2017 年 12 月底,清华大学张钹院士做了一场题为《AI 科学突破的前夜,教授们应当看到什么?》的精彩特邀报告。他认为,处理知识是人类所擅长的,而处理数据是计算机所擅长的,如果能够将二者结合起来,一定能够构建出比人类更加智能的系统。因此他提出,AI 未来的科学突破是建立一种同时基于知识和数据的 AI 系统。
我完全赞同张钹老师的学术观点。最近一年里,我们在这方面也做了一些尝试,将语言知识库 HowNet 中的义原标注信息融入面向 NLP 的深度学习模型中,取得了一些有意思的结果,在这里整理与大家分享一下。
什么是 HowNet
HowNet 是董振东先生、董强先生父子毕数十年之功标注的大型语言知识库,主要面向中文(也包括英文)的词汇与概念[1]。
HowNet 秉承还原论思想,认为词汇/词义可以用更小的语义单位来描述。这种语义单位被称为“义原”(Sememe),顾名思义就是原子语义,即最基本的、不宜再分割的最小语义单位。在不断标注的过程中,HowNet 逐渐构建出了一套精细的义原体系(约 2000 个义原)。HowNet 基于该义原体系累计标注了数十万词汇/词义的语义信息。
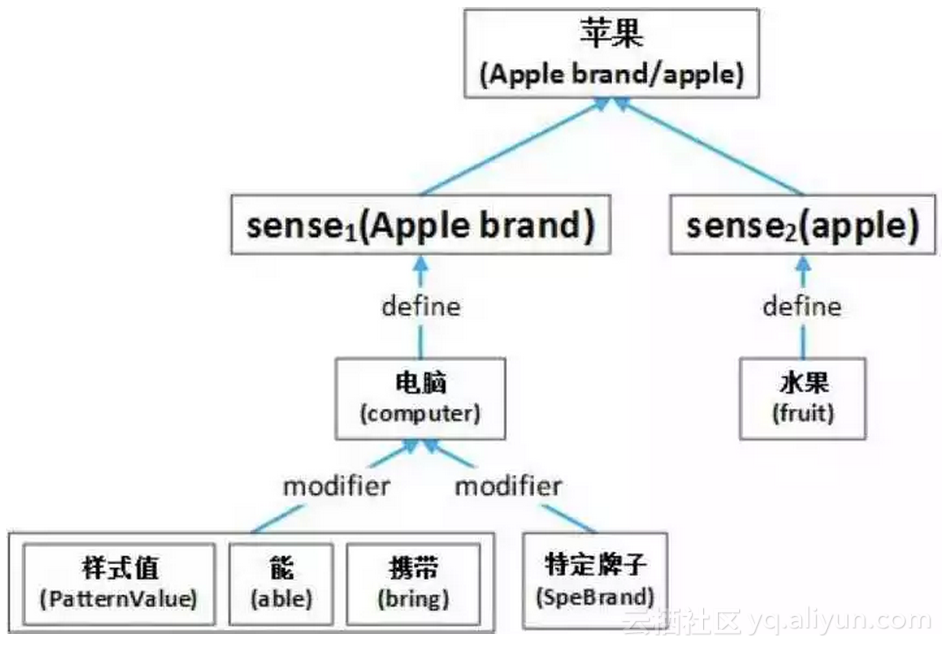
例如“顶点”一词在 HowNet 有两个代表义项,分别标注义原信息如下,其中每个“xx|yy”代表一个义原,“|”左边为英文右边为中文;义原之间还被标注了复杂的语义关系,如 host、modifier、belong 等,从而能够精确地表示词义的语义信息。
顶点#1
DEF={Boundary|界限:host={entity|实体},modifier={GreaterThanNormal|高于正常:degree={most|最}}}
顶点#2
DEF={location|位置:belong={angular|角},modifier={dot|点}}
在 NLP 领域知识库资源一直扮演着重要角色,在英语世界中最具知名度的是 WordNet,采用同义词集(synset)的形式标注词汇/词义的语义知识。HowNet 采取了不同于 WordNet 的标注思路,可以说是我国学者为 NLP 做出的最独具特色的杰出贡献。
HowNet 在 2000 年前后引起了国内 NLP 学术界极大的研究热情,在词汇相似度计算、文本分类、信息检索等方面探索了 HowNet 的重要应用价值[2,3],与当时国际上对 WordNet 的应用探索相映成趣。
深度学习时代 HowNet 有什么用
进入深度学习时代,人们发现通过大规模文本数据也能够很好地学习词汇的语义表示。例如以 word2vec[4]为代表的词表示学习方法,用低维(一般数百维)、稠密、实值向量来表示每个词汇/词义的语义信息,又称为分布式表示(distributed representation,或 embedding),利用大规模文本中的词汇上下文信息自动学习向量表示。
我们可以用这些向量方便地计算词汇/词义相似度,能够取得比传统基于语言知识库的方法还好的效果。也正因为如此,近年来无论是 HowNet 还是 WordNet 的学术关注度都有显著下降,如以下两图所示。
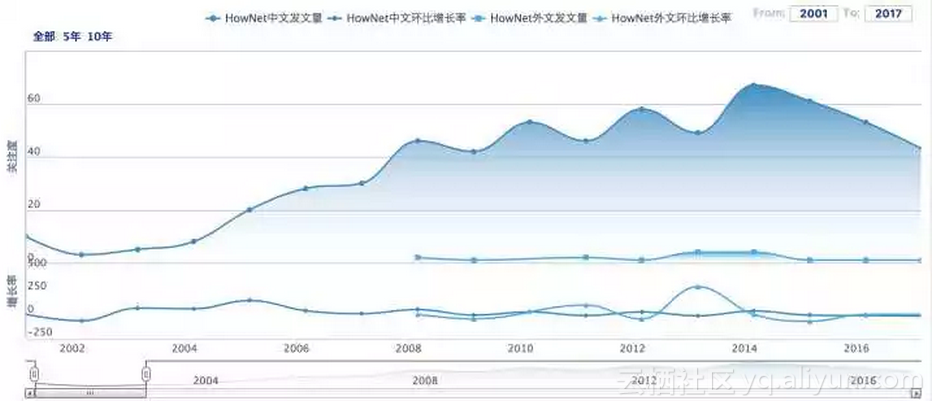
△ 中国期刊网(CNKI)统计HowNet学术关注度变化趋势
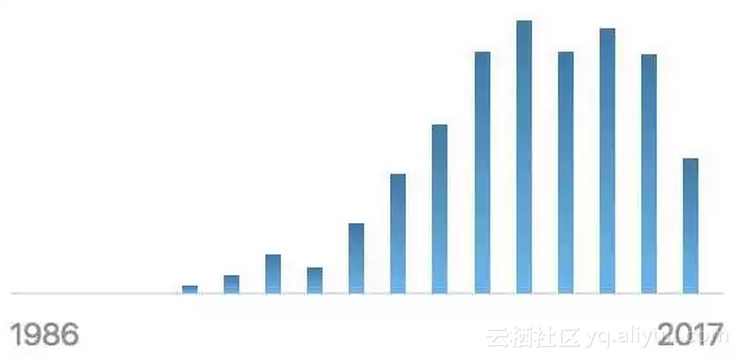
△ Semantic Scholar统计WordNet相关论文变化趋势
是不是说,深度学习时代以 WordNet、HowNet 为代表的语言知识库就毫无用处了呢?实际并非如此。实际上自 word2vec 刚提出一年后,我们[5]以及 ACL 2015 最佳学生论文[6]等工作,都发现将 WordNet 知识融入到词表示学习过程中,能够有效提升词表示效果。
虽然目前大部分 NLP 深度学习模型尚没有为语言知识库留出位置,但正由于深度学习模型 data-hungry、black-box 等特性,正使其发展遭遇不可突破的瓶颈。
回顾最开始提及的张钹院士的观点,我们坚信 AI 未来的科学突破是建立一种同时基于知识和数据的 AI 系统。看清楚了这个大形势,针对 NLP 深度学习模型的关键问题就在于,利用什么知识,怎样利用知识。
在自然语言理解方面,HowNet 更贴近语言本质特点。自然语言中的词汇是典型的符号信息,这些符号背后蕴藏丰富的语义信息。可以说,词汇是最小的语言使用单位,却不是最小的语义单位。HowNet 提出的义原标注体系,正是突破词汇屏障,深入了解词汇背后丰富语义信息的重要通道。
在融入学习模型方面,HowNet 具有无可比拟的优势。在 WordNet、同义词词林等知识库中,每个词的词义是通过同义词集(synset)和定义(gloss)来间接体现的,具体每个词义到底什么意义,缺少细粒度的精准刻画,缺少显式定量的信息,无法更好为计算机所用。
而 HowNet 通过一套统一的义原标注体系,能够直接精准刻画词义的语义信息;而每个义原含义明确固定,可被直接作为语义标签融入机器学习模型。
也许是由于 HowNet 采用了收费授权的政策,并且主要面向中文世界,近年来 HowNet 知识库有些淡出人们的视野。然而,对 HowNet 逐渐深入理解,以及最近我们在 HowNet 与深度学习模型融合的成功尝试,让我开始坚信,HowNet 语言知识体系与思想必将在深度学习时代大放异彩。
我们的尝试
最近我们分别探索了词汇表示学习、新词义原推荐、和词典扩展等任务上,验证了 HowNet 与深度学习模型融合的有效性。
1. 融合义原知识的词汇表示学习

- 论文 | Improved Word Representation Learning with Sememes
- 链接 | https://www.paperweekly.site/papers/1498
- 源码 | https://github.com/thunlp/SE-WRL
我们考虑将词义的义原知识融入词汇表示学习模型中。在该工作中,我们将 HowNet 的义原标注信息具象化为如下图所示的 word-sense-sememe 结构。需要注意的是,为了简化模型,我们没有考虑词义的义原结构信息,即我们将每个词义的义原标注看做一个无序集合。
△ HowNet义原标注知识的word-sense-sememe结构示意图
基于 word2vec 中的 Skip-Gram 模型,我们提出了 SAT(sememe attention over target model)模型。与 Skip-Gram 模型只考虑上下文信息相比,SAT 模型同时考虑单词的义原信息,使用义原信息辅助模型更好地“理解”单词。
具体做法是,根据上下文单词来对中心词做词义消歧,使用 attention 机制计算上下文对该单词各个词义(sense)的权重,然后使用 sense embedding 的加权平均值表示单词向量。在词语相似度计算和类比推理两个任务上的实验结果表明,将义原信息融入词汇表示学习能够有效提升词向量性能。
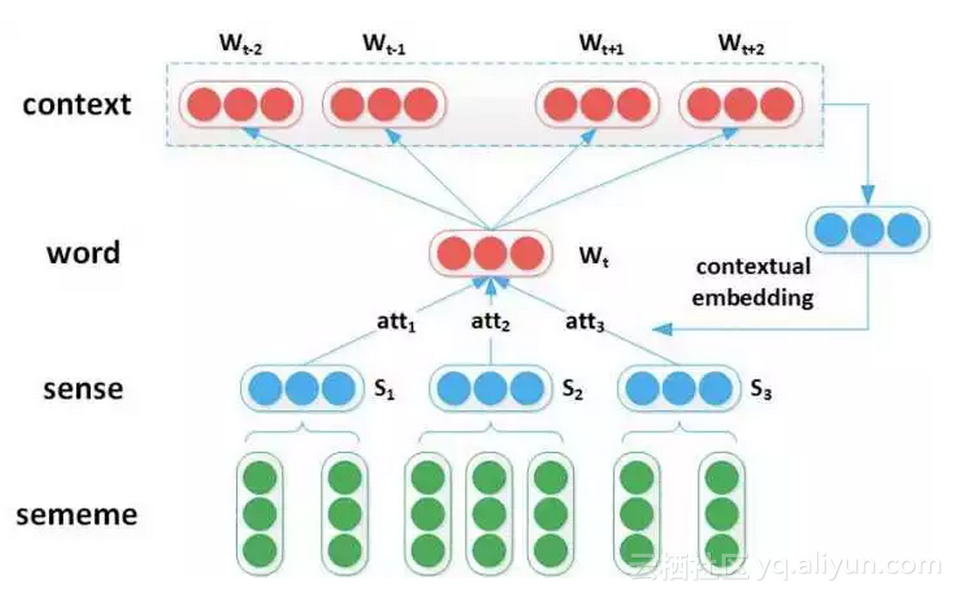
△ SAT(Sememe Attention over Target Model)模型示意图
2. 基于词汇表示的新词义原推荐

- 论文 | Lexical Sememe Prediction via Word Embeddings and Matrix Factorization
- 链接 | https://www.paperweekly.site/papers/450
- 源码 | https://github.com/thunlp/Sememe_prediction
在验证了分布式表示学习与义原知识库之间的互补关系后,我们进一步提出,是否可以利用词汇表示学习模型,对新词进行义原推荐,辅助知识库标注工作。为了实现义原推荐,我们分别探索了矩阵分解和协同过滤等方法。
矩阵分解方法首先利用大规模文本数据学习单词向量,然后用已有词语的义原标注构建“单词-义原”矩阵,通过矩阵分解建立与单词向量匹配的义原向量。
当给定新词时,利用新词在大规模文本数据得到的单词向量推荐义原信息。协同过滤方法则利用单词向量自动寻找与给定新词最相似的单词,然后利用这些相似单词的义原进行推荐。
义原推荐的实验结果表明,综合利用矩阵分解和协同过滤两种手段,可以有效进行新词的义原推荐,并在一定程度上能够发现 HowNet 知识库的标注不一致现象。该技术将有利于提高 HowNet 语言知识库的标注效率与质量。
3. 基于词汇表示和义原知识的词典扩展

- 论文 | Chinese LIWC Lexicon Expansion via Hierarchical Classification of Word Embeddings with Sememe Attention
- 链接 | https://www.paperweekly.site/papers/1499
- 源码 | https://github.com/thunlp/Auto_CLIWC
最近,我们又尝试了利用词语表示学习与 HowNet 知识库进行词典扩展。词典扩展任务旨在根据词典中的已有词语,自动扩展出更多的相关词语。
该任务可以看做对词语的分类问题。我们选用在社会学中享有盛名的 LIWC 词典(Linguistic Inquiry and Word Count)中文版来开展研究。LIWC 中文版中每个单词都被标注层次化心理学类别。
我们利用大规模文本数据学习每个词语的分布式向量表示,然后用 LIWC 词典单词作为训练数据训练分类器,并用 HowNet 提供的义原标注信息构建 sememe attention。实验表明,义原信息的引入能够显著提升单词的层次分类效果。
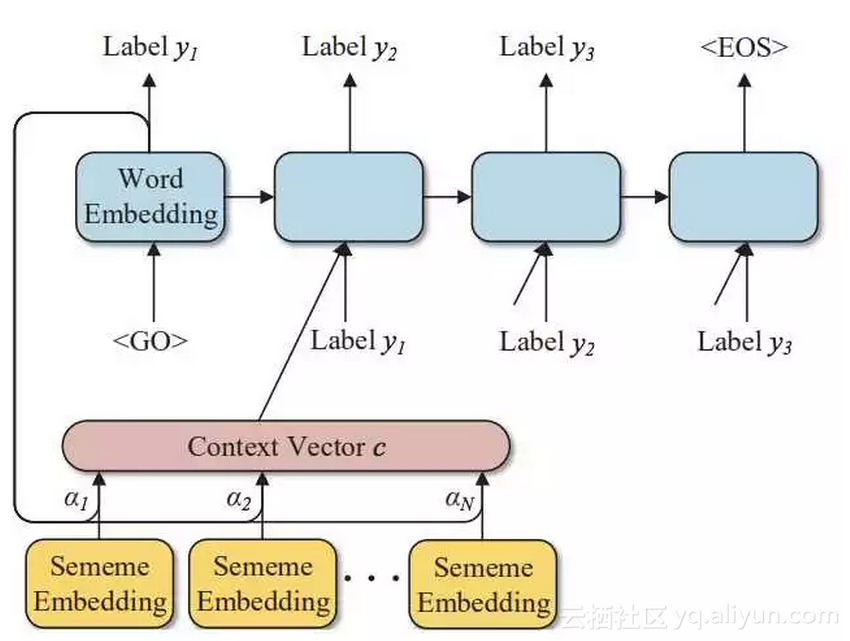
△ 基于Sememe Attention的词典扩展模型
ps. 值得一提的是,这三份工作都是本科生(牛艺霖、袁星驰、曾祥楷)为主完成的,模型方案都很简单,但都是第一次投稿就被 ACL、IJCAI 和 AAAI 录用,也可以看出国际学术界对于这类技术路线的认可。
未来展望
以上介绍的三项工作只是初步验证了深度学习时代 HowNet 语言知识库在某些任务的重要作用。以 HowNet 语言知识库为代表的人类知识与以深度学习为代表的数据驱动模型如何深度融合,尚有许多重要的开放问题亟待探索与解答。我认为以下几个方向深具探索价值:
1. 目前的研究工作仍停留在词法层面,对 HowNet 知识的应用亦非常有限。如何在以 RNN/LSTM 为代表的语言模型中有效融合 HowNet 义原知识库,并在自动问答、机器翻译等应用任务中验证有效性,具有重要的研究价值。是否需要考虑义原标注的结构信息,也值得探索与思考。
2. 经过几十年的精心标注,HowNet 知识库已有相当规模,但面对日新月异的信息时代,对开放域词汇的覆盖度仍存在不足。需要不断探索更精准的新词义原自动推荐技术,让计算机辅助人类专家进行更及时高效的知识库标注工作。
此外,HowNet 义原知识库规模宏大、标注时间跨度长,难免出现标注不一致现象,这将极大影响相关模型的效果,需要探索相关算法,辅助人类专家做好知识库的一致性检测和质量控制。
3. HowNet 知识库的义原体系是专家在不断标注过程中反思总结的结晶。但义原体系并非一成不变,也不见得完美无瑕。它应当随时间变化而演化,并随语言理解的深入而扩展。我们需要探索一种数据驱动与专家驱动相结合的手段,不断优化与扩充义原体系,更好地满足自然语言处理需求。
总之,HowNet 知识库是进入深度学习时代后被极度忽视的一片宝藏,它也许会成为解决 NLP 深度学习模型诸多瓶颈的一把钥匙。在深度学习时代用 HowNet 搞事情,广阔天地,大有可为!
原文发布时间为:2018-01-08
本文作者:刘知远
本文来自云栖社区合作伙伴“PaperWeekly”,了解相关信息可以关注“PaperWeekly”微信公众号