据我所知,很多商业经理会说他们的产品使用了人工神经网络和深度学习。显然他们肯定不会说产品使用了“连接圆模型”(Connected Circles Models)或者“失败-惩罚-修正模型”(Fail and Be Penalized Machines)。但毫无疑问,人工神经网络已经在图像识别、自然语言处理等许多领域取得了成功的应用。
作为一个并未完全理解这些技术的专业数据科学家,就像一个没有工具的建筑工人,这让我感到很羞愧。因此,我弥补了这些缺失的功课,并写下这篇文章来帮助别人克服那些我在学习过程中遇到的困难和难题。
注意:本文示例中的R代码可以在 https://github.com/ben519/MLPB/blob/master/Problems/Classify%20Images%20of%20Stairs/intro_to_nnets_article_materials.R找到。
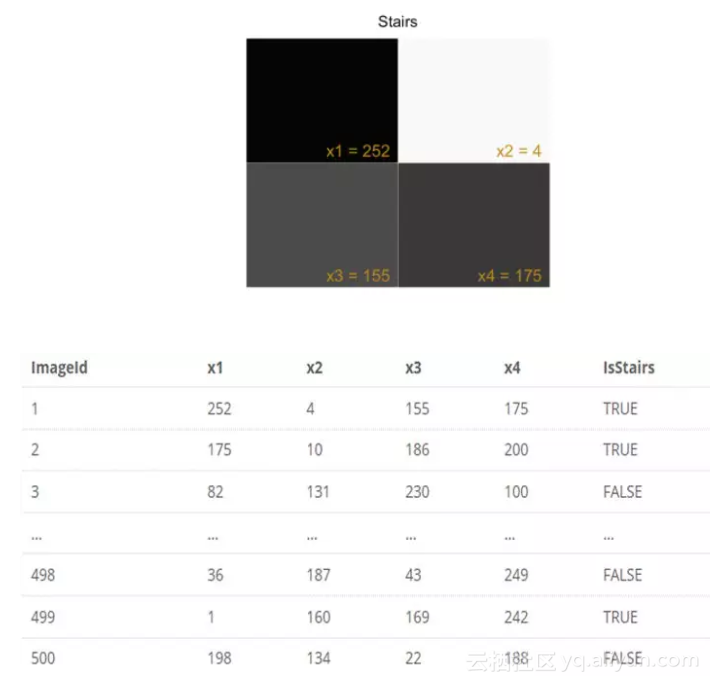
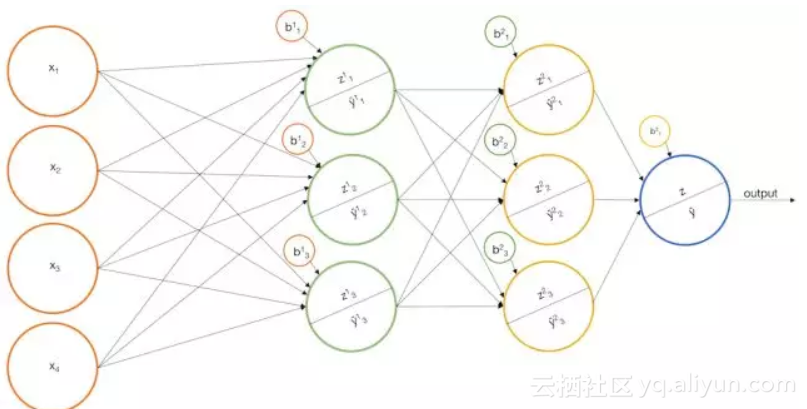
我们从一个激励问题开始。在这里,我们收集了2*2网格像素的灰度图像,每个像素的灰度值在0(白)至255(黑)之间。目标是建立一个识别“阶梯”模式的网络模型。

首先,我们关心的是如何找到一个能够合理拟合数据的模型,至于拟合方法,后面再考虑。
预处理
对每一个图像,给像素打上x1,x2,x3,x4 的标签并且生成一个输入向量喂给模型。希望我们的模型可以把有阶梯模式的图像预测为True,没有阶梯模式的图像预测为False。
单层感知机(模型迭代0)
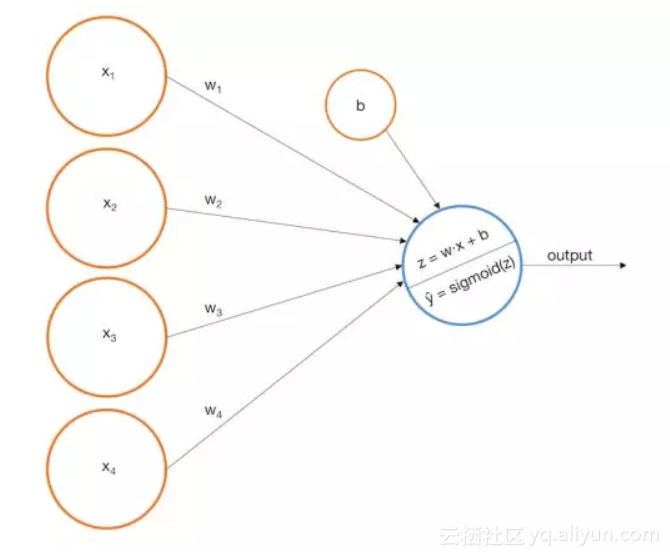
我们可以构建一个简单的单层感知机模型,它使用输入的加权线性组合返回预测分数。如果预测分数大于选定的阈值,则预测为1,反之预测为0。更正式的表达式如下:
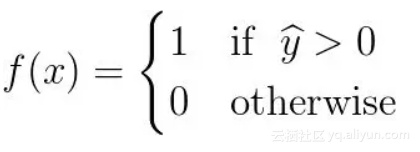
我们重新表述如下:
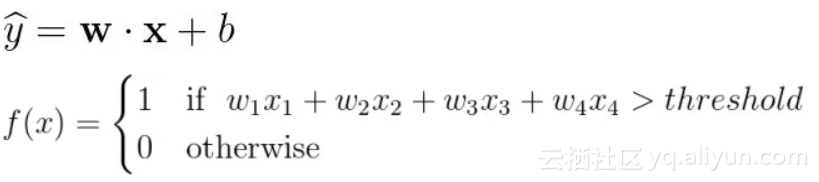
即为我们的预测分数。
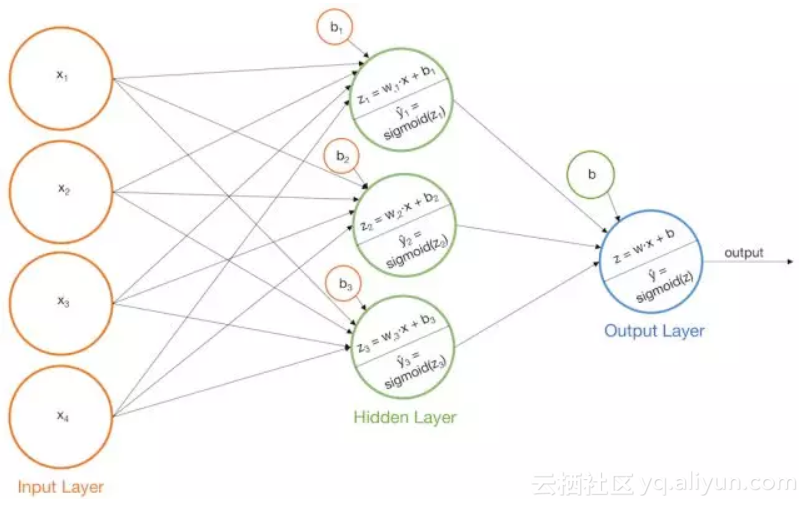
更形象的描述,我们可以把输入节点喂给输出节点来表示一个感知机。
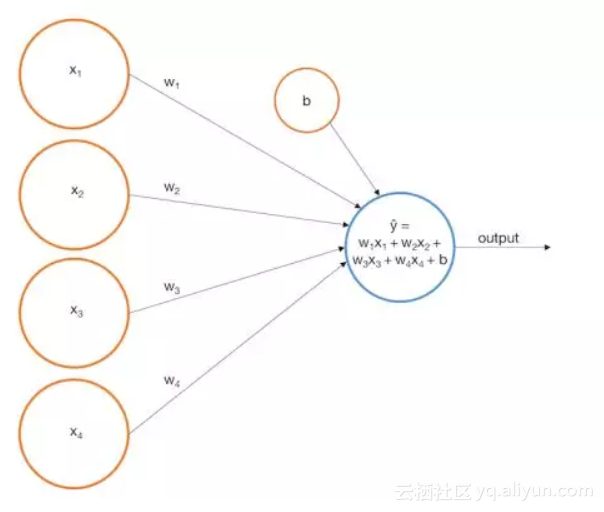
对应于我们的例子,假设我们建立了如下的模型:
![]()
下面是感知机如何在我们训练图像上执行:
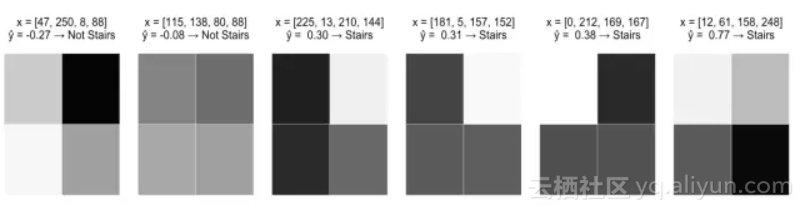
这肯定比随机猜测好,而且有一定的逻辑性。在所有阶梯模式的底部都有深色阴影像素,这也对应着x3和x4有较大的正系数。但是,这个模型还是有一些明显的问题:
问题 1.1:这个模型输出一个与似然概念相关的实数(更高的值意味着图像代表阶梯的概率更大),但是将这些值解释为概率是没有依据的,特别是因为它们可能超出范围[ 0, 1 ]。
问题 1.2:这个模型不能捕捉到变量和目标之间的非线性关系,为了看到这个问题,可以考虑一下下面的假设场景:
案例一:从一个图像开始x = [100, 0, 0, 125],x3 从0增加至60。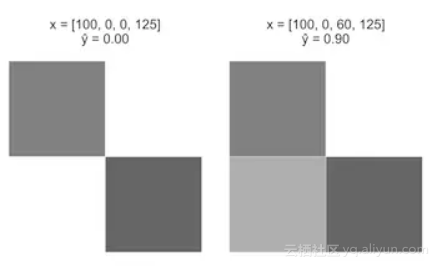
直观上来看,案例一应该比案例二在上有更大的增长,但是我们的感知机模型是线性方程,在 x3 的等效+ 60的变化导致这两种情况下的
等效+ 0.12。
虽然我们的线性感知机还有很多的问题,但是我们先从解决这两个问题开始。
具有Sigmoid激活函数的单层感知机
(模型迭代1)
我们可以通过在感知机中加Sigmoid激活函数来解决上面的问题1.1和问题1.2。回想一下,Sigmoid函数是一个S形曲线,在0和1之间的垂直轴上有界,因此经常被用来模拟二元事件的概率。
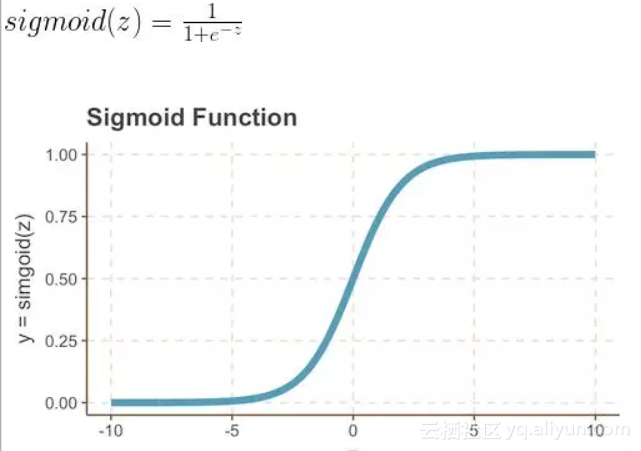
按照这个想法,我们可以用下面的图片和等式更新我们的模型:
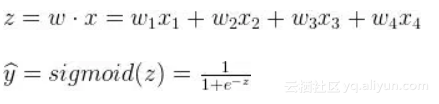
看起来有点熟悉?没错,这就是逻辑回归。然而,将模型解释为具有Sigmoid“激活函数”的线性感知器是更合适的,因为这样可以给我们更多的空间去推广。另外,我们现在把解释为概率,那必须相应更新我们的决策规则。
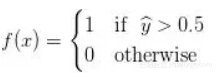
继续我们的示例问题,假设我们提出以下拟合模型:

观察该模型如何在前一节中的同一示例图像上运行:
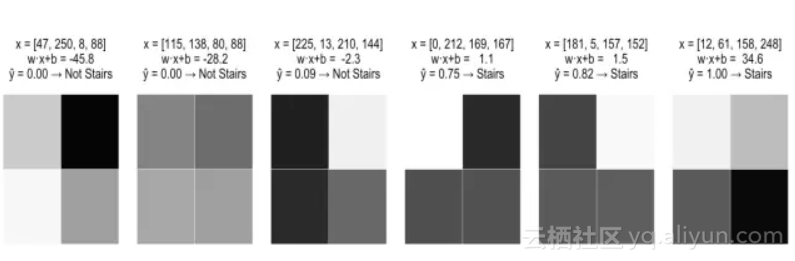
很明显,已经解决了上面的问题1.1,继续看如何解决问题1.2:
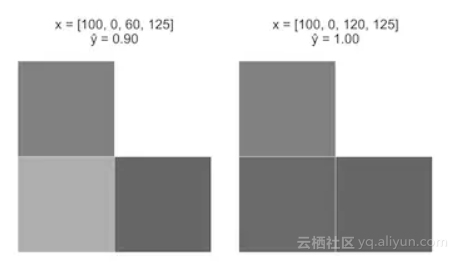
案例一:从一个图像开始x = [100, 0, 0, 125],x3 从0增加至60。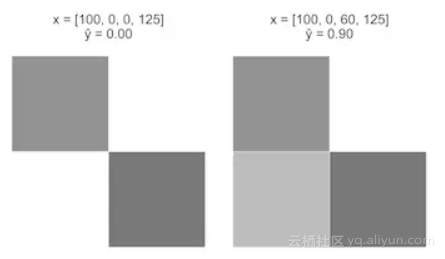
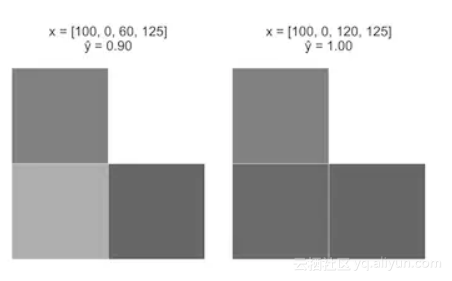
注意,当增加时,Sigmoid函数的曲率如何引起案例一“点亮”的(迅速增加)。但是随着z继续增加,增长的速度就变得缓慢了。这符合我们的直觉,即与案例二相比,案例一是阶梯的概率增长幅度更大。
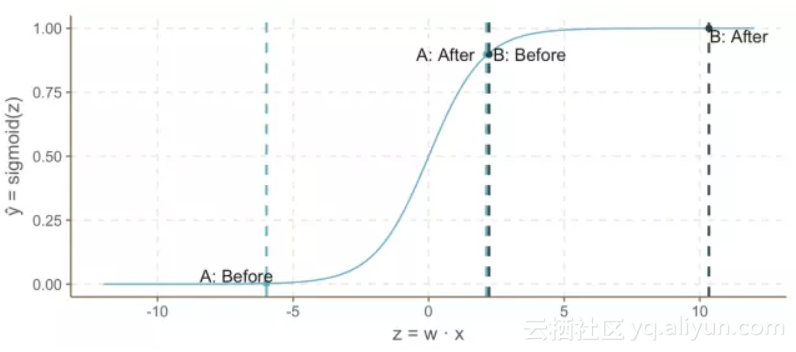
然而,这个模型还是存在问题:
问题 2.1:与每个变量是单调关系,如果我们想要辨识轻微的阴影阶梯该怎么办呢?
问题 2.2:该模型没有考虑变量之间的关系,假定图像底部一行是黑色,又如果左上角的像素是白色的,那么右上角的像素变暗会增加图像是阶梯的概率。如果左上角的像素是黑色的,右上角的像素变暗则会降低图像是阶梯的概率。换句话说,增加 x3 可能增加或减少取决于其他变量的值,很明显目前的模型无法达到这点。
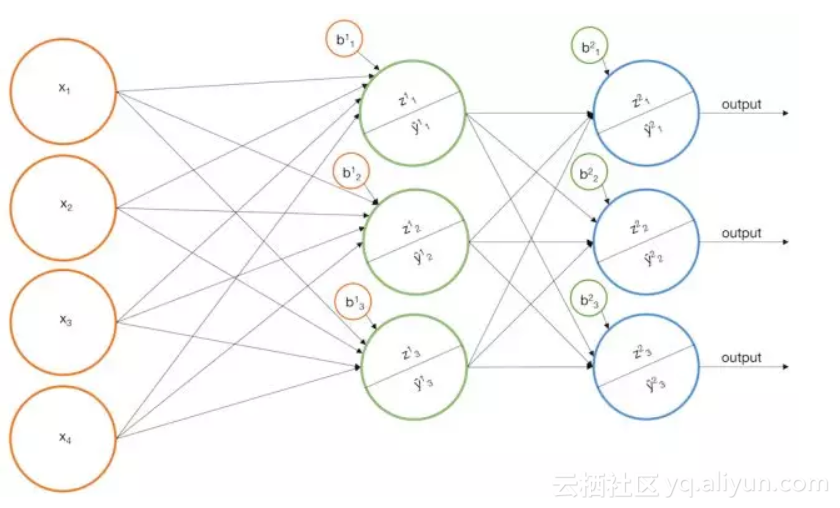
具有Sigmoid激活函数的多层感知机
(模型迭代2)
可以通过向感知机模型再加一层来解决上述问题2.1及问题2.2。
我们构建一些基本模型,比如上面的一个模型,然后我们将每个基本模型的输出作为另一个感知机的输入。这个模型实际上是一个香草神经网络(“香草”是一种常见的“常规”或“没有任何花哨的东西”的委婉说法),让我们看看它对某些例子可能有什么作用。
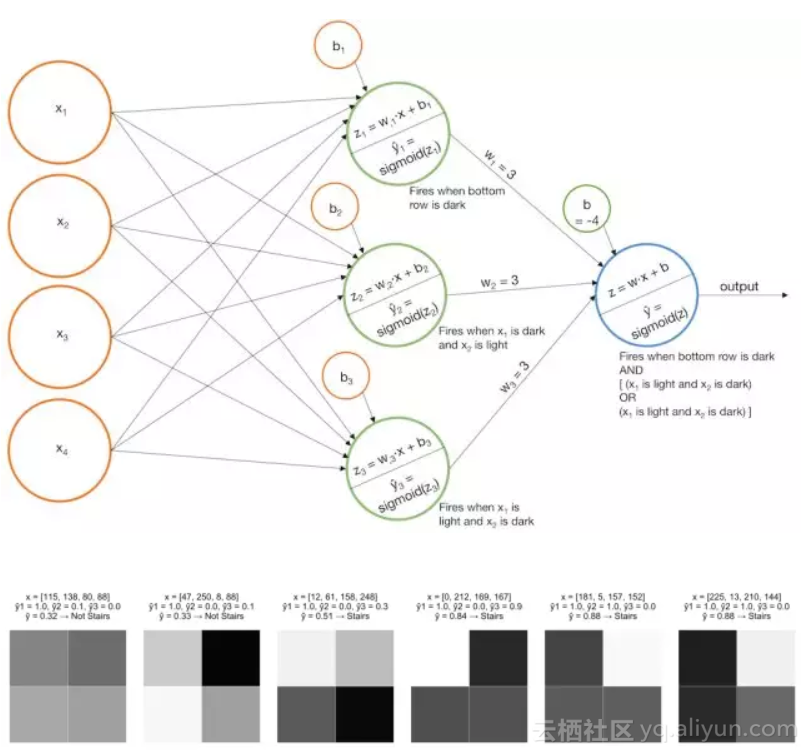
示例1 识别阶梯模式
- 搭建一个模型,当“左侧阶梯”被识别时,该模型“点亮”
;
- 搭建一个模型,当“右侧阶梯”确定时该模型“点亮”
;
- 把基本模型的分数加起来,这样当
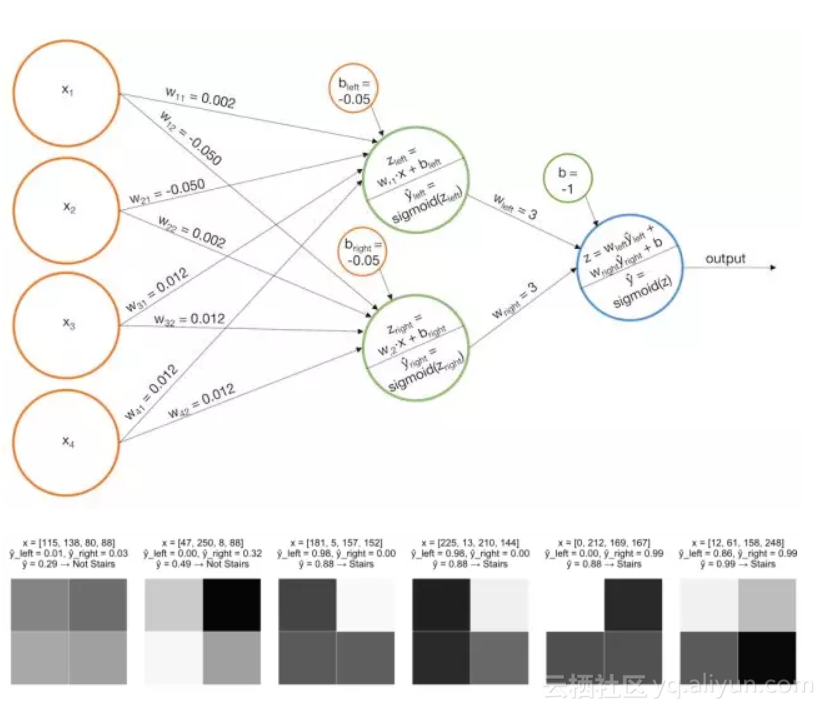
或者
- 搭建一个模型,当最后一列是黑色时模型“点亮”
;
- 搭建一个模型,当左上角的像素是黑色,右上角的像素;
- 亮时模型“点亮”
;
- 搭建一个模型,当左上角像素是亮的,右上角的像素是黑色时模型“点亮”
- 把基本模型的分数加起来,只有当
的值大时才会让最后一层网络上Sigmoid函数“点亮”。(注意,
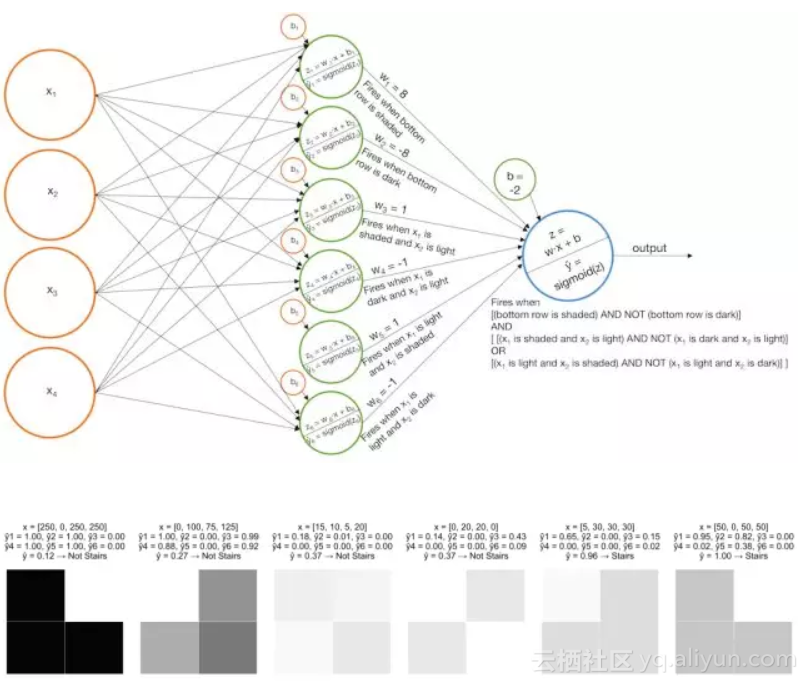
示例2 识别微弱阶梯
- 搭建几个基本模型,当底部一行是阴影,x1是阴影x2是白色,x2是阴影x1是白色时曲率“开火”
- 搭建几个基本模型,当底部一行是黑色,x1是黑色x2是白色,x2是黑色x1是白色时曲率“开火”
,
和
;
- 结合这几个基本模型,当结果输进Sigmoid函数之前把黑色识别器从阴影识别器中去除。
相关概念及方法解释
从拟合模型到训练样本(反向传播)
目前为止,我们讨论了神经网络如何有效的工作,接下来我们说一下如何让网络模型拟合标记的训练样本。换句话说,我们如何根据标记的训练样本,来选择最合适的网络参数。一般大家会选择梯度下降优化算法(MLE最大似然估计也可以),梯度下降过程如下所示:
- 从一些标记好的训练数据开始
- 选择一个可微的损失函数找最小值
- 选择一个网络架构,主要是确定网络有多少层,每层有多少节点
- 随机初始化网络的权值
- 在这个模型上运行训练数据,产生样本的预测值,然后根据损失函数计算总体误差
(这称为正向传播)
- 每一个权值的微小变化都决定着损失函数的大小,换句话说,要对每一个权值求梯度。(这称为反向传播)
- 在负梯度方向上选择一个小的步长,比如
,如果而且
,这时我们需要减小
来使当前的损失函数值降低。更新
(0.001是我们预先设置的步长值)
- 重复这个过程(从第五步开始),直到设定的迭代次数或者损失函数收敛。
以上是基本的想法,实际上,这带来了很多挑战。
挑战 1:计算的复杂性
在拟合过程中,我们需要计算的一个问题是L相对于每个权值的梯度。显然这不容易,因为L依赖于输出层中的每个节点,每个节点依赖于它前面层中的每个节点,以此类推。而我们用到的神经网络可能会有数十层,高达上千个节点,这就意味着计算将会是链式法则的噩梦。
解决这个问题,就要认识到你在使用链式法则求时会重复使用中间导数,这可以让你避免重复计算同一个数。
另外一种解决方法,我们可以找一个特殊的激活函数,它的导数可以用函数值来表示,例如=
。在正向传播过程中,为了计算出预测值
必须计算每个向量元素的
。它可以用在反向传播中计算梯度值来更新每个节点的权值,这样不仅节省时间还节省内存。
第三种解决方法,把训练集分成“mini batches”,并不断根据每一个batch更新权值。例如,把你的训练集分为{batch1, batch2, batch3},在训练集上第一次过程如下:
- 使用batch1更新权值
- 使用batch2更新权值
- 使用batch3更新权值
每次更新后重新计算L的梯度。
最后一种值得一提的技术是使用GPU而不是CPU,因为GPU更适合并行执行大量计算。
挑战 2:梯度下降可能找不到全局最小值
与其说是神经网络的挑战,不如是梯度下降的挑战。因为在梯度下降过程中,权值的更新可能会陷入局部最小值,也有可能越过最小值。也有解决的办法,可以在训练过程中选择不同的步长值或者增加网络的节点或层数来解决这个问题,在增加网络节点或层数时要注意防止过拟合。另外,一些探索式方法,例如momentum也可以有效解决这个问题。
挑战 3 如何泛化?
我们如何编写一个通用程序来拟合任意数量的节点和网络层的神经网络呢?我的答案是,“你不必这么做,完全可以借助Tensorflow”。但如果你真的想这样做,最困难的部分就是计算损失函数的梯度,所以把梯度表示成递归函数是你要考虑的一个重要问题。 更正式的名字是自动微分,一个五层的神经网络就是四层网络喂进一些感知机中,同样,四层的神经网络是三层的网络喂进一些感知机中,等等。
原文发布时间为:2018-01-11
本文作者:Ben Gorman
