简介
本文将介绍如何利用阿里云的sls插件功能和emr来进行mysql binlog的准实时传输
基本架构
rds -> sls -> spark streaming -> spark hdfs
主要包含3个链路:
1. 怎么把rds的binlog收集到sls
2.怎么通过spark streaming将sls中的日志读取出来,进行分析
3.怎么把2中读取和处理过的日志,保存到spark hdfs中
环境准备
需要mysql类型数据库、开通sls服务并添加对应的project和logstore、然后创建一个emr集群。
具体步骤
准备好mysql数据库环境,添加用户权限
首先需要一个mysql类型数据库(使用mysql协议,例如RDS、DRDS等),
数据库开启binlog,且配置binlog类型为ROW模式(RDS默认开启)。
1. 先检查下环境:
### 查看是否开启binlog
mysql> show variables like "log_bin";
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_bin | ON |
+---------------+-------+
1 row in set (0.02 sec)
### 查看binlog类型
mysql> show variables like "binlog_format";
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| binlog_format | ROW |
+---------------+-------+
1 row in set (0.03 sec)
2. 添加权限,当然也可以直接通过rds控制台添加:
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;
开通sls,添加对应的配置文件,并检查数据是否正常采集
需要开通sls,并在sls控制台添加对应的project和logstore,例如:我创建的project叫canaltest,logstore叫canal.
然后对sls进行配置,配置文件目录在:/etc/ilogtail下创建文件:user_local_config.json,具体配置文件如下:
{ "metrics": { "##1.0##canaltest$plugin-local": { "aliuid": "****", "enable": true, "category": "canal", "defaultEndpoint": "*******", "project_name": "canaltest", "region": "cn-hangzhou", "version": 2 "log_type": "plugin", "plugin": { "inputs": [ { "type": "service_canal", "detail": { "Host": "*****", "Password": "****", "ServerID": ****, "User" : "***", "DataBases": [ "yourdb" ], "IgnoreTables": [ "\\S+_inner" ], "TextToString" : true } } ], "flushers": [ { "type": "flusher_sls", "detail": {} } ] } } } }
其中detail中的Host和Password等信息为MySQL数据库信息,User请用之前授权过的用户名。
aliUid、defaultEndpoint、project_name、category请根据自己的实际情况填写对应的用户和sls信息。
配置好后,我们过2分钟左右,通过sls控制台,看下数据有没有上来,具体如图:

如果没有正常采集上来,请根据sls的提示,查看sls的采集日志进行排查。
准备好代码,编译成jar包,上传到oss
- 代码准备
我们可以将emr的example代码通过git复制下来,修改下,具体命令如下:
git clone https://github.com/aliyun/aliyun-emapreduce-demo.git
example代码中已经有LoghubSample这个类,主要用于从sls采集数据,然后直接打印出来。
我们只要稍做修改,就可以达到我们的目的了。
以下是我修改后的代码:
package com.aliyun.emr.example import org.apache.spark.SparkConf import org.apache.spark.storage.StorageLevel import org.apache.spark.streaming.aliyun.logservice.LoghubUtils import org.apache.spark.streaming.{Milliseconds, StreamingContext} object LoghubSample { def main(args: Array[String]): Unit = { if (args.length < 7) { System.err.println( """Usage: bin/spark-submit --class LoghubSample examples-1.0-SNAPSHOT-shaded.jar | | """.stripMargin) System.exit(1) } val loghubProject = args(0) val logStore = args(1) val loghubGroupName = args(2) val endpoint = args(3) val accessKeyId = args(4) val accessKeySecret = args(5) val batchInterval = Milliseconds(args(6).toInt * 1000) val conf = new SparkConf().setAppName("Mysql Sync") // conf.setMaster("local[4]"); val ssc = new StreamingContext(conf, batchInterval) val loghubStream = LoghubUtils.createStream( ssc, loghubProject, logStore, loghubGroupName, endpoint, 1, accessKeyId, accessKeySecret, StorageLevel.MEMORY_AND_DISK) loghubStream.foreachRDD(rdd => rdd.saveAsTextFile("/mysqlbinlog") ) ssc.start() ssc.awaitTermination() } }
其中主要改动是:
loghubStream.foreachRDD(rdd =>
rdd.saveAsObjectFile("/mysqlbinlog")
)
这样在emr里运行时,就会把spark streaming中流出来的数据,保存到emr的hdfs中。
注意:
- 由于如果要在本地运行起来,请在本地环境提前搭建hadoop集群。
- 由于emr的spark sdk做了升级,他的example code有点旧,不能直接在参数中传递oss的accessKeyId、accessKeySecret 而是需要通过sparkConf设置进来。
trait RunLocally { val conf = new SparkConf().setAppName(getAppName).setMaster("local[4]") conf.set("spark.hadoop.fs.oss.impl", "com.aliyun.fs.oss.nat.NativeOssFileSystem") conf.set("spark.hadoop.mapreduce.job.run-local", "true") conf.set("spark.hadoop.fs.oss.endpoint", "YourEndpoint") conf.set("spark.hadoop.fs.oss.accessKeyId", "YourId") conf.set("spark.hadoop.fs.oss.accessKeySecret", "YourSecret") conf.set("spark.hadoop.job.runlocal", "true") conf.set("spark.hadoop.fs.oss.impl", "com.aliyun.fs.oss.nat.NativeOssFileSystem") conf.set("spark.hadoop.fs.oss.buffer.dirs", "/mnt/disk1") val sc = new SparkContext(conf) def getAppName: String }
- 在本地调试时,需要把
loghubStream.foreachRDD(rdd =>
rdd.saveAsObjectFile("/mysqlbinlog")
)
中的/mysqlbinlog修改成本地hdfs的地址
- 代码编译
在本地调试完成后,我们可以通过如下命令进行打包编译:
mvn clean install- 上传jar包
通过oss控制台或oss的sdk将target/shaded目录下的examples-1.1-shaded.jar上传到oss上
我在oss上建立了bucket为qiaozhou-emr/jar的目录,这个上传后的jar包地址为oss://qiaozhou-emr/jar/examples-1.1-shaded.jar注意,这个地址在后续会用上,如下图:

搭建emr集群,创建任务,运行执行计划,查看结果
- 首先我们需要通过emr控制台创建一个emr集群,这个过程比较漫长,需要10分钟左右,请耐心等待
- 创建类型为spark的作业
--master yarn --deploy-mode client --driver-memory 4g --executor-memory 2g --executor-cores 2 --class com.aliyun.emr.example.LoghubSample ossref://emr-test/jar/examples-1.1-shaded.jar canaltest canal sparkstreaming $sls_endpoint $sls_access_id $sls_secret_key 1
请根据你的具体配置将
sls_access_id $sls_secret_key替换成真实值
注意参数的顺序,否则会报错。
3. 创建执行计划,将作业和emr集群绑定后,开始运行
4. 找到master节点的ip,如图:

通过ssh登录上去后,执行命令:
hadoop fs -ls /就会看到mysqlbinlog开头的目录,再通过命令:
hadoop fs -ls /mysqlbinlog查看mysqlbinlog文件,如图:

最后还可以通过命令:
hadoop fs -cat /mysqlbinlog/part-00000如图:
查看文件内容,是不是很神奇呀?
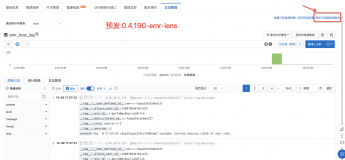
错误排查
如果没有出来正常的结果,可以通过emr的运行记录,来进行问题排查,如图: