前言
2017年8月28日到9月1日,VLDB 2017在慕尼黑工业大学举行,作为数据库领域的三大顶级会议之一,吸引了领域内大量专家、学者以及产业界人士参加。阿里巴巴集团是本次大会的黄金赞助商之一。蚂蚁金服有多位同学参加这次大会,其中包括来自OceanBase的同学和来自GeaBase的同学。本文是同学们此次参会的学习摘要。

▲图1会议展区门口
整体感受
在慕尼黑的一周时间里,除了赶场听报告,就是和论文作者以及同行从业者交流,每天的信息量都很大,除了自己关注的经典的关系数据库领域的进展外,也接触到了不少扩展的知识和应用,以及学术界最新的一些研究方向和思路,收货还是很大的。对本次会议,整体的感受有如下的几点:
1.本次VLDB会议内容涵盖范围很广,思路很开阔。除传统的优化器、引擎、分布式执行、事务并发控制等内容以外;还有大量的大数据处理、图数据、空间数据、文本及半结构化数据、流数据、数据挖掘和分析、众包、社交网络分析、可视化等方面的内容。可以说,凡是和数据存储和处理相关的热点内容,本次会议都涵盖了。
2.在学术界,两个方向的研究当前是比较热门的:一个是基于新硬件(比如NVM、flash、GPU、FPGA)特性的数据库原型系统,研究如何充分利用新硬件的特点来提升数据库的性能以及扩展性;另一个是将传统关系数据库技术应用到大数据处理平台(比如spark),提升处理性能同时降低用户使用门槛。会议的前两场keynote:一个是讲新硬件发展如何推动数据库发展的,另外一个是讲大数据处理平台Spark发展历程的。
3.除学术界外,传统数据库巨头的报告比较多,并且也有一些干货。Oracle在第一天的workshop和后面的会议阶段有好几场报告,讲的内容都还不错,印象比较深的一是FAD的一场报告,谈到了做产品过程中的几个失败决策;另外一个是讲Oracle自适应的统计信息方面的实现。或许因为主场因素,SAP HANA也有几场报告,其中谈到HANA采用NVM存储的实践,因为是第一个按照生产系统要求去做的系统,对后来者也有一定的借鉴意义。作为数据库领域的后来者,SAP HANA的整体表现还是可圈可点的,尤其是在采用新技术方面,前几年就有报告显示查询计划是用LLVM编译执行的。
4.华人在数据库领域的力量持续加强。本次会议颁发的几项大奖都被华人夺得,包括10年最佳论文和优秀青年学者奖。多场报告的主持人或主讲人也都是华人,会场中、会后讨论及聚会中也随处都能看到华人身影,据说参加本次VLDB会议的华人超过200人。我们也在茶歇的时候,和不少华人进行了交流,了解他们的研究方向和进展,同时也介绍了蚂蚁的业务和OceanBase数据库等的发展,希望后续能有更多的合作机会。
议题分享
一周的会议,信息量很大。会议期间的讨论加上会后的论文阅读,收获还是挺大的。下面就笔者感兴趣的几个方向,分享一下相关的议题及个人感想。
FADS
FADS(Failed Aspirations in Database Systems),顾名思义,是数据库领域一些失败经历的总结,给从业者提供了非常有价值的参照。
Oracle在这个环节有两场报告,一场是关于XML和面向对象数据库发展历程的,这两个方向一度都非常热,无论是学术界还是数据库厂商,都投入了大量的人力进行这方面的研究。目前现状也很明确,始终也没有大规模应用,是一个无足轻重的特性。另一场是关于Cache相关特性和产品的。
- Cache的演进
无论是为了减少响应时间还是提高系统的吞吐率,在数据库系统之上增加一层cache都是一种有效的手段;但也意味着更高的成本。从8i时代起,Oracle就陆续推出了一系列的解决方案:
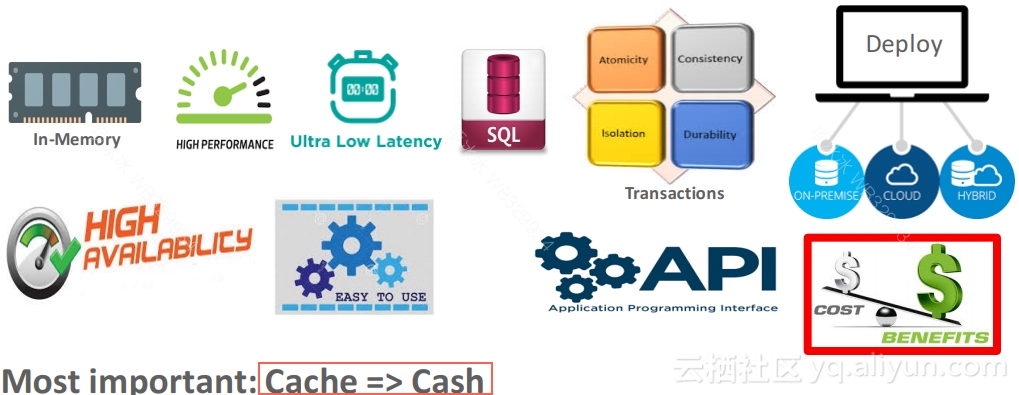
▲图2Cache的价值和成本
8i时代的i-cache,利用一个小型的Oracle数据库系统在应用层缓存表数据,并且周期性地和后端Oracle数据库进行数据同步。优点是缓存系统和后端数据库是完全兼容的,都是Oracle嘛!并且也提高了性能。缺点一是成本高;二是应用要改造,因为Cache中的数据很有可能不是最新的。
在这个方案失败后,Oracle又采用了结果集缓存的方案,包括客户端缓存和服务端缓存,可以缓存整条语句的结果集也可以缓存语句片段的结果集。结果集缓存方案的优点是简单、对应用透明。缺点是场景受限,对于OLTP等更新比较多且重复查询比较少的场景,没有效果。
当前Oracle对于OLTP系统的缓存解决方案,主要是采用Timesten。Timesten是Oracle通过收购获取的产品,凭借性能优势以及和Oracle的高度兼容性,获得了广泛的市场。Timesten的扩展性最初是通过sharding方案把数据分布到多个Timesten实例来实现的,用Oracle的集群管理软件来管理。在多个Timesten实例间用专用的全局数据共享协议来实现数据的互相访问,同时每个Timesten实例采用HA方案实现高可用。这种方案最大的问题是对应用不透明,应用需要针对sharding做改造,并且集群的管理成本高。看起来,这就是分库分表的方案啊!
和上面相比,最新方案(Velocity Scale)就是类似于OceanBase的方案了!Timesten整个集群对外表现为一个数据库,可以动态增删节点,自动数据负载均衡。在集群拓扑图中看不到Oracle作为底层存储,可能对常规应用,在线数据都可以存放在Timesten集群中了?
从Oracle Cache解决方案发展历程中可以看出:在数据库之上增加一层Cache,成本是关键,不仅仅是新增Cache的软硬件成本,还包括运维成本;比成本更重要的是,新增cache是否对应用透明,如果需要修改应用来使用缓存,比如容忍过期数据,则会大大增加业务系统的复杂性和可维护性。对业务来说,还是希望一个all in one的系统来解决存储的问题。
- 其他两个话题
一场是关于Oracle收购的BerkeleyDB产品的,由Margo Seltzer在哈佛的家中远程连线讲的。微软也有两场:一场是关于基于时间戳的并发访问控制的,另一场是关于一个叫Stream Insight的新特性。
对照BerkleyDB(最早的一种key-value store,目前也是Oracle旗下的产品)的发展历程,创始人Margo讲了三个产品发展过程中的错误决策:一个是关于底层存储格式的,由于缺乏长远的考虑,做出了错误的决定,后续付出了重大代价;另一个是关于设计合理API的,讲了一个锁的实现方式;还有一个是支持XML( XML成了本次大会集中反思的对象),BerkleyDB的核心竞争力是作为一种高效的KV-store产品,XML支持和产品发展方向好不相关。
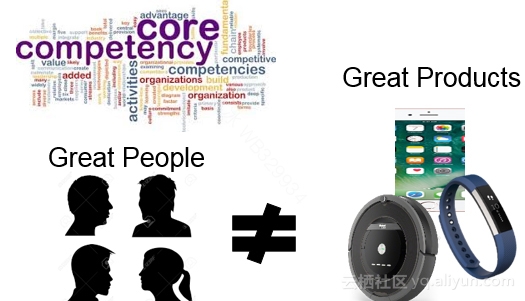
▲图3产品核心竞争力
微软研究院的Philip A. Bernstein讲了基于时间戳的并发访问控制,在70年代的一个系统(SDD-1)中做的,具体内容这里不详述了。他总结的一条经验教训值得思考:最小化系统复杂度。通常情况下:令人印象深刻的论文,意味着难以实现,进而也意味着不切实际(impressive paper è hard to implement è impractical)。
Keynote报告及相关论文
前两场Keynote报告,一篇是关于新硬件对数据库系统设计的影响的;另一篇是关于Spark的发展历程的。
在第一篇Keynote报告中,Wolfgang主要表达了如下的观点:
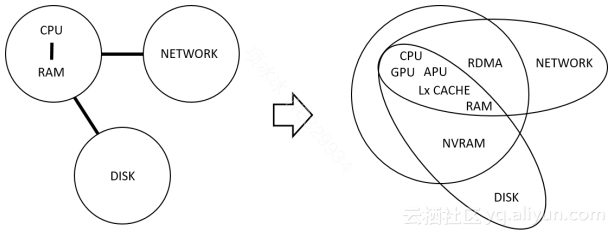
▲图4数据库相关硬件发展
1.下一代的数据库服务器是混合架构的:会包含多种异构的处理器CPU、GPU、FPGA,分别用于处理不同种类的任务,为了减少PCI总线的数据传输速度限制,甚至会将GPU/FPGA和通用CPU做在一个芯片上(”Dark Silicon” effect)。混合架构的计算能力,对计算密集型的任务有很大的价值。
2.存储介质的发展,如大容量的非易失性内存(NVRAM),会对数据库系统的存储架构产生巨大影响,目前RDBMS中的缓冲区管理这样的基础机制都要发生根本性的变化。
3.经济的、高速低延迟的网络的发展,也将给数据库系统的设计带来改变。这一点在工业界也有实际的应用,IBM的pure scale就是建立在基于RDMA网络的share disk集群系统;当前也有不少团队基于RDMA网络做共享存储的数据库集群系统。
在本次会议中,有多篇在混合计算架构及众核服务器上进行性能优化的文章,这些文章都是原型系统,没有看到数据库大厂在这方面的实际进展:
1.Distributed Join Algorithms on Thousands of Cores (http://www.vldb.org/pvldb/vol10/p517-barthels.pdf 注:本文中出现的所有网址请直接复制至浏览器中打开查看,下同 ) 这篇论文是作者在Oracle Labs Zurich做的。在一台几千核的超级计算机上做分布式连接计算,作者用MPI接口实现了两种Join算法:radix hash和sort-merge。测试了两种算法的扩展性、性能以及RDMA、网络调度算法的影响,经过调优在4096个核上,每秒能处理487亿行(两个表的总行数)输入。性能测试结果还是令人印象深刻的。
2.HippogriffDB: Balancing I/O and GPU Bandwidth in Big Data Analytics(http://www.vldb.org/pvldb/vol9/p1647-li.pdf) 这是一篇描述如何在GPU机器上做高效大数据分析计算的文章。因为处理器的并行计算能力强,带宽成了制约性能提升的主要因素。针对这个问题,文章提出了两个方案:一是利用GPU进行数据压缩,以计算能力换网络带宽;二是利用PCIe的端对端数据传输能力建立从SSD存储到GPU缓存的数据传输,减少内存拷贝。对于数据集超过GPU缓存的场景,采用了将整个数据集分块,块内流水线执行的方式,对于Star Schema Query,这样做是可行的。作者对该系统、MonetDB、YDB进行了性能对比测试,在不超过GPU缓存的情况下,SSBM测试性能相对竞品有数量级的提升。
3.Adaptive Work Placement for Query Processing on Heterogeneous Computing Resources(http://www.vldb.org/pvldb/vol10/p733-karnagel.pdf) 这篇论文是Wolfgang团队做的,描述了如何在一个具有混合计算单元(CPU、GPU、FPGA)的服务器上做高效OLAP查询的。中间结果集的规模估算不准是所有查询优化器面临的共同挑战,这篇论文号称是规避了这个问题,采用自适应的方式在执行时决定由哪一个计算单元去执行某个特定算子。
除了新型计算单元的应用外,也有几篇与新型存储介质相关的文章。在这一方面,除了学术界的研究外,SAP在HANA产品上有一些实践,让人印象深刻:
1.SAP HANA Adoption of Non-Volatile Memory (http://www.vldb.org/pvldb/vol10/p1754-andrei.pdf) 这篇文章是目前看到的第一篇在生产系统数据库上采用NVRAM存储实验的实践。SAP HANA是一个内存数据库,也是一个列存数据库。在内存数据组织上,采用了基线数据和更新数据分离的方式,通过合并生成新的基线数据,此外HANA的基线数据和更新数据都全部存放在内存中。
对NVRAM的使用,既可以把它作为内存(DRAM)扩展来用,也可以作为外存(SSD)扩展来用。HANA团队为了不破坏现有的数据库架构,尤其是和WAL机制相关的高可用、容灾及备份恢复等上下游系统,采用NVRAM来存储列的基线数据(如图5所示)。测试的结果还是符合预期的,新系统对Insert操作的RT无影响;单行Select的RT随NVRAM的延迟增大,吞吐率下降;显著提升体现在系统启动预热时间及内存带宽占用显著减少。做这方面研究和系统实现的同学,可以详细了解一下。
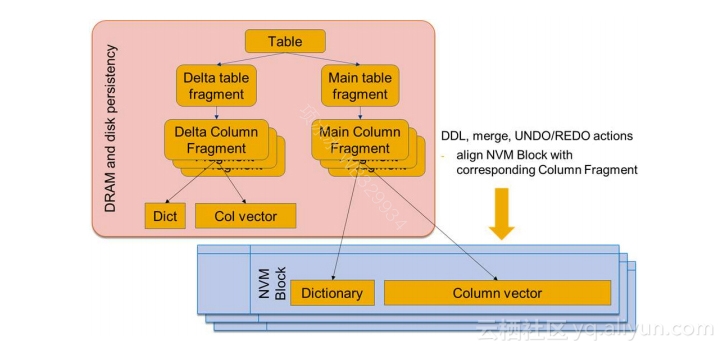
▲图5 SAP HANA对NVRAM的使用
2.BlueCache: A Scalable Distributed Flash-based Key-value Store(http://www.vldb.org/pvldb/vol10/p301-xu.pdf)这篇文章介绍了一个基于闪存的分布式KV Store系统,相对于基于内存的缓存系统(如Redis、Memcached),在大数据量的情况下成本更低,能耗也小;经过性能优化,相对于存在不能命中缓存的内存缓存系统,整体性能表现也不差。
3.Caribou: Intelligent Distributed Storage(http://www.vldb.org/pvldb/vol10/p1202-istvan.pdf)这篇文章介绍了一个分布式系统的实现,基于新硬件将部分计算下降到存储系统去做。相对于上一篇文章,介绍了更多的实现细节,比如Hash表、内存分配器的实现等,对实现类似系统,有更好的参照性。
4.Memory Management Techniques for Large-Scale Persistent-Main-Memory Systems(http://www.vldb.org/pvldb/vol10/p1166-oukid.pdf)这是一篇介绍NVM场景下的内存分配器的设计和实现的,NVM在生产系统中大范围使用之前,面临不少挑战,一个合适的内存分配器是非常必要和有价值的。要解决碎片的问题、泄露的问题、数据一致性问题、异常恢复的问题。该文章对这些问题都有考虑,可供系统实现的时候参考。
第二场Keynote是Michael Franklin做的关于大数据处理软件发展历程的,和计算机领域另两个著名的Michael(Michael Stonebraker、Michael Jordan)一样,此君也是一位牛人,是伯克利有名的AMP Lab的联合创始人和主管。这个实验室在大数据发展历程中有非常重要的影响力,其中就包括创建Apache Spark。和第一场Keynote展望未来不同,本场以叙述已经发生的事情为主,以Spark的发展历程来讲述大数据领域的挑战,解决的思路方法,以及和传统关系数据库的关系。
大数据平台(如Hadoop、Spark)在可扩展性、容错和性能方面面临非常大的挑战,随着不断丰富的应用场景,对性能的要求越来越高,同时易用性、安全、隐私、数据质量以及种类繁多的异构数据源问题也不断地涌现。好消息是传统数据库发展过程中已经或多或少地解答了这些问题。通过不断借鉴传统数据库领域的已有成果,大数据平台近年取得了长足的进步。在演讲的过程中,Michael Franklin也引用了Michael Stonebraker的几篇著名的对大数据平台的评论,比如《MapReduce: A major step backwards》,语气中不乏调侃。最后他给出了四点结论:
1.数据库领域从上到下经历了巨大的变化
2.大数据软件是一个典型的颠覆性的技术
3.数据库思维是提升大数据领域价值链的关键
4.为了取得更大的成果,我们必须丢掉一些陈旧的观念
除主题演讲外,有一篇会议论文介绍如何在HPC上利用MPI接口来释放计算能力,从而提升Spark系统性能,感兴趣的同学可以看一下。Bridging the Gap between HPC and Big Data frameworks(http://www.vldb.org/pvldb/vol10/p901-anderson.pdf)
数据库经典议题
在经典议题方面,统计信息和查询优化、分布式事务、并发控制以及分布式查询都有一些论文,呈现了一些有意思的特点,比如:数据库厂商仍然在死磕统计信息的准确性和基于统计信息的查询优化;学术界选择放弃依靠统计信息,采用曲线救国的方式来做特定场景(比如SSB)的优化。又比如:并发控制方面的文章,综述性质的有好几篇,可能这方面比较难有大的突破和创新了。
如上文所述,学术界在回避统计信息不准确引发的问题,转而去解决特定场景的问题,比如这篇文章:Looking Ahead Makes Query Plans Robust(http://www.vldb.org/pvldb/vol10/p889-zhu.pdf)这是针对OLAP中Star Schema Benchmark(SSB)场景的计划生成及执行优化的。SSB是在OLAP中是一种典型场景,若干张做连接的表中有一张Fact表,数据量比较大;其他的是Dimension表,数据量和Fact表有数量级的差异;Fact表和每一张Dimension表都有主外键关联。这种场景通常会生成左深树的计划:
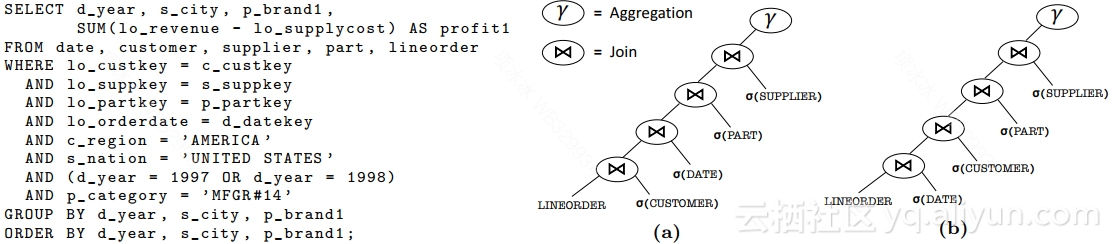
▲图6 Star Join计划
由于不同Dimension表和Fact表连接的时候,连接条件的选择率差异较大,所以不同连接顺序情况下,查询性能表现差异也很大。在经典的优化器算法中,确定连接顺序依赖连接条件的选择率,而估算连接条件的选择率又强依赖统计信息,但是统计信息往往又不是那么靠谱。怎么办?这篇文章的思路是减少对统计信息的依赖,通过一种手段,让连接顺序对执行性能的影响变小。做法也比较直观,在SSB场景下,这种方法是适用的:
1.连接算法采用Hash Join,Dimension表毫无疑问作为内表,在Dimension表创建hash表的时候生成一个连接键上的Bloom Filter。
2.在执行连接操作之前,将每一个Dimenstion表生成的Bloom Filter都下降到Fact表上过滤行。
3.在Fact表上应用多个Bloom Filter的时候,批量地处理Fact表的行,计算每个Bloom Filter的选择率,并且根据选择率自适应地调整Bloom Filter的顺序。以便进一步减少计算量。
4.在这种情况下,经过Bloom Filter过滤后的Fact表行再和各个Dimension表做连接,在Bloom Filter的false positive表现合理的情况下,连接顺序对整体性能的影响就不太大了。
和学术论文中避实就轻的方式不同,数据库厂商迎难而上:提高统计信息的准确性和自适应采样能力。Oracle和SAP分别有一篇关于统计信息的文章。SAP的文章干货不多Statisticum: Data Statistics Management in SAP HANA(http://www.vldb.org/pvldb/vol10/p1658-nica.pdf),其中提了一个概念”implied data statistics constraint”。简单地理解:就是为数据块生成一些统计信息,比如每个列的最大、最小值,然后在查询执行的时候根据这些统计信息以及查询条件做动态的分区裁剪。这种块级别的统计信息,其实前几年就已经是列存数据库产品的标配了。
重点推荐Oracle的文章:Adaptive Statistics in Oracle 12c (http://www.vldb.org/pvldb/vol10/p1813-zait.pdf)完整介绍了Oracle 12c的自适应统计信息,包括两个主要部分:怎样采样统计信息以及如何利用SPD机制在估算不符合实际情况的时候触发重新采样。
▲图7 Oracle的计划生成及执行
为了提高行数估算的准确性,Oracle通过执行类似用户查询的语句(图8)去获取满足条件的行数,采样的目的是减少参与计算的块数。在如何做自适应Sampling以及如何评估采样数据已经满足期望,将误差控制在特定的范围内,文章详细地给出了方法并且进行了严格的数学推导。用于采样的语句形如:

▲图8 Oracle采样语句
在做查询优化的过程中执行采样语句是有代价的,会增大用户语句的延迟,所以要尽量减少,减少的策略就是按需执行。在语句执行的过程中,会收集每个算子真实结果集行数信息,如果该值和统计信息中的值差异超过阈值,就会为该查询生成一个SQL Plan Directive(SPD)。SPD是存在Oracle的系统表中并且在SGA中有缓存的,作用是告诉优化器,哪些语句或者语句片段现有的统计值已经不准确了,需要通过采样的方式重新获取统计信息。图9是模块之间通过SPD进行自适应的统计信息收集及应用的流程。
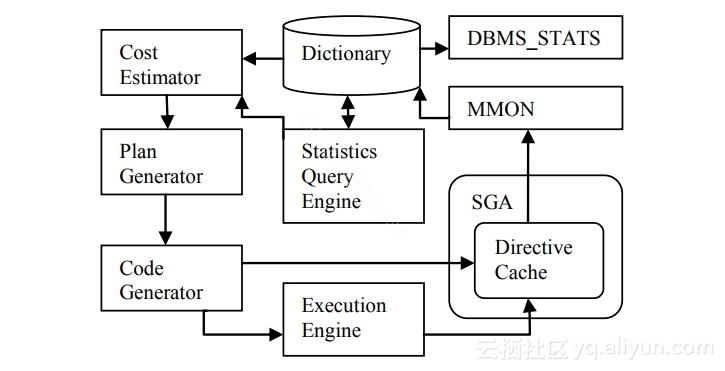
▲图9 Oracle自适应统计信息工作流
论文中有很多细节的描述,比如采样的策略、如何判断采样数据是否在误差范围内、以及特殊场景(没有满足条件的行)的处理;又比如SPD如何存储、关键字是什么、是用参数化的形式还是实例化的形式等等。具有很强的可操作性。针对该论文,后续有必要做一次专门的分析和分享。
除这两篇外,还有一篇讲述根据条件的选择率动态调整条件执行顺序的文章,Non-Invasive Progressive Optimization for In-Memory Databases(http://www.vldb.org/pvldb/vol9/p1659-zeuch.pdf)这篇文章关注的点是查询条件的执行顺序对性能的影响的,比如在单表扫描上有三个and关系连接的条件,因为每个条件的选择率不同,先计算哪个条件、后计算哪个条件对性能有影响。这个动态调整的思路由来已久,本文提出了一种可以利用CPU的performance counter来评估条件计算的代价,评估成本比较低,这可能是一个有价值的点。
除此以外,还有几篇关于并行查询和并发控制相关的文章列在下面,有兴趣的可以选择查看。
- 事务及并发控制
1.The End of a Myth: Distributed Transaction Can Scale(http://www.vldb.org/pvldb/vol10/p685-zamanian.pdf) 一种扩展性良好的分布式事务实现
2.An Empirical Evaluation of In-Memory Multi-Version Concurrency Control(http://www.vldb.org/pvldb/vol10/p781-Wu.pdf) 对多种并发控制协议在内存数据库环境下进行了原型验证
3.High Performance Transactions via Early Write Visibility(http://www.vldb.org/pvldb/vol10/p613-faleiro.pdf)让写操作对其他事务提前可见,或许是一种解决热点行问题的方式
4.Write-Behind Logging (http://www.vldb.org/pvldb/vol10/p337-arulraj.pdf)利用NVM特性实现了一个新的写日志及根据日志进行系统恢复的协议
- 分区并行
1.AdaptDB: Adaptive Partitioning for Distributed Joins(http://www.vldb.org/pvldb/vol10/p589-lu.pdf)
2.Clay: Fine-Grained Adaptive Partitioning for General Database Schemas(http://www.vldb.org/pvldb/vol10/p445-serafini.pdf)
3.SquirrelJoin: Network-Aware Distributed Join Processing with Lazy Partitioning (http://www.vldb.org/pvldb/vol10/p1250-rupprecht.pdf)
后记
在VLDB会议期间参加了主办方举办的两次活动,也在慕尼黑市区转了几圈。虽然城市不大,但是处处都有历史的痕迹。在数据库领域,德国人的创新能力还是很突出的,有一些知名的产品,比如SAP HANA、Exa solution、HyPer,都是所在领域的佼佼者和先行者,这一点值得我们去学习和反思。
但是作为德国的第三大城市,慕尼黑看起来远没有中国的一线城市那么有活力,有点暮气沉沉。除机场外(部分机场免税店支持支付宝),几乎没有移动支付,用的都是现金和信用卡;没有共享单车,感受不到移动互联网的蓬勃发展以及给生活带来的便利。两相对比,由衷地感受到国内互联网领域的发展之快,以及给人们的衣食住行带来的巨大便利。







