我们常常看到“alignment",
"endian"之类的字眼,
但很少有C语言教材提到这些概念。
实际上它们是与处理器与内存接口,
编译器类型密切相关的。考虑这样一个例子:
两个异构的CPU进行通信,
定义了这样一个结果来传递消息:
struct Message
{
short opcode;
char subfield;
long message_length;
char version;
short destination_processor;
}message;
用这样一个结构来传递消息貌似非常方便, 但也引发了这样一个问题: 若这两种不同的CPU对该结构的定义不一样, 两者就会对消息有不同的理解。 有可能导致二义性。 会引发二义性的有这两个方面:
1.内存地址对齐
2.大小端定义
本文先介绍内存地址对齐和大小端的概念, 再回头来看这个例子就豁然开朗了。
内存地址对齐
洋名叫做" Byte Alignment"。
大部分16位和32位的CPU不允许将字或者长字存储到内存中的任意地址。 比如Motorola 68000不允许将16位的字存储到奇数地址中, 将一个16位的字写到奇数地址将引发异常。
实际上, 对于c中的字节组织, 有这样的对齐规则:
1) 结构体变量的首地址能够被其最宽基本类型成员的大小所整除;
2) 结构体每个成员相对于结构首地址的偏移量(offset)都是成员大小的整数倍,如有需要编译器会在成员之间加上填充字节(internal adding);
3) 结构体的总大小为结构体最宽基本类型成员大小的整数倍,如有需要编译器会在最末一个成员之后加上填充字节(trailing padding)。
不同CPU的对其规则可能不同, 请参考手册。
为什么会有上述的限制呢? 理解了内存组织, 就会清楚了
CPU通过地址总线来存取内存中的数据,32位的CPU的地址总线宽度既为32位置, 标为A[0:31]。 在一个总线周期内,CPU从内存读/写32位。 但是CPU只能在能够被4整除的地址进行内存访问,这是因为: 32位CPU不使用地址总线的A1和A2(比如, 它的A[0:1]用于字节选择, 用于逻辑控制, 而不和存储器相连, 存储器连接到A[2:31])。访问内存的最小单位是字节(byte), A0和A1不使用, 那么对于地址来说, 最低两位是无效的, 所以它只能识别能被4整除的地址了。 在4字节中,通过A0和A1确定某一个字节。
再看看刚才的message结构, 你想想它占了多少字节? 别想当然的以为是10个字节。 实际上它占了12个字节。 不信?
用sizeof(message)看吧。 对于结构体, 编译器会针对起中的元素添加"pad"以满足字节对齐规则。
message会被编译器改为下面的形式:
struct Message
{
short opcode;
char subfield;
char pad1;// Pad to start the long word at a 4
// byte boundary
long message_length;
char version;
char pad2;// Pad to start a short at a 2 byte boundary
short destination_processor;
char pad3[4];// Pad to align the complete structure to a 16
// byte boundary
};
如果不同的编译器采用不同的对齐规则, 对传递message可就麻烦了。
大端(Big Endian)与小端(Little Endian)
Byte Endian是指字节在内存中的组织,所以也称它为Byte Ordering。
对于数据中跨越多个字节的对象, 我们必须为它建立这样的约定:
(1) 它的地址是多少?
(2) 它的字节在内存中是如何组织的?
针对第一个问题,有这样的解释:
对于跨越多个字节的对象,一般它所占的字节都是连续的, 它的地址等于它所占字节最低地址。(链表可能是个例外, 但链表的地址可看作链表头的地址)。
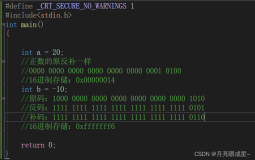
比如: int x, 它的地址为0x100。 那么它占据了内存中的Ox100, 0x101, 0x102, 0x103这四个字节。
上面只是内存字节组织的一种情况: 多字节对象在内存中的组织有一般有两种约定。 考虑一个W位的整数。 它的各位表达如下:
[Xw-1, Xw-2, ... , X1, X0]
它的MSB (Most Significant Byte, 最高有效字节)为[Xw-1, Xw-2, ... Xw-8]; LSB (Least Significant Byte, 最低有效字节)为 [X7,X6,..., X0]。 其余的字节位于MSB, LSB之间。
LSB和MSB谁位于内存的最低地址, 即谁代表该对象的地址? 这就引出了大端(Big Endian)与小端(Little Endian)的问题。
如果LSB在MSB前面, 既LSB是低地址, 则该机器是小端; 反之则是大端。 DEC (Digital Equipment Corporation, 现在是Compaq公司的一部分)和Intel的机器一般采用小端。 IBM, Motorola, Sun的机器一般采用大端。 当然, 这不代表所有情况。 有的CPU即能工作于小端, 又能工作于大端, 比如ARM, PowerPC, Alpha。 具体情形参考处理器手册。
举个例子来说名大小端: 比如一个int x, 地址为0x100, 它的值为0x1234567。 则它所占据的0x100, 0x101, 0x102, 0x103地址组织如下图:
0x01234567的MSB为0x01, LSB为0x67。 0x01在低地址(或理解为"MSB出现在LSB前面,因为这里讨论的地址都是递增的), 则为大端; 0x67在低地址则为小端。
认清这样一个事实: C中的数据类型都是从内存的低地址向高地址扩展,取址运算"&"都是取低地址。
两个测试Bit Endian的小程序:
method_1
int main(int argc, char *argv[])
{
int c = 1;
if ((*(char *)&c) == 1)
{
printf("little endian\n");
}
else
printf("big endian");
return 0;
}
int c 在内存中的表达为: 0x00000001。 (这里假设int为4字节)。 用char可以截取一个字节。 LSB为0x01, 若它出现在c的低地址, 则为小端。
method_2
int main(void)
{
union
{
short n;
char c[sizeof(short)];
}un;
un.n = 0x0102;
if ((un.c[0] == 1 && un.c[1] == 2))
printf("big endian\n");
else if ((un.c[0] == 2 && un.c[1] == 1))
printf("little endian\n");
else
printf("error!\n");
return 0;
}
union中元素的起始地址都是相同的——位于联合的开始。 用char来截取感兴趣的字节。
区分大端与小端有什么用呢? 如果两个不同Endian的机器进行通信时, 就有必要区分了。
struct Message
{
short opcode;
char subfield;
long message_length;
char version;
short destination_processor;
}message;
用这样一个结构来传递消息貌似非常方便, 但也引发了这样一个问题: 若这两种不同的CPU对该结构的定义不一样, 两者就会对消息有不同的理解。 有可能导致二义性。 会引发二义性的有这两个方面:
1.内存地址对齐
2.大小端定义
本文先介绍内存地址对齐和大小端的概念, 再回头来看这个例子就豁然开朗了。
内存地址对齐
洋名叫做" Byte Alignment"。
大部分16位和32位的CPU不允许将字或者长字存储到内存中的任意地址。 比如Motorola 68000不允许将16位的字存储到奇数地址中, 将一个16位的字写到奇数地址将引发异常。
实际上, 对于c中的字节组织, 有这样的对齐规则:
1) 结构体变量的首地址能够被其最宽基本类型成员的大小所整除;
2) 结构体每个成员相对于结构首地址的偏移量(offset)都是成员大小的整数倍,如有需要编译器会在成员之间加上填充字节(internal adding);
3) 结构体的总大小为结构体最宽基本类型成员大小的整数倍,如有需要编译器会在最末一个成员之后加上填充字节(trailing padding)。
不同CPU的对其规则可能不同, 请参考手册。
为什么会有上述的限制呢? 理解了内存组织, 就会清楚了
CPU通过地址总线来存取内存中的数据,32位的CPU的地址总线宽度既为32位置, 标为A[0:31]。 在一个总线周期内,CPU从内存读/写32位。 但是CPU只能在能够被4整除的地址进行内存访问,这是因为: 32位CPU不使用地址总线的A1和A2(比如, 它的A[0:1]用于字节选择, 用于逻辑控制, 而不和存储器相连, 存储器连接到A[2:31])。访问内存的最小单位是字节(byte), A0和A1不使用, 那么对于地址来说, 最低两位是无效的, 所以它只能识别能被4整除的地址了。 在4字节中,通过A0和A1确定某一个字节。
再看看刚才的message结构, 你想想它占了多少字节? 别想当然的以为是10个字节。 实际上它占了12个字节。 不信?
用sizeof(message)看吧。 对于结构体, 编译器会针对起中的元素添加"pad"以满足字节对齐规则。
message会被编译器改为下面的形式:
struct Message
{
short opcode;
char subfield;
char pad1;// Pad to start the long word at a 4
// byte boundary
long message_length;
char version;
char pad2;// Pad to start a short at a 2 byte boundary
short destination_processor;
char pad3[4];// Pad to align the complete structure to a 16
// byte boundary
};
如果不同的编译器采用不同的对齐规则, 对传递message可就麻烦了。
大端(Big Endian)与小端(Little Endian)
Byte Endian是指字节在内存中的组织,所以也称它为Byte Ordering。
对于数据中跨越多个字节的对象, 我们必须为它建立这样的约定:
(1) 它的地址是多少?
(2) 它的字节在内存中是如何组织的?
针对第一个问题,有这样的解释:
对于跨越多个字节的对象,一般它所占的字节都是连续的, 它的地址等于它所占字节最低地址。(链表可能是个例外, 但链表的地址可看作链表头的地址)。
比如: int x, 它的地址为0x100。 那么它占据了内存中的Ox100, 0x101, 0x102, 0x103这四个字节。
上面只是内存字节组织的一种情况: 多字节对象在内存中的组织有一般有两种约定。 考虑一个W位的整数。 它的各位表达如下:
[Xw-1, Xw-2, ... , X1, X0]
它的MSB (Most Significant Byte, 最高有效字节)为[Xw-1, Xw-2, ... Xw-8]; LSB (Least Significant Byte, 最低有效字节)为 [X7,X6,..., X0]。 其余的字节位于MSB, LSB之间。
LSB和MSB谁位于内存的最低地址, 即谁代表该对象的地址? 这就引出了大端(Big Endian)与小端(Little Endian)的问题。
如果LSB在MSB前面, 既LSB是低地址, 则该机器是小端; 反之则是大端。 DEC (Digital Equipment Corporation, 现在是Compaq公司的一部分)和Intel的机器一般采用小端。 IBM, Motorola, Sun的机器一般采用大端。 当然, 这不代表所有情况。 有的CPU即能工作于小端, 又能工作于大端, 比如ARM, PowerPC, Alpha。 具体情形参考处理器手册。
举个例子来说名大小端: 比如一个int x, 地址为0x100, 它的值为0x1234567。 则它所占据的0x100, 0x101, 0x102, 0x103地址组织如下图:
0x01234567的MSB为0x01, LSB为0x67。 0x01在低地址(或理解为"MSB出现在LSB前面,因为这里讨论的地址都是递增的), 则为大端; 0x67在低地址则为小端。
认清这样一个事实: C中的数据类型都是从内存的低地址向高地址扩展,取址运算"&"都是取低地址。
两个测试Bit Endian的小程序:
method_1
int main(int argc, char *argv[])
{
int c = 1;
if ((*(char *)&c) == 1)
{
printf("little endian\n");
}
else
printf("big endian");
return 0;
}
int c 在内存中的表达为: 0x00000001。 (这里假设int为4字节)。 用char可以截取一个字节。 LSB为0x01, 若它出现在c的低地址, 则为小端。
method_2
int main(void)
{
union
{
short n;
char c[sizeof(short)];
}un;
un.n = 0x0102;
if ((un.c[0] == 1 && un.c[1] == 2))
printf("big endian\n");
else if ((un.c[0] == 2 && un.c[1] == 1))
printf("little endian\n");
else
printf("error!\n");
return 0;
}
union中元素的起始地址都是相同的——位于联合的开始。 用char来截取感兴趣的字节。
区分大端与小端有什么用呢? 如果两个不同Endian的机器进行通信时, 就有必要区分了。
本文转自feisky博客园博客,原文链接:http://www.cnblogs.com/feisky/archive/2009/01/02/1586450.html,如需转载请自行联系原作者