[本文出自天外归云的博客园]
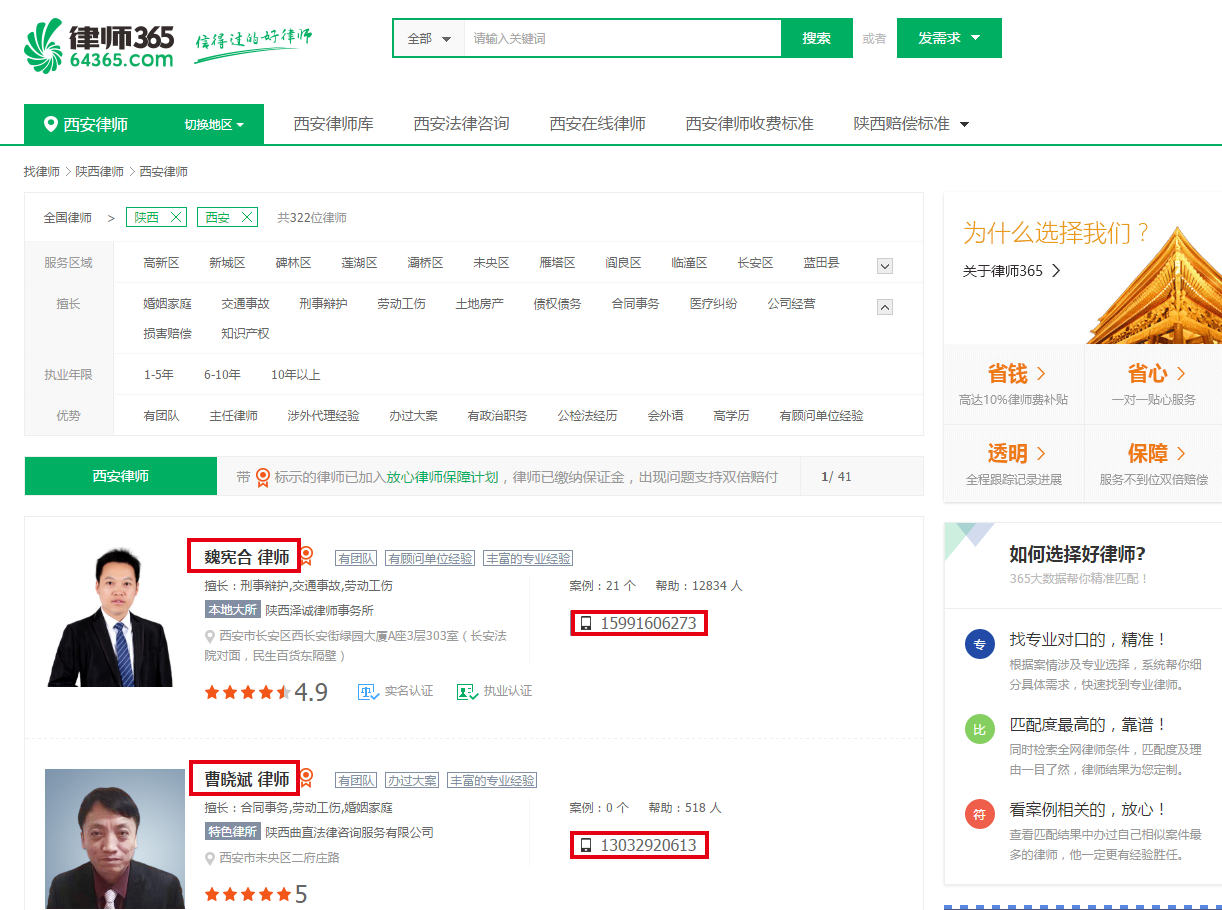
从64365网站获取全国各地律师电话号,用到了python的lxml库进行对html页面内容的解析,对于xpath的获取和正确性校验,需要在火狐浏览器安装firebug和firepath插件。页面内容如下(目标是爬“姓名+电话”):
代码如下:
# coding:utf-8 from lxml import etree import requests,lxml.html,os class MyError(Exception): def __init__(self, value): self.value = value def __str__(self): return repr(self.value) def get_lawyers_info(url): r = requests.get(url) html = lxml.html.fromstring(r.content) phones = html.xpath('//span[@class="law-tel"]') names = html.xpath('//div[@class="fl"]/p/a') if(len(phones) == len(names)): list(zip(names,phones)) phone_infos = [(names[i].text, phones[i].text_content()) for i in range(len(names))] else: error = "Lawyers amount are not equal to the amount of phone_nums: "+url raise MyError(error) phone_infos_list = [] for phone_info in phone_infos: if(phone_info[1] == ""): #print phone_info[0],u"没留电话" info = phone_info[0]+": "+u"没留电话\r\n" #print phone_info[0],phone_info[1] else: info = phone_info[0]+": "+phone_info[1]+"\r\n" print info phone_infos_list.append(info) return phone_infos_list def get_pages_num(url): r = requests.get(url) html = lxml.html.fromstring(r.content) result = html.xpath('//div[@class="u-page"]/a[last()-1]') pages_num = result[0].text if pages_num.isdigit(): return pages_num def get_all_lawyers(cities): dir_path = os.path.abspath(os.path.dirname(__file__)) print dir_path file_path = os.path.join(dir_path,"lawyers_info.txt") print file_path if os.path.exists(file_path): os.remove(file_path) #input() with open("lawyers_info.txt","ab") as file: for city in cities: #file.write("City:"+city+"\n") #print city pages_num = get_pages_num("http://www.64365.com/"+city+"/lawyer/page_1.aspx") if pages_num: for i in range(int(pages_num)): url = "http://www.64365.com/"+city+"/lawyer/page_"+str(i+1)+".aspx" info = get_lawyers_info(url) for each in info: file.write(each.encode("gbk")) if __name__ == '__main__': cities = ['beijing','shanghai','guangdong','guangzhou','shenzhen','wuhan','hangzhou','ningbo','tianjin','nanjing','jiangsu','zhengzhou','jinan','changsha','shenyang','chengdu','chongqing','xian'] get_all_lawyers(cities)
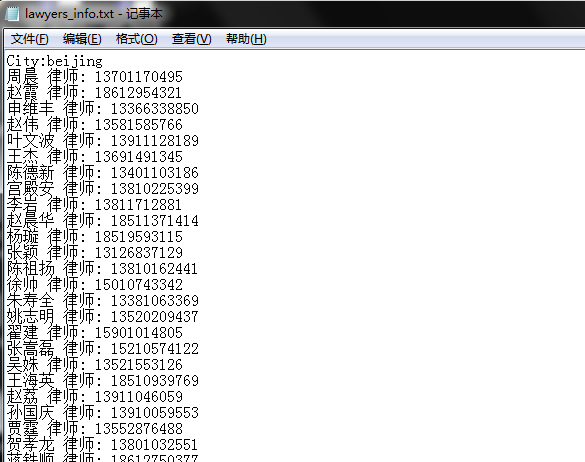
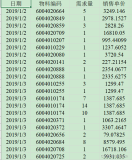
这里对热门城市进行了爬网,输入结果如下(保存到了当前目录下的“lawyers_info.txt”文件中):