xml文件是可扩展标记语言,在保存数据时,经常和.xml文件打交道,它语法简明、格式友好。具体的信息可以到百度百科科普下,下面主要介绍下我用的处理.xml文件的工具包XML2Dict
工具包下载:http://files.cnblogs.com/kaituorensheng/%E5%A4%84%E7%90%86xml%E6%96%87%E4%BB%B6.zip
下载后把文件解压,和自己的.py文件放在一起,里边有两个文件:xml2dict.py, object_dict.py,在自己.py文件的开头加上
from xml2dict import XML2Dict xml = XML2Dict() r = xml.parse("待处理文件名.xml")
示例一:
待处理文件:
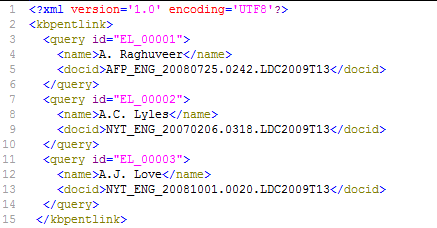
分析下这个文件的格式:
最外一层被<kbpentlink></kbpentlink>包围
往里一层是:<query></query>,query中包括<id><name>和<docid>两个属性
处理这个文件(取名:1.xml)代码:

from xml2dict import XML2Dict xml = XML2Dict() r = xml.parse('1.xml') for q in r.kbpentlink.query: print q print q.id print q.name print q.docid print '-----------------'
执行结果:

可以看到.xml文件被解析成字典的形式。使用给工具包的要点就是:分清层次,一点一点的往里面递进。
下边来解析一个比较难的示例:
示例二:
待处理文件:
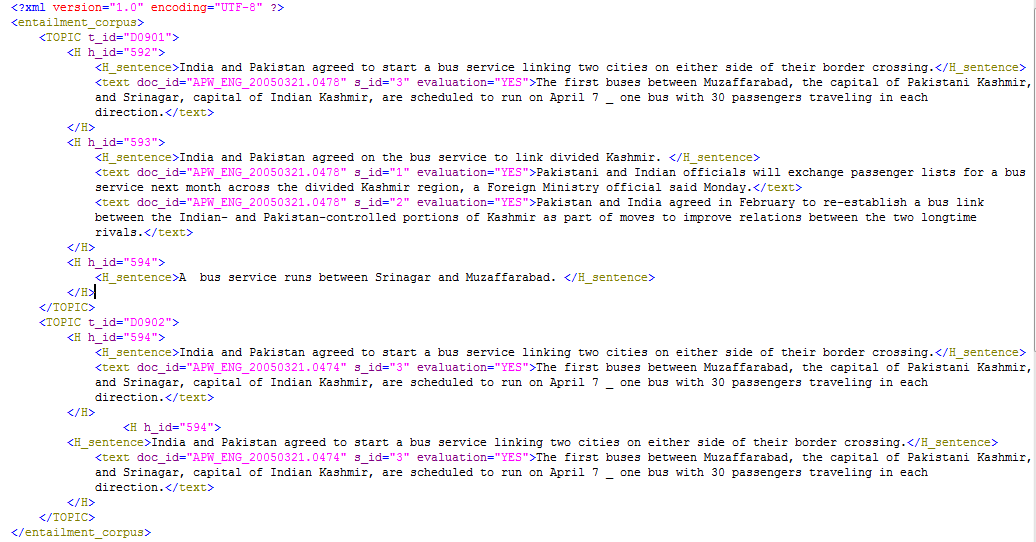
分析:
第一层:<entailment_corpus></entailment_corpus>
第二层:<TOPIC></TOPIC>
第三层:<H></H>,里面有属性<h_id><H_sentence><text>
第四层:(<text>属性有的前提下),里面属性<doc_id><s_id><evaluation><value>
这里的关键就是第三层:因为有的有一个<text>,有的则有多个,还有的没有:一个是得到的是个字典,多个时是个列表
解析代码如下:
from xml2dict import XML2Dict import types xml = XML2Dict() r = xml.parse('2.xml') for topic in r.entailment_corpus.TOPIC: print 'topic.t_id:' + topic.t_id for h in topic.H: print 'H.h_id' + h.h_id print 'H.H_sentence' + h.H_sentence if h.has_key('text'): if type(h.text) == types.ListType: //多个时为列表类型 print 'hello list' print h.text for text in h.text: print 'h.doc_id' + text.doc_id //单个时 else: print 'hello dic' print h.text //单个时h.text就可以输出了,不要for了,否则错误 else: print "no text attribute"
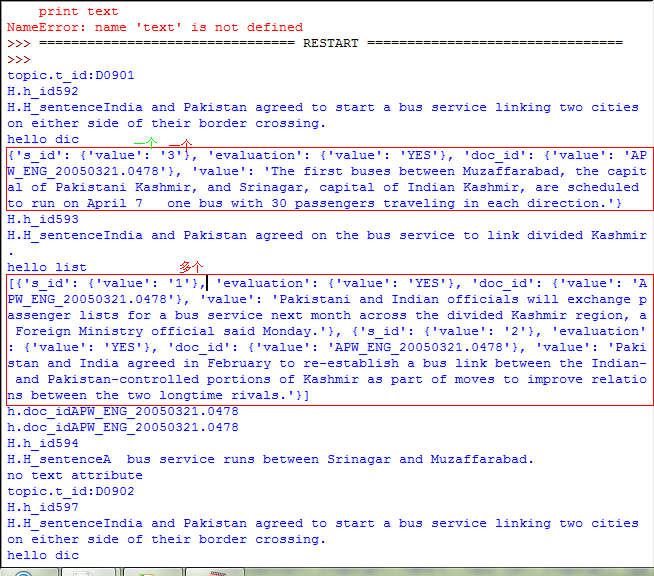
结果:
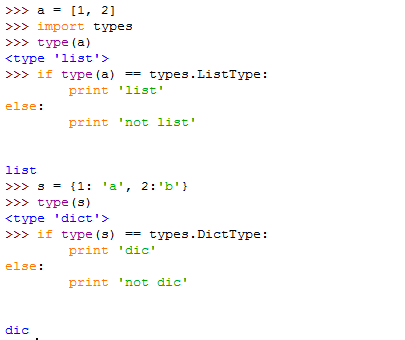
这里引用了types里面的函数type(类型),用法如下示例:
已解决:
示例二中else替换为:type(h.text) == types.DictType: 效果不同,原因:
一般的字典类型为: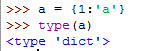
而此时类型为:
本文转自jihite博客园博客,原文链接:http://www.cnblogs.com/kaituorensheng/archive/2013/05/05/3061365.html,如需转载请自行联系原作者




