1.概述
在现实业务当中,存在这样的业务场景,需要实时去查询HDFS上的相关存储数据,普通的查询(如:Hive查询),时延较高。那么,是否存在时 延较小的查询组件。在业界目前较为成熟的有Cloudera的Impala,Apache的Drill,Hortonworks的Stinger。本篇博 客主要为大家介绍Drill,其他两种方式大家可以自行下去补充。
2.Drill Architecture
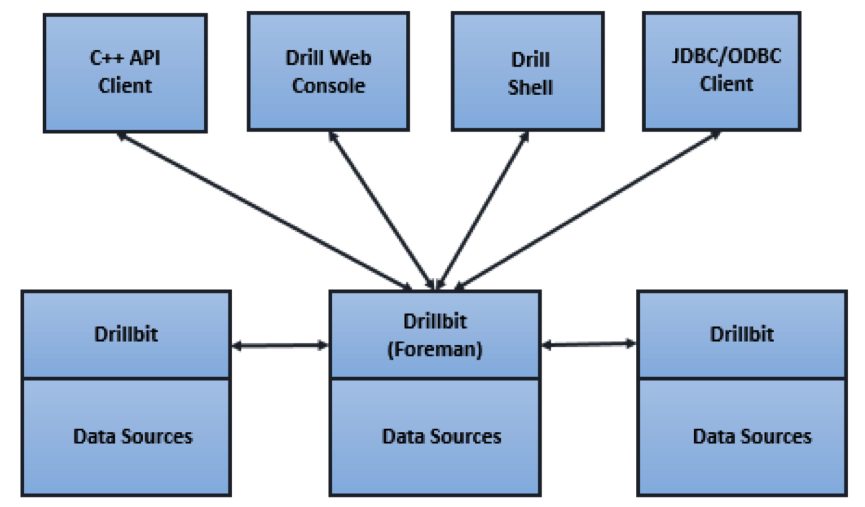
2.1 Cilent
使用Drill,可以通过以下方式进入到Drill当中,内容如下所示:
- Drill shell:使用客户端命令去操作
- Drill Web Console:Web UI界面去操作相关内容
- ODBC/JDBC:使用驱动接口操作
- C++ API:C++的API接口
2.2 Drill Query Execution
执行流程如下图所示:
2.3 Core Modules
核心模块图,如下所示:
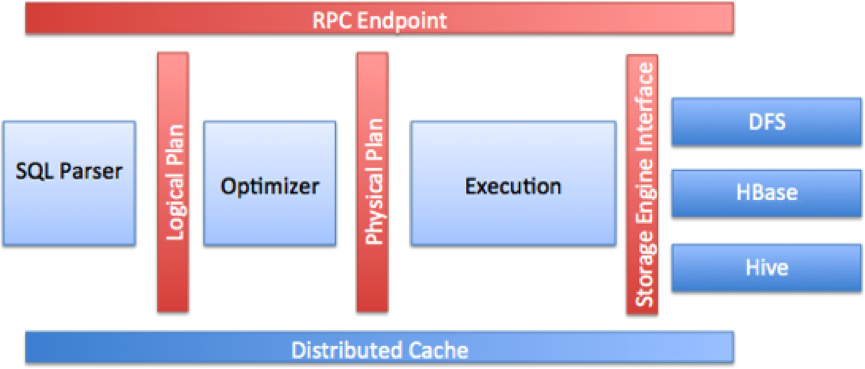
至于详细的文字描述,这里就不多做赘述了。大家看图若是有疑惑的地方,可以去官方网站,查看详细的文档描述。[官方文档]
3.Drill使用
介绍完Drill的架构流程,下面我们可以去使用Drill去做相关查询操作。安装Drill的过程比较简单,这里就不多做详细的赘述了。首 先,去Apache的官网下载Drill的安装包,这里笔者所使用的本版是drill-1.2.0。可独立部署在物理机上,不必与Hadoop集群部署在 一起。这里需要注意的是,物理机的内存至少留有4G空闲给Drill去使用。不然,在执行查询操作的时候会内容溢出,查询Drill的官方文档,官方给出 的解释是,操作的内容都在内容中完成,不会写磁盘,除非你强制指明去写磁盘,但是,一般考虑到响应速度因素,都会在内容中完成。笔者曾试图降低其内存配置 小于4G,然并卵。所以,在使用Drill做查询时,需要保证物理机空闲内存大于等于4G。
目前,Drill迭代版本比较快速。大家在下载Drill版本的时候,可以多多留意下版本内容变化。
在解压Drill的压缩包后,在其conf文件夹下有一个drill-override.conf文件,这里我们在里面添加Web UI的访问地址,添加的内容我们可以在drill-override-example.conf模版文件中查找对应的内容。添加内容如下所示:
drill.exec: {
cluster-id: "drillbits1",
zk.connect: "dn1:2181,dn2:2181,dn2:2181",
http: {
enabled: true,
ssl_enabled: false,
port: 8047
}
}
./drillbit.sh start
启动之后,Web UI界面如下所示:
目前条件有限,只有单台物理机,所以只部署了单台Drill。若是,大家条件允许,可以查看官网文档去部署Cluster。Drill插件默认是没有HDFS的,需要我们主动去创建,默认只有以下插件,如下图所示:
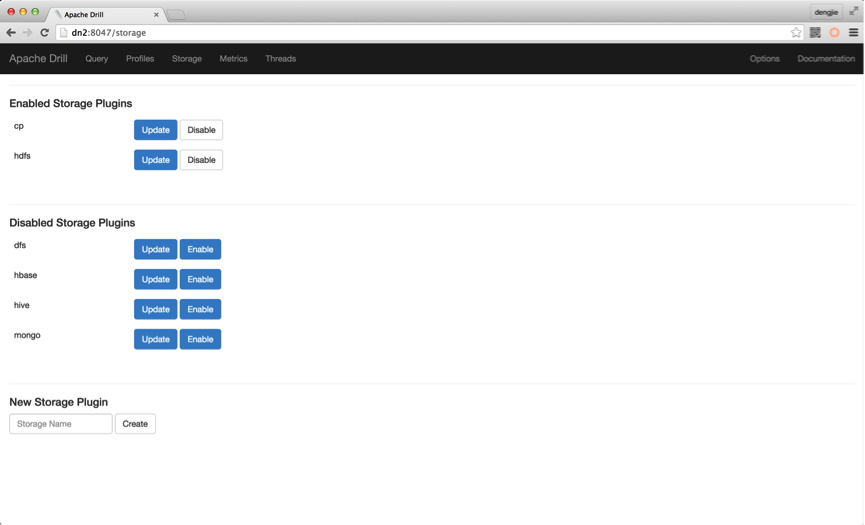
这里,笔者已经配置过HDFS的插件,故上图出现HDFS插件信息,其配置信息如下所示:
{
"type": "file",
"enabled": true,
"connection": "hdfs://hadoop.company.com:9000/",
"workspaces": {
"root": {
"location": "/opt/drill",
"writable": true,
"defaultInputFormat": null
}
},
"formats": {
"csv": {
"type": "text",
"extensions": [
"csv"
],
"delimiter": ","
},
"tsv": {
"type": "text",
"extensions": [
"tsv"
],
"delimiter": "\t"
},
"parquet": {
"type": "parquet"
}
}
}PS:这里要保证HDFS的地址信息正确。另外,Drill支持的存储介质较多,大家参考官方文档去添加对应的存储介质。
在添加HDFS插件之后,我们可以通过Web UI界面的查询界面进行文件查询,也可以使用Drill Shell命令在终端去查询。查询方式如下所示:
- Web UI查询命令:
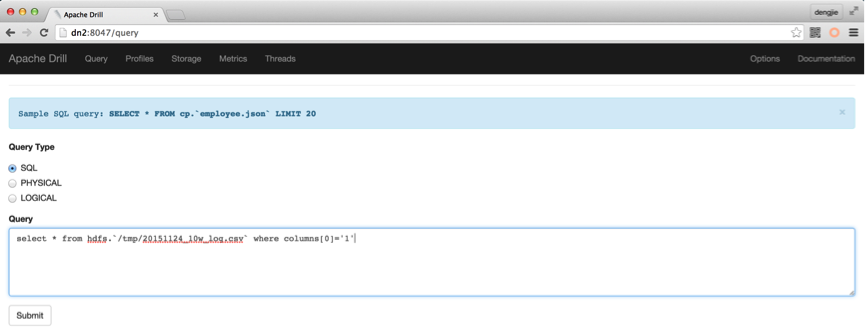
- Web UI结果如下:
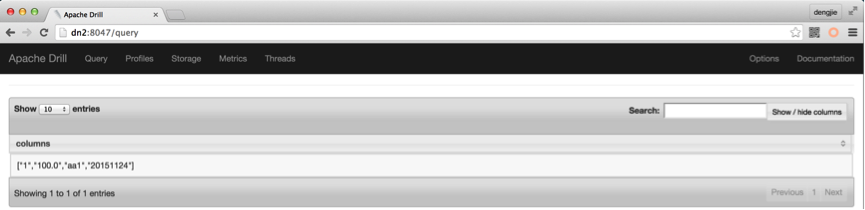
另外,其查询记录详情可以在Profiles模块下查看。如下图所示: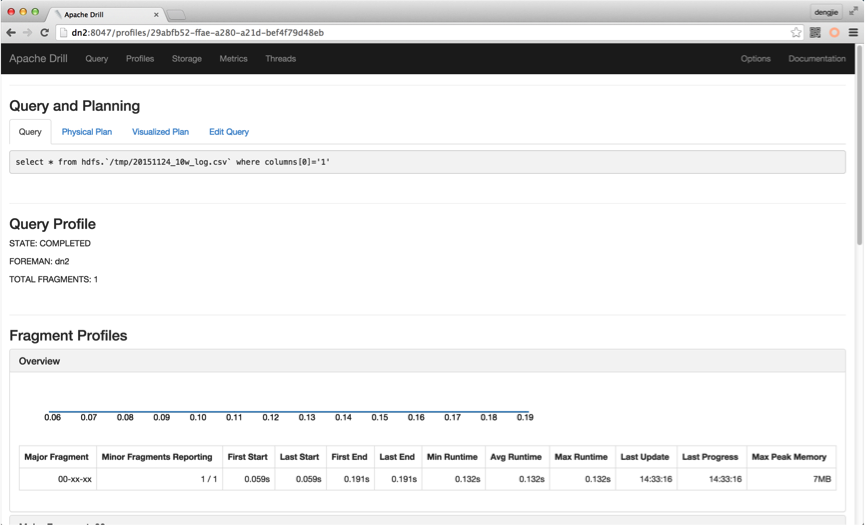
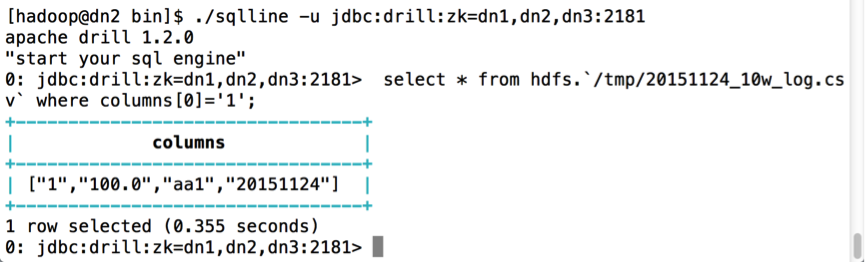
- Drill Shell查询:
./sqlline -u jdbc:drill:zk=dn1,dn2,dn3:2181
- Drill Shell 查询结果:
4.总结
这里,笔者做过一个性能测试比较,数量级分别为10W,100W,1000W的不重复数据,其响应时间依次递增。结果如下图所示:

通过测试结果可以看出,若是数量级在100W时,响应时间平均在秒级别,可以尝试用Drill去中OLTP业务。若是在1000W以上级别,显然这个延时做OLTP是难以接受的,这个可以去做OLAP业务。
5.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!


