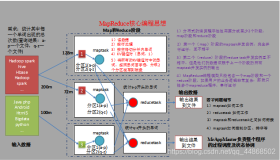
序列化是把对象变成二进制的过程
反序列化是将二进制变成对象的过程
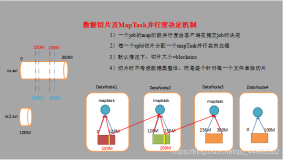
由HDFS中读取数据片段,一个数据片段对应着一个map线程

分为四个步骤:如图。split的时候不是一行就是一个数据片段,不要误会。Reduce数量由map的输出决定

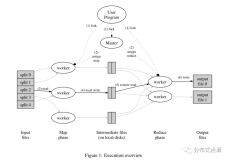
注意map的输出到本地磁盘并不是HDFS上。因为Map的输出在job完成后即可删除,因此不需要存储在HDFS上,虽然存到HDFS上更安全,但是网络传输会降低MR的执行效率。Reduce的输出是到HDFS上。
shuffle的过程的作用:
- 将mapper的输出按照某种key值重新切分成N分,把key值符合某种范围的输出送到特定的reducer里面去处理,从而简化reduce的过程。
下图将maptask 和 reduce task分开考虑

map之后有三个
partition. 将数据分成一个个分区,每个分区对应着一个reduce去执行。so, 解决好partition的问题就能解决好数据倾斜的问题。在fetch的时候起作用。partition怎么分区按照编程规则,默认的分区规则是哈希模运算(获得对象的hash值,哈希值是int,这个hash值模Reduce的整数),默认的partition规则会可能产生数据倾斜。分区不是将数据分开而是给要处理的数据打上标志位,哪些数据是1区,哪些数据是2区,真正的分开是在fetch阶段进行分开。 所谓的fetch是reduce可能和map的结果不在同一台机器上,故需要数据的拷贝,根据分区移动数据。上面有多个数据段,每次溢写产生一个文件。
sort。其实就是解决对象比较规则的算法。默认排序是字典排序(ASC马,11排在9的前面)。
- spill to disk(溢写)。Map输出的数据在内存里,内存由阈值,到达阈值之后要输出到硬盘,这就叫溢写
之后再merger on disk的时候,根据key的hash值进行合并,要用到的是conbainer。减少数据拷贝的量,减少map的输出。
所以shuffer阶段三次比较:在sort,conbainer,和merger的时候比较key。

MR split的大小

Demo1:WordCount程序
WordCountMap.java
package day0525;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordCountMap extends Mapper<LongWritable, Text, Text, IntWritable>{
protected void map(LongWritable key, Text value, Context context)
throws java.io.IOException ,InterruptedException {
/*
* First two parameters are the input data
*/
String line = value.toString();
StringTokenizer st = new StringTokenizer(line);
while (st.hasMoreTokens()) {
String word = st.nextToken();
context.write(new Text(word), new IntWritable(1));
}
}
}
WordCountReduce.java
package day0525;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReduce extends Reducer<Text, IntWritable, Text, IntWritable>{
protected void reduce(Text key, Iterable<IntWritable> value, Context context)
throws java.io.IOException ,InterruptedException {
/*
* Iterable<IntWritable> is Iter which used in Set operation.
* Output of map is set, so iterable is used. Moreover, map's output maybe a huge file,
* Therefore, only iter can read data step by step
*/
int sum = 0;
for(IntWritable i:value){
sum = sum + i.get();
}
context.write(key, new IntWritable(sum));
}
}
WordCountRun.java
package day0525;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountRun {
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.set("mapreduce.framework.name", "yarn");
try {
Job job = new Job(conf);
job.setJarByClass(WordCountRun.class);
job.setMapperClass(WordCountMap.class);
job.setReducerClass(WordCountReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// job.setNumReduceTasks(2); // set number of reducer task
FileInputFormat.addInputPath(job, new Path("/input0917/README.txt"));
FileOutputFormat.setOutputPath(job, new Path("/output0525/wc"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
} catch (Exception e) {
e.printStackTrace();
}
}
}
其中,conf.set 是mapred-site.xml中的内容
之后导出jar包并执行 hadoop jar WordCountTest01.jar day0525.WordCountRun 最后的参数时报名加main函数的入口另外,MR的官方文档也给除了wordcount的程序,具体请参考:http://hadoop.apache.org/docs/stable/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html。注意官方用了job.setCombinerClass(WordCountReduce.class);
Demo2:模仿qq好友推荐
思路:name1(主) name2(从)
map:
以主为key,输出一次
以从为key,输出一次
目的就是将key以及其所有的关系都列出package com.hadoop.qq;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class FriendRecomMap extends Mapper<LongWritable, Text, Text, Text>{
protected void map(LongWritable key, Text value, Context context)
throws java.io.IOException ,InterruptedException {
String line = value.toString();
String[] data = line.split(" ");
context.write(new Text(data[0]), new Text(data[1]));
context.write(new Text(data[1]), new Text(data[0]));
}
}
package com.hadoop.qq;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class FriendRecomReduce extends Reducer<Text, Text, Text, Text>{
protected void reduce(Text key, Iterable<Text> value, Context cxt)
throws java.io.IOException ,InterruptedException {
Set<String> set = new HashSet<String>();
for(Text val:value){
set.add(val.toString());
}
if(set.size() > 1){
for (Iterator iterator = set.iterator(); iterator.hasNext();) {
String str1 = (String) iterator.next();
for (Iterator iterator2 = set.iterator(); iterator2.hasNext();) {
String str2 = (String) iterator2.next();
if(!str1.equals(str2)){
cxt.write(new Text(str1), new Text(str2));
}
}
}
}
}
}
package com.hadoop.qq;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class FriendRecom {
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.set("mapreduce.framework.name", "yarn");
try {
Job job = new Job(conf);
job.setJobName("QQ");
job.setJarByClass(FriendRecom.class);
job.setMapperClass(FriendRecomMap.class);
job.setReducerClass(FriendRecomReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// job.setNumReduceTasks(2); // set number of reducer task
FileInputFormat.addInputPath(job, new Path("/input0917/qqFriend.txt"));
FileOutputFormat.setOutputPath(job, new Path("/output/qqFriend"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
} catch (Exception e) {
e.printStackTrace();
}
}
}
测试数据:
Jerry Chris
Jerry Young
Jerry Daniel
Chris Shawn
Chris Perry
Chris Felix
Shawn Larry
Shawn Maple
Young Will
Young Ian
Young Lily
LiuChao Lily
LiuChao Carol
Naixin Perry
Perry Maple
Perry Alex
Daniel Terry执行命令
hadoop jar qqFriend01.jar com.hadoop.qq.FriendRecom未完待续