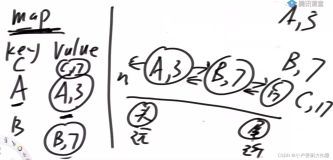LRU Cache
Design and implement a data structure for Least Recently Used (LRU) cache. It should support the following operations: get and set.
get(key) - Get the value (will always be positive) of the key if the key exists in the cache, otherwise return -1.set(key, value) - Set or insert the value if the key is not already present. When the cache reached its capacity, it should invalidate the least recently used item before inserting a new item.
- 题目大意:为LRU Cache设计一个数据结构,它支持两个操作:
1)get(key):如果key在cache中,则返回对应的value值,否则返回-1
2)set(key,value):如果key不在cache中,则将该(key,value)插入cache中(注意,如果cache已满,则必须把最近最久未使用的元素从cache中删除);如果key在cache中,则重置value的值。
- 解题思路:题目让设计一个LRU Cache,即根据LRU算法设计一个缓存。在这之前需要弄清楚LRU算法的核心思想,LRU全称是Least
Recently Used,即最近最久未使用的意思。在操作系统的内存管理中,有一类很重要的算法就是内存页面置换算法(包括FIFO,LRU,LFU等几种常见页面置换算法)。事实上,Cache算法和内存页面置换算法的核心思想是一样的:都是在给定一个限定大小的空间的前提下,设计一个原则如何来更新和访问其中的元素。下面说一下LRU算法的核心思想,LRU算法的设计原则是:如果一个数据在最近一段时间没有被访问到,那么在将来它被访问的可能性也很小。也就是说,当限定的空间已存满数据时,应当把最久没有被访问到的数据淘汰。
而用什么数据结构来实现LRU算法呢?可能大多数人都会想到:用一个数组来存储数据,给每一个数据项标记一个访问时间戳,每次插入新数据项的时候,先把数组中存在的数据项的时间戳自增,并将新数据项的时间戳置为0并插入到数组中。每次访问数组中的数据项的时候,将被访问的数据项的时间戳置为0。当数组空间已满时,将时间戳最大的数据项淘汰。
这种实现思路很简单,但是有什么缺陷呢?需要不停地维护数据项的访问时间戳,另外,在插入数据、删除数据以及访问数据时,时间复杂度都是O(n)。
那么有没有更好的实现办法呢?
那就是利用链表和hashmap。当需要插入新的数据项的时候,如果新数据项在链表中存在(一般称为命中),则把该节点移到链表头部,如果不存在,则新建一个节点,放到链表头部,若缓存满了,则把链表最后一个节点删除即可。在访问数据的时候,如果数据项在链表中存在,则把该节点移到链表头部,否则返回-1。这样一来在链表尾部的节点就是最近最久未访问的数据项。
总结一下:根据题目的要求,LRU Cache具备的操作:
1)set(key,value):如果key在hashmap中存在,则先重置对应的value值,然后获取对应的节点cur,将cur节点从链表删除,并移动到链表的头部;若果key在hashmap不存在,则新建一个节点,并将节点放到链表的头部。当Cache存满的时候,将链表最后一个节点删除即可。
2)get(key):如果key在hashmap中存在,则把对应的节点放到链表头部,并返回对应的value值;如果不存在,则返回-1。
仔细分析一下,如果在这地方利用单链表和hashmap,在set和get中,都有一个相同的操作就是将在命中的节点移到链表头部,如果按照传统的遍历办法来删除节点可以达到题目的要求么?第二,在删除链表末尾节点的时候,必须遍历链表,然后将末尾节点删除,这个能达到题目的时间要求么?
试一下便知结果:
第一个版本实现:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
|
#include <iostream>
#include <map>
#include <algorithm>
using
namespace
std;
struct
Node
{
int
key;
int
value;
Node *next;
};
class
LRUCache{
private
:
int
count;
int
size ;
map<
int
,Node *> mp;
Node *cacheList;
public
:
LRUCache(
int
capacity) {
size = capacity;
cacheList = NULL;
count = 0;
}
int
get(
int
key) {
if
(cacheList==NULL)
return
-1;
map<
int
,Node *>::iterator it=mp.find(key);
if
(it==mp.end())
//如果在Cache中不存在该key, 则返回-1
{
return
-1;
}
else
{
Node *p = it->second;
pushFront(p);
//将节点p置于链表头部
}
return
cacheList->value;
}
void
set(
int
key,
int
value) {
if
(cacheList==NULL)
//如果链表为空,直接放在链表头部
{
cacheList = (Node *)
malloc
(
sizeof
(Node));
cacheList->key = key;
cacheList->value = value;
cacheList->next = NULL;
mp[key] = cacheList;
count++;
}
else
//否则,在map中查找
{
map<
int
,Node *>::iterator it=mp.find(key);
if
(it==mp.end())
//没有命中
{
if
(count == size)
//cache满了
{
Node * p = cacheList;
Node *pre = p;
while
(p->next!=NULL)
{
pre = p;
p= p->next;
}
mp.erase(p->key);
count--;
if
(pre==p)
//说明只有一个节点
p=NULL;
else
pre->next = NULL;
free
(p);
}
Node * newNode = (Node *)
malloc
(
sizeof
(Node));
newNode->key = key;
newNode->value = value;
newNode->next = cacheList;
cacheList = newNode;
mp[key] = cacheList;
count++;
}
else
{
Node *p = it->second;
p->value = value;
pushFront(p);
}
}
}
void
pushFront(Node *cur)
//单链表删除节点,并将节点移动链表头部,O(n)
{
if
(count==1)
return
;
if
(cur==cacheList)
return
;
Node *p = cacheList;
while
(p->next!=cur)
{
p=p->next;
}
p->next = cur->next;
//删除cur节点
cur->next = cacheList;
cacheList = cur;
}
void
printCache(){
Node *p = cacheList;
while
(p!=NULL)
{
cout<<p->key<<
" "
;
p=p->next;
}
cout<<endl;
}
};
int
main(
void
)
{
/*LRUCache cache(3);
cache.set(2,10);
cache.printCache();
cache.set(1,11);
cache.printCache();
cache.set(2,12);
cache.printCache();
cache.set(1,13);
cache.printCache();
cache.set(2,14);
cache.printCache();
cache.set(3,15);
cache.printCache();
cache.set(4,100);
cache.printCache();
cout<<cache.get(2)<<endl;
cache.printCache();*/
LRUCache cache(2);
cout<<cache.get(2)<<endl;
cache.set(2,6);
cache.printCache();
cout<<cache.get(1)<<endl;
cache.set(1,5);
cache.printCache();
cache.set(1,2);
cache.printCache();
cout<<cache.get(1)<<endl;
cout<<cache.get(2)<<endl;
return
0;
}
|
提交之后,提示超时:

因此要对算法进行改进,如果把pushFront时间复杂度改进为O(1)的话是不是就能达到要求呢?
但是 在已知要删除的节点的情况下,如何在O(1)时间复杂度内删除节点?
如果知道当前节点的前驱节点的话,则在O(1)时间复杂度内删除节点是很容易的。而在无法获取当前节点的前驱节点的情况下,能够实现么?对,可以实现的。
具体的可以参照这几篇博文:
http://www.cnblogs.com/xwdreamer/archive/2012/04/26/2472102.html
http://www.nowamagic.net/librarys/veda/detail/261
原理:假如要删除的节点是cur,通过cur可以知道cur节点的后继节点curNext,如果交换cur节点和curNext节点的数据域,然后删除curNext节点(curNext节点是很好删除地),此时便在O(1)时间复杂度内完成了cur节点的删除。
改进版本1:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
void
pushFront(Node *cur)
//单链表删除节点,并将节点移动链表头部,O(1)
{
if
(count==1)
return
;
//先删除cur节点 ,再将cur节点移到链表头部
Node *curNext = cur->next;
if
(curNext==NULL)
//如果是最后一个节点
{
Node * p = cacheList;
while
(p->next!=cur)
{
p=p->next;
}
p->next = NULL;
cur->next = cacheList;
cacheList = cur;
}
else
//如果不是最后一个节点
{
cur->next = curNext->next;
int
tempKey = cur->key;
int
tempValue = cur->value;
cur->key = curNext->key;
cur->value = curNext->value;
curNext->key = tempKey;
curNext->value = tempValue;
curNext->next = cacheList;
cacheList = curNext;
mp[curNext->key] = curNext;
mp[cur->key] = cur;
}
}
|
提交之后,提示Accepted,耗时492ms,达到要求。

有没有更好的实现办法,使得删除末尾节点的复杂度也在O(1)?那就是利用双向链表,并提供head指针和tail指针,这样一来,所有的操作都是O(1)时间复杂度。
改进版本2:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
|
#include <iostream>
#include <map>
#include <algorithm>
using
namespace
std;
struct
Node
{
int
key;
int
value;
Node *pre;
Node *next;
};
class
LRUCache{
private
:
int
count;
int
size ;
map<
int
,Node *> mp;
Node *cacheHead;
Node *cacheTail;
public
:
LRUCache(
int
capacity) {
size = capacity;
cacheHead = NULL;
cacheTail = NULL;
count = 0;
}
int
get(
int
key) {
if
(cacheHead==NULL)
return
-1;
map<
int
,Node *>::iterator it=mp.find(key);
if
(it==mp.end())
//如果在Cache中不存在该key, 则返回-1
{
return
-1;
}
else
{
Node *p = it->second;
pushFront(p);
//将节点p置于链表头部
}
return
cacheHead->value;
}
void
set(
int
key,
int
value) {
if
(cacheHead==NULL)
//如果链表为空,直接放在链表头部
{
cacheHead = (Node *)
malloc
(
sizeof
(Node));
cacheHead->key = key;
cacheHead->value = value;
cacheHead->pre = NULL;
cacheHead->next = NULL;
mp[key] = cacheHead;
cacheTail = cacheHead;
count++;
}
else
//否则,在map中查找
{
map<
int
,Node *>::iterator it=mp.find(key);
if
(it==mp.end())
//没有命中
{
if
(count == size)
//cache满了
{
if
(cacheHead==cacheTail&&cacheHead!=NULL)
//只有一个节点
{
mp.erase(cacheHead->key);
cacheHead->key = key;
cacheHead->value = value;
mp[key] = cacheHead;
}
else
{
Node * p =cacheTail;
cacheTail->pre->next = cacheTail->next;
cacheTail = cacheTail->pre;
mp.erase(p->key);
p->key= key;
p->value = value;
p->next = cacheHead;
p->pre = cacheHead->pre;
cacheHead->pre = p;
cacheHead = p;
mp[cacheHead->key] = cacheHead;
}
}
else
{
Node * p = (Node *)
malloc
(
sizeof
(Node));
p->key = key;
p->value = value;
p->next = cacheHead;
p->pre = NULL;
cacheHead->pre = p;
cacheHead = p;
mp[cacheHead->key] = cacheHead;
count++;
}
}
else
{
Node *p = it->second;
p->value = value;
pushFront(p);
}
}
}
void
pushFront(Node *cur)
//双向链表删除节点,并将节点移动链表头部,O(1)
{
if
(count==1)
return
;
if
(cur==cacheHead)
return
;
if
(cur==cacheTail)
{
cacheTail = cur->pre;
}
cur->pre->next = cur->next;
//删除节点
if
(cur->next!=NULL)
cur->next->pre = cur->pre;
cur->next = cacheHead;
cur->pre = NULL;
cacheHead->pre = cur;
cacheHead = cur;
}
void
printCache(){
Node *p = cacheHead;
while
(p!=NULL)
{
cout<<p->key<<
" "
;
p=p->next;
}
cout<<endl;
}
};
int
main(
void
)
{
LRUCache cache(3);
cache.set(1,1);
//cache.printCache();
cache.set(2,2);
//cache.printCache();
cache.set(3,3);
cache.printCache();
cache.set(4,4);
cache.printCache();
cout<<cache.get(4)<<endl;
cache.printCache();
cout<<cache.get(3)<<endl;
cache.printCache();
cout<<cache.get(2)<<endl;
cache.printCache();
cout<<cache.get(1)<<endl;
cache.printCache();
cache.set(5,5);
cache.printCache();
cout<<cache.get(1)<<endl;
cout<<cache.get(2)<<endl;
cout<<cache.get(3)<<endl;
cout<<cache.get(4)<<endl;
cout<<cache.get(5)<<endl;
return
0;
}
|
提交测试结果:

可以发现,效率有进一步的提升。
其实在STL中的list就是一个双向链表,如果希望代码简短点,可以用list来实现:
具体实现:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
|
#include <iostream>
#include <map>
#include <algorithm>
#include <list>
using
namespace
std;
struct
Node
{
int
key;
int
value;
};
class
LRUCache{
private
:
int
maxSize ;
list<Node> cacheList;
map<
int
, list<Node>::iterator > mp;
public
:
LRUCache(
int
capacity) {
maxSize = capacity;
}
int
get(
int
key) {
map<
int
, list<Node>::iterator >::iterator it = mp.find(key);
if
(it==mp.end())
//没有命中
{
return
-1;
}
else
//在cache中命中了
{
list<Node>::iterator listIt = mp[key];
Node newNode;
newNode.key = key;
newNode.value = listIt->value;
cacheList.erase(listIt);
//先删除命中的节点
cacheList.push_front(newNode);
//将命中的节点放到链表头部
mp[key] = cacheList.begin();
}
return
cacheList.begin()->value;
}
void
set(
int
key,
int
value) {
map<
int
, list<Node>::iterator >::iterator it = mp.find(key);
if
(it==mp.end())
//没有命中
{
if
(cacheList.size()==maxSize)
//cache满了
{
mp.erase(cacheList.back().key);
cacheList.pop_back();
}
Node newNode;
newNode.key = key;
newNode.value = value;
cacheList.push_front(newNode);
mp[key] = cacheList.begin();
}
else
//命中
{
list<Node>::iterator listIt = mp[key];
cacheList.erase(listIt);
//先删除命中的节点
Node newNode;
newNode.key = key;
newNode.value = value;
cacheList.push_front(newNode);
//将命中的节点放到链表头部
mp[key] = cacheList.begin();
}
}
};
int
main(
void
)
{
LRUCache cache(3);
cache.set(1,1);
cache.set(2,2);
cache.set(3,3);
cache.set(4,4);
cout<<cache.get(4)<<endl;
cout<<cache.get(3)<<endl;
cout<<cache.get(2)<<endl;
cout<<cache.get(1)<<endl;
cache.set(5,5);
cout<<cache.get(1)<<endl;
cout<<cache.get(2)<<endl;
cout<<cache.get(3)<<endl;
cout<<cache.get(4)<<endl;
cout<<cache.get(5)<<endl;
return
0;
}
|
本文转载自海 子博客园博客,原文链接:http://www.cnblogs.com/dolphin0520/p/3741519.html如需转载自行联系原作者