < path.size();++i){
cout<<path[i]->val<<" ";
}//for
cout<<endl;
}//if
path.clear();
if(FindPath(root,node6,path)){
for(int i = 0;i < path.size();++i){
cout<<path[i]->val<<" ";
}//for
cout<<endl;
}//if
TreeNode* parent = LCA(root,node5,node6);
cout<<parent->val<<endl;
return 0;
}
这种思路的时间复杂度是 O(n) ,时间效率要比第一种方法好很多。但同时我们也要注意到,这种思路需要两个链表来保存路径,空间效率比不上第一个方法。