无私分享两道百度作业帮的测试开发面试题!整理不易,请给赞~
【第一题】一共有二十五匹马,五个赛道,每个赛道每次只能跑一匹马。问:最少多少次能选出3匹最快的马?(不能记录每匹马跑完全程所用的时间,只能通过比较谁先到达终点来判断两匹马的孰快孰慢)
思路如下:
1、前五次:25匹马,分成5组,每组赛1次,共赛5次——这样就能得出5匹马(各组的第一);

2、第六次:让这五匹马赛一次,取前3,淘汰这五匹第一马中的第四和第五(假设是第四组第一和第五族第一),比这两匹马慢的也都淘汰,共淘汰10匹马(第四组和第五组所有马)。
3、剩下的15匹马(第一组、第二组、第三组),因为取前3,所以淘汰每一组中的第四和第五,共淘汰6匹马。
4、现在还剩下9匹马,他们是:

因为第六次比赛的时候已经得出了各组第一马的快慢顺序。假设马的速度——第一组第一>第二组第一>第三组第一。则第一组第一是最快的,所以这匹马无需再比,它就是第一快的。
剩下的八匹马中:
第二组第一、第一组第二,他们俩需要比一次,看看谁是第二快的。
第一组第三、第二组第二、第三组第一,他们仨需要比一次,看看谁是第三快的。
这五匹马正好占五个赛道,比一次,也就是第七次。
所以得出答案:至少需七次比赛,才能选出最快的三匹马。
【第二题】假设一小时内接口共返回500万条数据,数据假设为{id='xxx' info='xxx' kk='xxx' target='' dd='xxx'}这种格式,不同的字段名和字段值间用空格隔开。问:怎么得出target字段返回次数最多的值。
我的思路:先按空格切割字符串,把范围锁定在target字段的值域,把值域存到数组中。然后对数组进行一次去重和计数并保存到一个数据结构中,最后从这个数据结构中找出计数最多的分类,也就是target字段返回次数最多的值。
我的解法如下,分别用了三种方法(正常法、非线程安全集合的并发法、线程安全集合的并发法):
using System; using System.Collections; using System.Collections.Concurrent; using System.Collections.Generic; using System.Linq;
using System.Threading.Tasks; namespace FuckThatPussy { class Program { public static string data; public static List<string> dataSource = new List<string>(); public static List<string> results = new List<string>(); public static Hashtable dataHst = new Hashtable(); public static int maxCount; public static Object obj = new Object(); public static string theLock = "I'm a lock"; public static DateTime startTime; public static DateTime endTime; //Use the concurrent collection to store results. public static ConcurrentDictionary<string, int> dataDic = new ConcurrentDictionary<string, int>(); static void Main(string[] args) { CreateData(); SolveData("Solve the data normally:", SolveDataNormally, FindResultsFromHst); SolveData("Solve the data concurrently:", SolveDataParallel, FindResultsFromHst); SolveData("Solve the data using concurrent collection:", SolveDataConcurrently, FindResultsFromDic); Console.Read(); } private static void SolveData(string v, Action solveDataMethod, Func<List<string>> findResults) { Console.WriteLine(v); startTime = DateTime.Now; solveDataMethod.Invoke(); endTime = DateTime.Now; foreach (var result in findResults.Invoke()) { Console.WriteLine(result + " " + maxCount); } Console.WriteLine("Time use: " + (endTime - startTime).ToString()); } private static List<string> FindResultsFromHst() { //Find the results from dataHst. maxCount = 0; results.Clear(); Parallel.ForEach(dataHst.Values.Cast<int>(), value => { lock (obj) { if (value > maxCount) { maxCount = value; } } }); IDictionaryEnumerator item = dataHst.GetEnumerator(); while (item.MoveNext()) { if (int.Parse(item.Value.ToString()) == maxCount) { results.Add(item.Key.ToString()); } } return results; } private static List<string> FindResultsFromDic() { //Find the results from dataDic. maxCount = 0; results.Clear(); Parallel.ForEach(dataDic.Values.Cast<int>(), value => { lock (obj) { if (value > maxCount) { maxCount = value; } } }); foreach (var data in dataDic) { if (data.Value == maxCount) { results.Add(data.Key); } } return results; } private static void CreateData() { Random ran = new Random(); Parallel.For(0, 5000000, i => { lock (dataSource) { data = "{ id = 'xxx' info = 'xxx' kk = 'xxx' target = '" + ran.Next(1, 200) + "' dd = 'xxx'}"; dataSource.Add(data); } }); Console.WriteLine(dataSource.Count + " data has been created."); } public static void SolveDataNormally() { dataHst.Clear(); int num; foreach (string data in dataSource) { if (!dataHst.Contains(data.Split()[12])) { dataHst.Add(data.Split()[12], 1); } else { num = int.Parse(dataHst[data.Split()[12]].ToString()); num += 1; dataHst[data.Split()[12]] = num; } } } public static void SolveDataParallel() { dataHst.Clear(); int num; Parallel.ForEach(dataSource, data => { lock (dataHst) { if (!dataHst.Contains(data.Split()[12])) { dataHst.Add(data.Split()[12], 1); } else { num = int.Parse(dataHst[data.Split()[12]].ToString()); num += 1; dataHst[data.Split()[12]] = num; } } }); } private static void SolveDataConcurrently() { dataDic.Clear(); Parallel.ForEach(dataSource, data => { lock (obj) { if (!dataDic.ContainsKey(data.Split()[12])) { dataDic.TryAdd(data.Split()[12], 1); } else { dataDic[data.Split()[12]]++; } } }); } } }
运行结果如下:
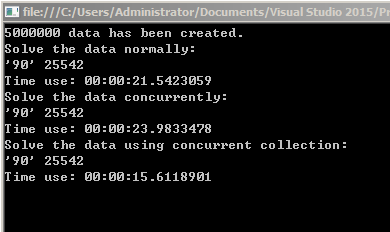
可以看出用C#的线程安全集合是最快的,自己手动加lock做并发的时间比普通的foreach还要慢。因为并发的时候会有判断,判断集合中是否会有相应的元素,如果没有则进行初始化,这里如果不加lock的话将会有并发初始化的事情发生,这样得到的结果值就会比预期结果低。下面是初始化部分的代码:
if (!dataHst.Contains(data.Split()[12])) { dataHst.Add(data.Split()[12], 1); }
目前我没想到什么好的办法可以摘掉锁,因为摘到锁就做不到线程安全了,据我测试线程安全集合类ConcurrentDictionary<TKey, TValue>的TryAdd方法在并发的情况下是不安全的,如果并发字典中不存在我们TryAdd的数据,此时如果并发多个TryAdd方法,TryAdd的返回值均为true,所以还是会导致并发初始化的发生,是不安全的。如果可以摘掉这层锁,时间可以提升一倍,处理500万条数据仅需7秒左右。
经过园友@Eric Liao的指点!最后学会了使用AddOrUpdate这一专业处理并发情况下的Key、Value的线程安全方法!优化后的SolveDataConcurrently方法核心代码如下:
Parallel.ForEach(dataSource, data => { dataDic.AddOrUpdate(data.Split()[12].ToString(), 1, (a, b) => b + 1); });
这一方法的含义是:对data.Split()[12].ToString()这一Key进行判断——
1、如果在dataDic中不存在,则执行Add操作,Add操作所添加的Value值为1;
2、如果在dataDic中存在,则执行Update操作,Update操作所将原有Key的Value b更新为b+1.
于是优化后的SolveDataConcurrently就异常简洁明了:
private static void SolveDataConcurrently() { dataDic.Clear(); Parallel.ForEach(dataSource, data => { dataDic.AddOrUpdate(data.Split()[12].ToString(), 1, (a, b) => b + 1); }); }
执行速度也提升了好几倍,运行两次,测试的结果如下——
第一次:
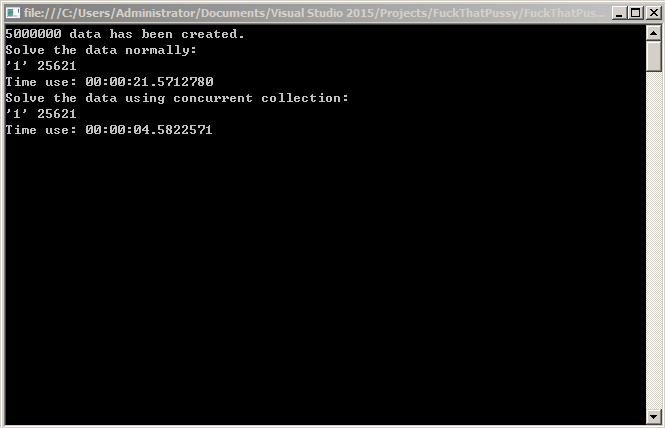
第二次:
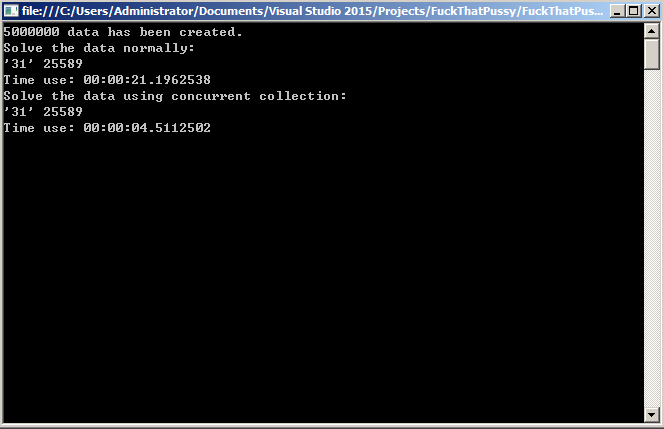
从两次的运算结果可以看出,并发处理速度是正常处理速度的五倍!
经过园友的提示,这种数据处理的任务还可以换用脚本进行,评论中有园友写出了一段Linux下的shell脚本(详见评论9楼),我再加一种Windows下的PowerShell脚本,同样可以解决这个任务,代码如下:
$testFile = "C:\Users\Administrator\Desktop\test3.txt" $hashTable = @{} Write-Host "Processing..." -ForegroundColor yellow Get-Content $testFile | %{$_.Split()[12]} | %{ if(!$hashTable.ContainsKey($_)){ $hashTable.Add($_ , 1) } else{ $hashTable[$_]++; #$hashTable } } $count = $hashTable.Values|measure -Maximum|%{$_.Maximum} $hashTable|%{if($_.Value -eq $count){$_}} $hashTable.Keys|%{if($hashTable[$_] -eq $count){$_+" "+$count}}
相比之下,这种脚本的解法是非常简便的,而且更加灵活。但是也存在一定的问题,比如处理大数据的时候,一个txt文件中包含500万+数据,文件达到300+mb的时候,通过脚本来处理文本信息是非常缓慢的!这是由于Get-Content这个cmdlet导致的。所以当文本数据量较大时,想要高效的并发处理文本信息,还是要用上面的C#并发式解法更好。在文本数据量不大的情况下,用脚本处理更加灵活,便捷。欢迎大家继续讨论!不断升华。