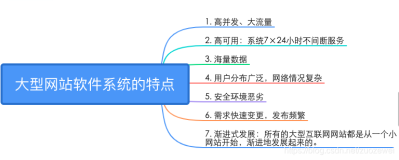
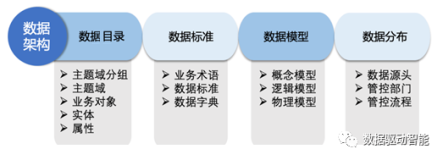
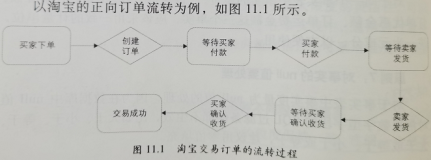
简介
数据库中表的设计是一个老生常谈的话题,对于表的设计却依然存在某些误区,本篇文章对来从范式和性能的角度谈一谈数据库的设计。
设计数据库?
首先第一个问题是,对于表的设计而言,我们究竟需要何种程度的设计。这取决于您数据库的规模,打个比方,就好比您盖一个两层小楼,基本无需什么设计,直接上手即可,如果盖一个两层小楼也去找设计院的话,那岂不是画蛇添足。但是对盖一座大厦来说,不做规划和设计,就难以想象了。
但与盖楼这个比喻不同的是,数据库会增长,未来数据量的增长和并发量可能超出您的估计。因此,如果做一个好的设计,在面对未来数据和并发的增长时,也许就不会那么狼狈。
请记住,做一个好的设计和坏的设计所需话费的成本差不多,那我们为什么不在一开始设计表时就有所注意。
范式?
范式也是一个老话题了,关于范式的介绍也是满天飞了,这里就不在细说了。对于范式,我喜欢分为两大类:第一范式和其他范式。第一范式意味着数据不可再分,对此具体的解释我会接下来说到。而其他范式讲的是一件事,表中主键唯一标识其所代表的行,其他列都是对该行的描述。
范式化使得您的设计符合关系数据库。也是一个标准化数据的过程。尤其是第一范式,即使是数据仓库,也是需要遵循的。
下面先说说第一范式。
第一范式
第一范式意味着将数据分解到最低层级,那数据分解到第一层级的标准分为以下3条:
列值符合原子性
没有重复列
每一行代表一个值
首先,列值按照业务类型不应该可以再分。这也是为什么表的命名应该是复数形式,而列的命名往往是单数形式。因为列所代表的意义符合第一范式的话,那应该是唯一的。
那反过来,什么样的表不符合第一范式呢,比如说:
列值可以再分,比如说一组值以逗号分割
属性后面带有数字,比如说Description1,Description2
下面我们来举一组简单的例子,来说明第一范式:
假如我们有一个图书表:
1
图1.图书表
假设我们有大于一位作者时,难道表结构需要变成这样?
2
图2.不符合第一范式的解决办法
图2中的办法显然是非常不好的,正确的做法应该是第一范式化,如图3所示。
3
图3.第一范式话后的表
我们再来看一个简单的例子,假如说最简单的一个用户表模型,如图4所示。
4
图4.
图4中的表是否符合第一范式要取决于使用该表的应用程序,如果使用该表的应用程序在使用过程中无需做拆分,则说明该表是符合第一范式的,否则,需要将地址字段做进一步拆分,如图5所示。
5
图5.进一步对表做拆分,来满足第一范式
那为什么非要满足第一范式呢?这是由于为了避免在使用数据过程中存在花样百出的代码,这些代码包括:
Substring
Charindex
Patindex
CASE表达式
&或|
Distinct或不聚合的情况下使用Group By
其实使用上述代码并没有什么错,但由于上述代码而造成性能和数据完整性问题的时候,就不对了。下面我们再来看一个由于不符合第一范式而造成的导致性能问题的代码,如代码清单1所示。
--错误
SELECT * from Person
Where SUBSTRING(fullname,0,1) =‘王’
--正确
SELECT * from Person where FirstName = ‘王’
代码清单1.不符合第一范式,导致在Where条件做运算,从而导致非常低效的查询语句
第二范式、第三范式、BC范式
其实这几种范式说明的都是同一个问题:“键用来标识表,非键用来描述键所标识的表”。几种范式的关系是依次递进的,这意味着满足第三范式,首先一定会满足第二范式。简单来说几种范式的作用:
第二范式消除对主键的部分依赖,其次,每列都需要和主键相关
第三范式消除对主键的传递依赖
BC范式消除对非主键的数据依赖
让我们来看一个简单的例子,如图6所示。
6
图6.简单的例子
首先来看图6所示的表,我们考虑到主键是UserID,这意味着该表是用来描述用户的,每行代表的是一个用户,而该表中国仅仅是UserName和UserEmail列是和用户直接相关的。其次,Province和City这两列存在二义性,这两列究竟是描述产品所在的城市还是用户所在的城市呢?另外,知道City的值,就完全可以知道Province的值,这存在潜在的数据不一致的风险。最后ProductColor传递依赖于UserID这个主键。
因此,我们根据“键用来标识表,非键用来描述键所标识的表”这个简单的概念,把图6的表做一个拆分,如图7所示。
7
图7.拆分后的表符合BCNF
从图7中我们可以看出,每一个表的意义都是唯一的,主键标识每一行,其他列描述这一行。
因此对范式做一个小小的总结,第一范式是必须遵循的,即使在数据仓库也是要遵循的,在设计数据库的时候要把范式作为一个参考,但也不要教条。
反范式
由范式的概念不难看出,越高等级的范式所产生的表越多,而在应用程序使用的过程中越多的表Join越容易造成性能损耗的问题。因此,在某些场景下需要反范式化来进行Trade-Off。
首先一个适合反范式化的场景是,数据库的读写比趋近于无穷,那么减少表无疑是非常合适的。
第二个是在设计表的时候过度范式话,体现就是数据库中存在很多4+个表的连接,这可能由于是开始设计的时候过度设计,或是数据库中数据增长的量使得过多的表连接产生了性能问题。
一个挺有意思的观点是不断范式化,直道影响了性能,然后进行反范式化。这个观点所忽略的是,通常对性能产生影响是数据量在生产环境中已经产生了性能问题,而在生产环境中进行反范式话的话,不仅仅是成本的问题,还有风险的问题。
所以更好的方式是考虑范式到仅仅满足用户的需求即可,范式仅仅是一个参考,不要过于教条,当然,关于用户需求的不断变更,就不在本文的讨论之列了:-)
主键的选择
其实关于主键的选择我之前已经有一篇文章对此进行阐述了(参看我之前的文章:从性能的角度谈SQL Server聚集索引键的选择),再次我想多说一句,尽量考虑使用代理键作为主键,使用代理键的好处如下:
防止业务更改导致主键的更改
方便将数据由多个数据源合并到单个数据源
非代理件可能是多列,或者过长,从而导致聚集索引建过长,因此造成性能的问题.
代理键不会参与数据仓库的计算,比如说聚合函数
小节
本篇文章简单从性能和范式的角度谈了一下表的设计和主键的选择。按照用户的需求灵活的设计表才是正道,至于用户需求变更的事,那就超出了本文的讨论范围了眨眼
本文转自CareySon博客园博客,原文链接:http://www.cnblogs.com/CareySon/p/3146805.html,如需转载请自行联系原作者