前言
本文已同步到http://www.cnblogs.com/aehyok/p/3624579.html。本文主要来学习以下几点建议
建议61、避免在finally内撰写无效代码
建议62、避免嵌套异常
建议63、避免“吃掉”异常
建议64、为循环增加Tester-Doer模式而不是将try-catch置于循环内
建议61、避免在finally内撰写无效代码
先直接来看一下三个简单的try catch方法
public class User { public string Name { get; set; } } class Program { static void Main(string[] args) { Console.WriteLine(Test1()); Console.WriteLine(Test2()); Console.WriteLine(Test3().Name); Console.ReadLine(); } public static int Test1() { int i = 0; try { i = 1; } finally { i = 2; Console.WriteLine("\t 将int结果改为2,finnally执行完毕。"); } return i; } public static int Test2() { int i = 0; try { return i = 1; } finally { i = 2; Console.WriteLine("\t 将int结果改为2,finnally执行完毕。"); } }
看完代码你心里大概也有了一个答案了吧
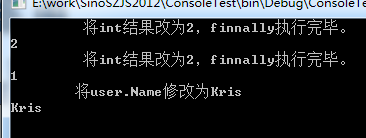
这些如果通过IL来解释,还是比较容易的,在此就不进行赘述了。
在CLR中,方法的参数以及返回值都是用栈来保存的。在方法内部,会首先将参数依次压栈,当需要使用这些参数的时候,方法会直接去栈里取用参数值,方法返回时,会将返回值压入栈顶。如果参数的类型是值类型,压栈的就是复制的值,如果是引用类型,则在方法内对于参数的修改也会带到方法外。
建议62、避免嵌套异常
在建议59中已经强调过,应该允许异常在调用堆栈中往上传播,不要过多使用catch,然后再throw。果断使用catch会带来两个问题:
1、代码更多了。这看上去好像你根本不知道该怎么处理异常,所以你总在不停地catch.
2、隐藏了堆栈信息,使你不知道真正发生异常的地方。
来看一下下面的代码
static void Main(string[] args) { try { Console.WriteLine("NoTry\n"); MethodNoTry(); } catch (Exception exception) { Console.WriteLine(exception.StackTrace); } try { Console.WriteLine("WithTry\n"); MethodWithTry(); } catch (Exception exception) { Console.WriteLine(exception.StackTrace); } Console.ReadLine(); } public static int Method() { int i = 0; return 10 / i; } public static void MethodNoTry() { Method(); } public static void MethodWithTry() { try { Method(); } catch (Exception exception) { throw exception; } }
执行结果
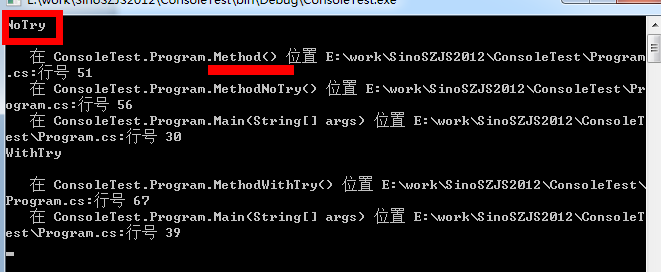
可以发现,MethodNoTry的方法可以查看到发生异常错误的地方,而MethodWithTry根本不清楚发生错误的地方了。调用的堆栈倍重置了。如果这个方法还存在另外的异常,在UI层将永远不知道真正发生错误的地方,给开发者带来不小的麻烦。
除了在建议59中提到的需要包装异常的情况外,无故地嵌套异常是我们要极力避免的。当然,如果真得需要捕获这个异常来恢复一些状态,然后重新抛出,代码来起来应该可以这样:
try { MethodWithTry(); } catch(Exception) { ///工作代码 throw; }
或者稍作改动
try { MethodWithTry(); } catch { ///工作代码 throw; }
尽量避免下面这样引发异常:
try { MethodWithTry(); } catch(Exception exception) { ///工作代码 throw exception; }
直接throw exception而不是throw将会重置堆栈消息。
建议63、避免“吃掉”异常
看了建议62之后,你可能已经明白,嵌套异常是很危险的行为,一不小心就会将异常堆栈信息,也就是真正的Bug出处隐藏起来。但这还不是最严重的行为,最严重的就是“吃掉”异常,即捕获然后不向上层throw抛出。
避免“吃掉”异常,并不是说不应该“吃掉”异常,而是这里面有个重要原则:该异常可悲预见,并且通常情况它不能算是一个Bug。
想象你正在对上万份文件进行解密,这些文件来自不同的客户端,很有可能存在文件倍破坏的现象,你的目标就是要讲解密出来的数据插入数据库。这个时候,你不得不忽略那些解密失败的问题,让这个过程进行下去。当然,记录日志是必要的, 因为后期你可能会倍解密失败的文件做统一的处理。
另外一种情况,可能连记录日志都不需要。在对上千个受控端进行控制的分布式系统中,控制端需要发送心跳数据来判断受控端的在线情况。通常的做法是维护一个信号量,如果在一个可接受的阻滞时间如(如500ms)心跳数据发送失败,那么控制端线程将不会收到信号,即可以判断受控端的断线状态。在这种情况下,对每次SocketException进行记录,通常也是没有意义的。
本建议的全部要素是:如果你不知道如何处理某个异常,那么千万不要“吃掉”异常,如果你一不小“吃掉”了一个本该网上传递的异常,那么,这里可能诞生一个BUg,而且,解决它会很费周折。
建议64、为循环增加Tester-Doer模式而不是将try-catch置于循环内
如果需要在循环中引发异常,你需要特别注意,因为抛出异常是一个相当影响性能的过程。应该尽量在循环当中对异常发生的一些条件进行判断,然后根据条件进行处理。可以做一个测试:
static void Main(string[] args) { CodeTimer.Initialize(); CodeTimer.Time("try..catch..", 1, P1); CodeTimer.Time("Tester-Doer", 1, P2); Console.ReadLine(); } public static void P1() { int x = 0; for (int i = 0; i < 1000; i++) { try { int j = i / x; } catch { } } }
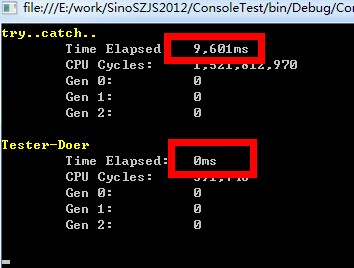
差距相当明显。以上代码中,我们预见了代码可能会发生DivideByZeroException异常,于是,调整策略,对异常发生的条件进行了特殊处理:Continue,让效率得到了极大的提升。

