公众号HelloJava刊出一篇《MySQL Statement cancellation timer 故障排查分享》,作者的某服务的线上机器报 502(502是 nginx 做后端健康检查时不能连接到 server 时抛出的提示),他用 jstack -l 打印线程堆栈,发现了大量可疑的“MySQL Statementcancellation timer”,进一步探究原因,原来是业务应用将数据库更新操作和云存储传图操作放在同一个事务。当云存储发生异常时,由于缺少云存储操作的快速失败,并且缺少对整体事务的超时控制,导致整个应用被夯住,进而 502。
作者文中还谈及他排查过程中注意到 MySQL-Connector-Java 的一个 bug,在 5.1.27 版本以前 MySQL Statement cancellation timer 会导致 Perm 区 Leak,内存泄漏后进而业务应用异常。
我们恰巧遇到过这个坑。鉴于这个坑的排查过程和测试验证还挺有趣,我贴一下去年我们的 RCA 报告:
RCA:JDBC驱动自身问题引发的FullGC
郑昀 基于田志全和端木洪涛的分析报告 2015/6/30
关键词:Java,JDBC,升级,MySQL驱动,频繁数据查询,mysql-5.1.34,mysql-5.0.7
问题现象:
问题原因:
RCA类型:
|
第四季案例5 官方驱动也会设计不当,及时升级
——实例:
2013年1月,由于 PHP 一直使用 MongoDB PHP Driver 1.2.x 驱动,导致 PHP-FPM 模式下,每一个 PHP Worker 进程都有自己独立的 mongodb 连接池,从而导致连接数极易超标,占用内存数也随之倍增,MongoDB 负载很重。
如当时编辑后台192 --> mongodb-165 之间的连接数基本维持在:750~751个左右。
升级到 mongodb-php driver 1.3.2 驱动之后,日常连接数大为下降。
——教训:
引入了重要存储介质的驱动之后,如spymemcahced、mongodb php/java driver、jedis等,保持跟踪它们的动态,第一时间更新驱动。
|
问题分析:
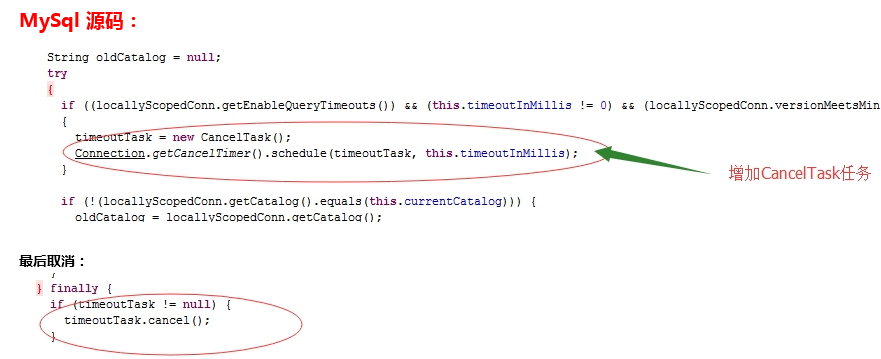
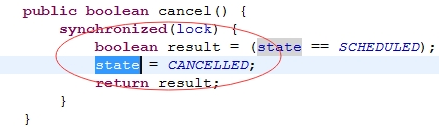
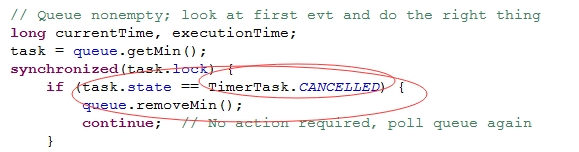
问题解决:
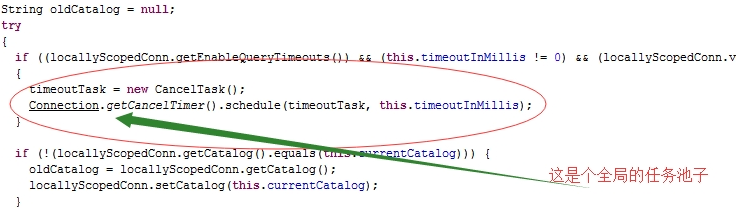
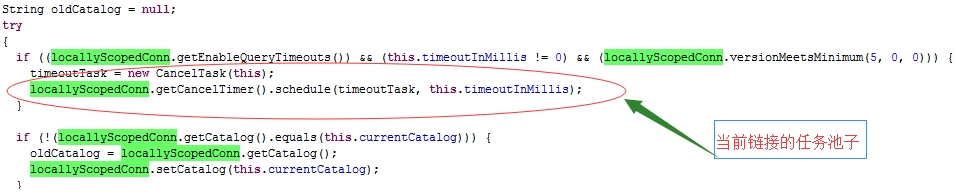
| 测试时间:2015年4月29日 使用taskmall联调环境做测试。 协调器:10.8.210.168 分发器:10.9.210.151、10.9.210.152 执行器:10.9.210.154
分发器配置如下: 151使用mysql-5.1.34驱动,152使用mysql-5.0.7驱动。其中分发器两机器为2核8G配置,统一resin4 JVM配置: <jvm-arg>-Xmx1024M</jvm-arg>
基础准备: 1、往数据库中压入5180条队列数据,(其中151机器分的2614条,152机器分得2566条); 2、改造执行器,使其只接受数据不处理数据。则5180条数据对分发器来说一直都是有效数据; 3、改造分发器,设置ibatis参数:cacheModelsEnabled="true"、defaultStatementTimeout="3000"。每150ms加载一次数据; (分发器起16个线程对应16个cobar分库,每个线程分页加载分库中的有效数据,每页200条数据。) 4、jvisualvm远程监控151、152机器。
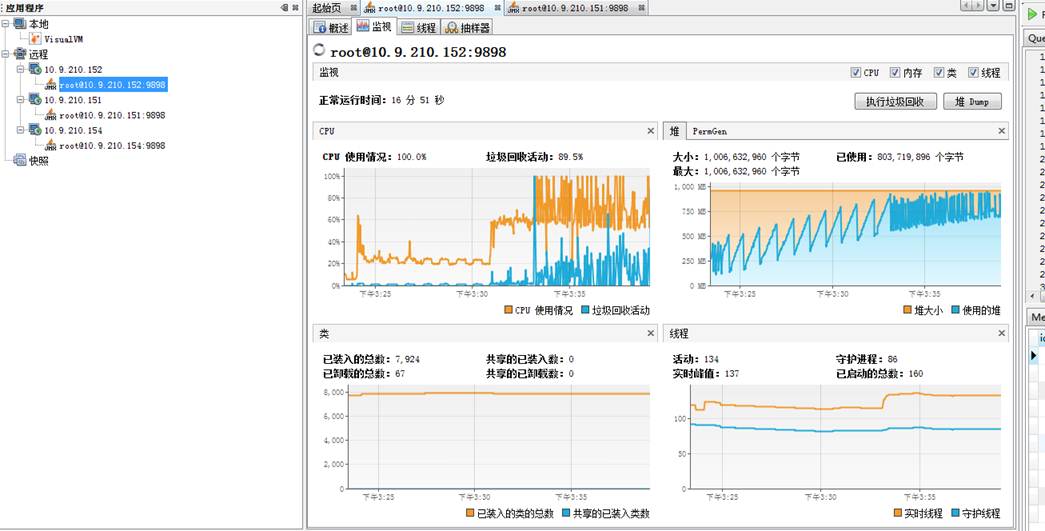
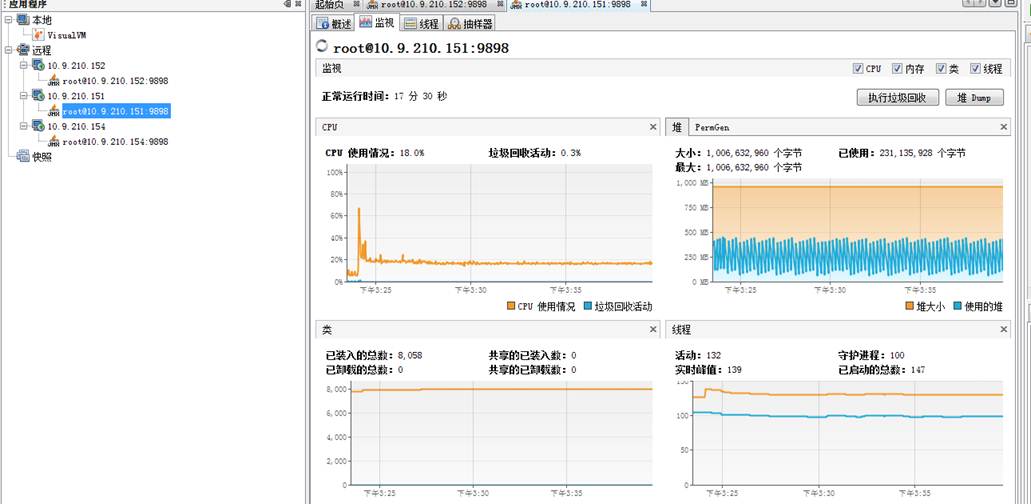
测试结果如下: 一、15分钟后监控结果如下 从图上看出152机器从cpu占用、堆大小在逐渐升高,查看gc日志发现152已经开始出现FullGC。
152机器已快挂:
151机器则一切正常:
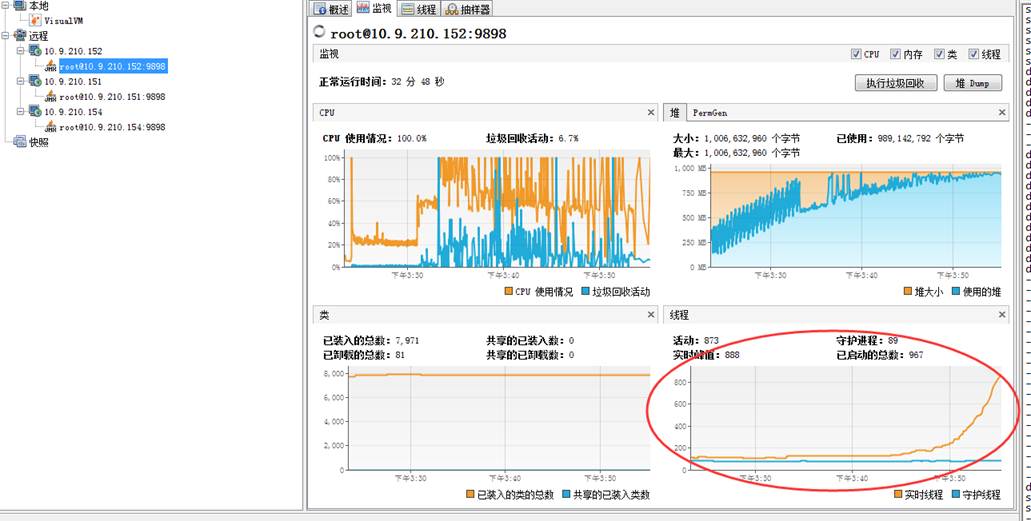
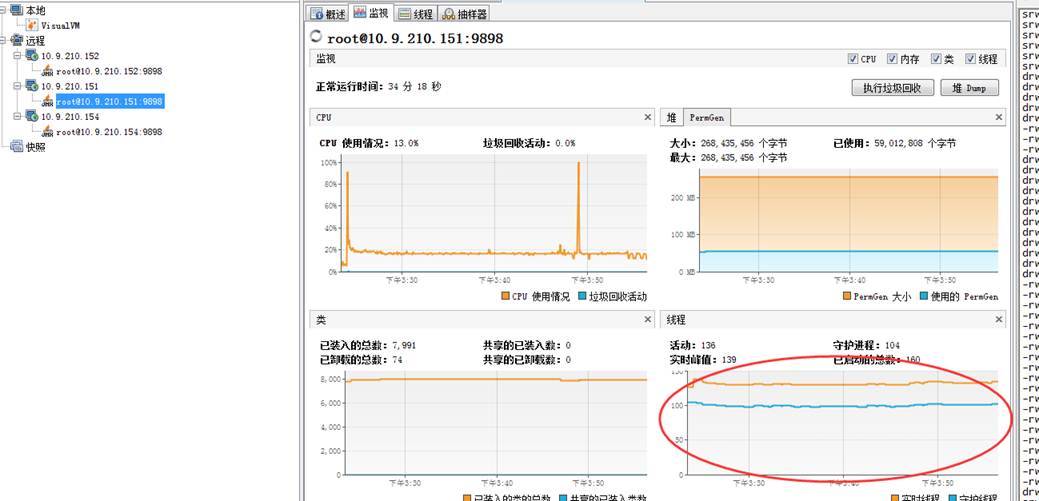
二、32分钟后监控结果如下 此时除了cpu占用、堆飙高外,152的线程数也远远高于151。此时的152已经频繁FullGC了。 152机器:
151机器则:
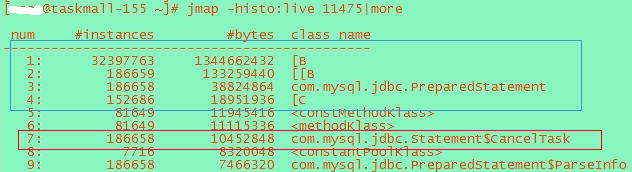
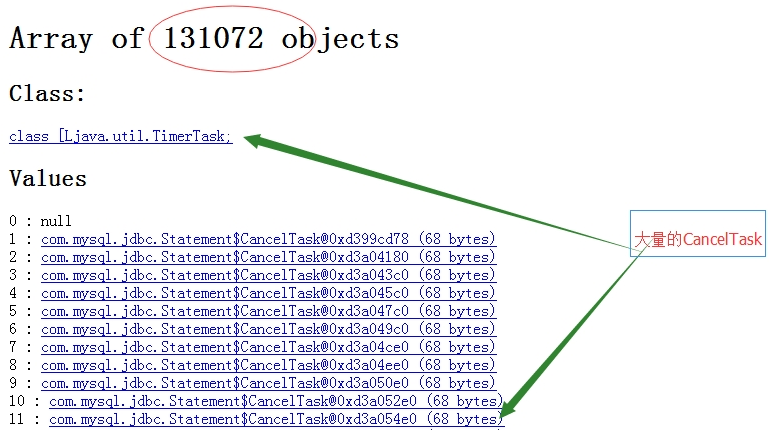
统计堆内存中活着对象数据: 152机器出现大量的Byte数据以及PreparedStatement,以及CancelTask。 1)但是在151机器上前47位的占用排行上找不到CancelTask。 2)在byte数据量上,152机器达到了600M,而151机器只有几十M。
测试结论: 频繁的大数据查询场景下,mysql-5.1.34 驱动的性能处理远优于 mysql-5.0.7 驱动。 |