抽时间处理一下之前积压的一些笔记.前段时间有网友 @稻草人 问字符串截断的问题"各位大侠 erlang截取字符串一般用哪个函数啊",有人支招用string:substr/3,紧接着他补充了一下"大侠们 一个字符串有汉字和字母组合我想截取 但是不管用什么方法每个汉字的长度都是3 字母是1 截取出来总是有乱码 还望高手们赐教",我们一步步看看这个问题.
在Eshell先看下什么情况,貌似结果很理想啊,但是考虑到
Erlang Shell和文件对编码的处理方式不一致,还是要写段代码测试下
6> string:substr("abcd我们就是喜欢Erlang,就是喜欢OTP",4,3). [100,25105,20204] 7> io:format("~ts",[v(6)]). d我们ok
同样的代码贴到文件里面,编译后执行,看结果:

Eshell V5.10.2 (abort with ^G) 1> u:sub(). [100,230,136] 2> io:format("~ts",[v(1)]). dæok 3> q(). ok 4>
傻眼了吧,之所以出现这种情况是因为EShell是按照UTF-8编码读取的代码,而Erlang编译器是按照ISO-latin-1(ISO-8859-1)编码进行代码解析的,所以就出现上面的不一致的"怪现象"了.怎么解决?如果你和我也是R16B01或更高版本,那么就简单了,只需要在源代码文件的头部添加一个文件编码的声明即可:
%% coding: utf-8
重新编译,之后执行结果:
Eshell V5.10.2 (abort with ^G) 1> u:sub(). [100,25105,20204] 2> io:format("~ts",[v(1)]). d我们ok
这个解决方案见Erlang的epp模块,epp模块是Erlang源代码的预处理器(处理宏替换,include文件),所以编码问题它会首当其冲遇到.看代码片段,可知默认编码是latin1,目前支持的编码选项有latin-1和utf-8
-define(DEFAULT_ENCODING, latin1). -spec default_encoding() -> source_encoding(). default_encoding() -> ?DEFAULT_ENCODING. -spec encoding_to_string(Encoding) -> string() when Encoding :: source_encoding(). encoding_to_string(latin1) -> "coding: latin-1"; encoding_to_string(utf8) -> "coding: utf-8".
R16B的epp模块文档中多了下面这段说明:
The Erlang source file encoding is selected by a comment in one of the first two lines of the source file. The first string that matches the regular expression coding\s*[:=]\s*([-a-zA-Z0-9])+ selects the encoding. If the matching string is not a valid encoding it is ignored. The valid encodings are Latin-1 and UTF-8 where the case of the characters can be chosen freely.
在其它语言可以看到一些很奇葩的写法比如在XX管理系统中用中文定义各种类,属性,实现了所谓"中文编程".在Erlang中目前只能是string和注释部分使用unicode,其它部分还要再ISO-latin-1的编码范围内选择.看下文档:
As of Erlang/OTP R16 Erlang source files can be written in either UTF-8 or bytewise encoding (a.k.a. latin1 encoding). The details on how to state the encoding of an Erlang source file can be found in epp(3). Strings and comments can be written using Unicode, but functions still have to be named using characters from the ISO-latin-1 character set and atoms are restricted to the same ISO-latin-1 range. These restrictions in the language are of course independent of the encoding of the source file. Erlang/OTP R18 is expected to handle functions named in Unicode as well as Unicode atoms. http://www.erlang.org/doc/apps/stdlib/unicode_usage.html
R16B之前版本
看了上面的解决方法估计是有人欢喜有人愁,不是所有人都升级到了R16B,特别是R16B的一些
Breaking Changes 更是很多人暂时搁置了升级计划.那在之前的版本如何解决这个问题呢?之前曾经用过ErlDTL,其中有一个Web中常见的功能就是文本超长后截断然后用省略号显示.按照这个线索,找到 erlydtl_filters.erl 代码.把文本截断的两个方法完整的剥离出来,两个方法其中一个是按字符截断,一个是按照词截断.代码如下:
-module(u). -compile(export_all). test() -> t("abcd我们就是喜欢Erlang,就是喜欢OTP",10). test2() -> tw("Youth is not a time of life; it is a state of mind; it is not a matter of rosy cheeks, red lips and supple knees; it is a matter of the will, a quality of the imagination, a vigor of the emotions; it is the freshness of the deep springs of life.",10). dump(FileName,Data)-> file:write_file(FileName, io_lib:fwrite("~s.\n", [Data])). sub()-> string:substr("abcd我们就是喜欢Erlang,就是喜欢OTP",4,3). t(Input,Max) -> truncatechars(Input,Max). tw(Input,Max) -> truncatewords(Input,Max). %% @doc Truncates a string after a certain number of characters. truncatechars(_Input, Max) when Max =< 0 -> ""; truncatechars(Input, Max) when is_binary(Input) -> list_to_binary(truncatechars(binary_to_list(Input), Max)); truncatechars(Input, Max) -> truncatechars(Input, Max, []). %% @doc Truncates a string after a certain number of words. truncatewords(_Input, Max) when Max =< 0 -> ""; truncatewords(Input, Max) when is_binary(Input) -> list_to_binary(truncatewords(binary_to_list(Input), Max)); truncatewords(Input, Max) -> truncatewords(Input, Max, []). truncatechars([], _CharsLeft, Acc) -> lists:reverse(Acc); truncatechars(_Input, 0, Acc) -> lists:reverse("..." ++ Acc); truncatechars([C|Rest], CharsLeft, Acc) when C >= 2#11111100 -> truncatechars(Rest, CharsLeft + 4, [C|Acc]); truncatechars([C|Rest], CharsLeft, Acc) when C >= 2#11111000 -> truncatechars(Rest, CharsLeft + 3, [C|Acc]); truncatechars([C|Rest], CharsLeft, Acc) when C >= 2#11110000 -> truncatechars(Rest, CharsLeft + 2, [C|Acc]); truncatechars([C|Rest], CharsLeft, Acc) when C >= 2#11100000 -> truncatechars(Rest, CharsLeft + 1, [C|Acc]); truncatechars([C|Rest], CharsLeft, Acc) when C >= 2#11000000 -> truncatechars(Rest, CharsLeft, [C|Acc]); truncatechars([C|Rest], CharsLeft, Acc) -> truncatechars(Rest, CharsLeft - 1, [C|Acc]). truncatewords(Value, _WordsLeft, _Acc) when is_atom(Value) -> Value; truncatewords([], _WordsLeft, Acc) -> lists:reverse(Acc); truncatewords(_Input, 0, Acc) -> lists:reverse("..." ++ Acc); truncatewords([C1, C2|Rest], WordsLeft, Acc) when C1 =/= $\ andalso C2 =:= $\ -> truncatewords([C2|Rest], WordsLeft - 1, [C1|Acc]); truncatewords([C1|Rest], WordsLeft, Acc) -> truncatewords(Rest, WordsLeft, [C1|Acc]).
测试代码如下:
test() -> t("abcd我们就是喜欢Erlang,就是喜欢OTP",10). dump(FileName,Data)-> file:write_file(FileName, io_lib:fwrite("~s.\n", [Data])). Eshell V5.10.2 (abort with ^G) 1> u:test(). [97,98,99,100,230,136,145,228,187,172,229,176,177,230,152, 175,229,150,156,230,172,162,46,46,46] 2> 2> u:dump("u_result",v(1)). ok 3>
执行一下结果,那么这次的结果是不是正确呢?[97,98,99,100,230,136,145,228,187,172,229,176,177,230,152,
175,229,150,156,230,172,162,46,46,46]这样的结果着实很难判断,我们使用上面的dump方法把它写到文本里面看看.看看结果:
[root@nimbus demo]# cat u_result
abcd我们就是喜欢....
结果正确,OK,下面我们看ErlyDTL是怎么实现的.我们知道Unicode是变长编码,不同范围的字符使用不同的长度编码.比如下面我们看"开心"这两个字的编码过程,下面的是字符范围和编码模板对照表,更多信息可以参考:
http://www.cl.cam.ac.uk/~mgk25/unicode.html
| Unicode编码(16进制) | UTF-8 字节流模板 |
| 000000 - 00007F | 0xxxxxxx |
| 000080 - 0007FF | 110xxxxx 10xxxxxx |
| 000800 - 00FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 010000 - 10FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
我们先在EShell中把需要的几个数据做出来,然后按照根据字符范围选择三字节编码模板:
Eshell V5.10.2 (abort with ^G) 1> unicode:characters_to_binary("开心"). <<229,188,128,229,191,131>> 2> unicode:characters_to_list("开心"). [24320,24515] 3> integer_to_list(24320,2). "101111100000000" 4> integer_to_list(24515,2). "101111111000011" 5> integer_to_list(23383,2). "101101101010111"
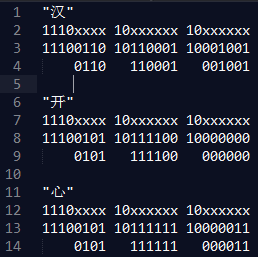
truncatechars实现的要点就是根据上面的字符范围和字节变长规则做了判断,这个从Guard部分的代码就能看出来,在其它语言里面实现这个逻辑也大多如此思路.truncatewords方法实现的是按照单词进行截断,需要判断一下单词边界,比如 "Youth is not a time of life; it is a state of mind; it is not a matter of rosy cheeks, red lips and supple knees; it is a matter of the will, a quality of the imagination, a vigor of the emotions; it is the freshness of the deep springs of life."这段文字做单词截断的结果是"Youth is not a time of life; it is a..."这个就没有什么好说的了.
最后,强烈推荐一个Erlang资源站:
