2、科大讯飞语音识别SDK android版
3、科大讯飞语音识别开发API文档
4、android手机
关于科大讯飞SDK及API文档,请到科大语音官网下载:http://open.voicecloud.cn/
当然SDK和API有多个版本可选,按照你的需要下载,其次,下载需要填写资料申请注册,申请通过或可获得Appid
二、语音识别流程
1、创建识别控件
函数原型
Public RecognizerDialog(Context context,String params)
其中Context表示当前上下文环境,传this即可
Params有参数详见API文档
2、用Appid登录到科大讯飞服务器(自动连接,需要联网)
主要用到SpeechUser(com.iflytek.speech包下)类下的getUser().login()函数
其中getUser()表示获取用户对象,可以实现用户登录,注销等操作
Login函数原型
Public boolean login(Context context,String usr,String pwd,String
参数详见API文档
3、读取语言识别语法
通过abnf文件并读取该文件,实现指定的语言识别语法,比如为了识别并计算国内两个城市之间的距离,abnf文件的内容可以是如下
|
1
2
3
4
5
6
7
|
"#ABNF 1.0 gb2312;
language zh-CN;
mode voice;
root $main;
$main = $place1 到$place2 ;
$place1 = 北京 | 武汉 | 南京 | 天津 | 天京 | 东京;
$place2 = 上海 | 合肥;"
|
Abnf文件的读取参考后面的具体开发实例
4、设置识别参数及识别监听器
通过RecognizerDialog下的setEngine()方法设置参数
函数原型
public void setEngine(String engine,String params,String grammar)
详细的参数请参考API文档
5、识别结果回调
需要实现RecognizerDialogListener接口,其中有两个方法需要重写,分别是
1)public void onResults(ArrayList<RecognizerResult> results,boolean isLast)
其中result是RecognizerResult对象的集合,RecognizerResult的属性有
String text 识别文本
Int confidence 识别可信度
2)public void onEnd(SpeechError error)
6、识别结果处理(自行处理)
自己将文本进行处理。
三、详细开发过程
1、新建Android项目
和普通的android项目一样,只是需要加入科大讯飞语言SDK包,主要包括
Msc.jar及libmsc.so动态库文件,项目lib截图

2、布局
这里只进行简单的布局,只设置一个按钮作为语言识别按钮及一个文本组件用作显示识别结果,布局文件如下
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
<LinearLayout xmlns
:
android
=
"http://schemas.android.com/apk/res/android"
xmlns
:
tools
=
"http://schemas.android.com/tools"
android
:
orientation
=
"vertical"
android
:
layout_width
=
"match_parent"
android
:
layout_height
=
"match_parent"
android
:
paddingBottom
=
"@dimen/activity_vertical_margin"
android
:
paddingLeft
=
"@dimen/activity_horizontal_margin"
android
:
paddingRight
=
"@dimen/activity_horizontal_margin"
android
:
paddingTop
=
"@dimen/activity_vertical_margin"
android
:
background
=
"@drawable/color"
tools
:
context
=
".MainActivity"
>
<ImageView
android
:
id
=
"@+id/voice"
android
:
layout_width
=
"fill_parent"
android
:
layout_height
=
"wrap_content"
android
:
layout_marginTop
=
"100dp"
android
:
src
=
"@drawable/voice"
/>
<TextView
android
:
id
=
"@+id/result"
android
:
layout_height
=
"wrap_content"
android
:
layout_marginTop
=
"50dp"
android
:
layout_gravity
=
"center_vertical"
android
:
layout_width
=
"fill_parent"
android
:
text
=
"提示:请说出你所在的城市"
/>
</LinearLayout>
|
3、识别语法文件
这里只是简答的识别所说的城市名,其中指定了“北京”、“上海”、“广州”、“深圳”、“厦门”
|
1
2
3
4
5
6
7
|
#
ABNF
1.0
gb2312
;
language
zh
-
CN
;
mode
voice
;
root
$
main
;
$
main
=
$
where
;
$
where
=
北京
|
上海
|
广州
|
深圳
|
厦门
;
|
4、MainActivity程序
代码如下,请参考上面的语言识别流程
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
|
package
com
.
example
.
androidclient
;
import
java
.
io
.
InputStream
;
import
java
.
util
.
ArrayList
;
import
com
.
iflytek
.
speech
.
RecognizerResult
;
import
com
.
iflytek
.
speech
.
SpeechError
;
import
com
.
iflytek
.
speech
.
SpeechListener
;
import
com
.
iflytek
.
speech
.
SpeechUser
;
import
com
.
iflytek
.
ui
.
RecognizerDialog
;
import
com
.
iflytek
.
ui
.
RecognizerDialogListener
;
import
android
.
os
.
Bundle
;
import
android
.
app
.
Activity
;
import
android
.
content
.
SharedPreferences
;
import
android
.
view
.
Menu
;
import
android
.
view
.
View
;
import
android
.
view
.
View
.
OnClickListener
;
import
android
.
widget
.
ImageView
;
import
android
.
widget
.
TextView
;
import
android
.
widget
.
Toast
;
public
class
MainActivity
extends
Activity
{
//组件
private
ImageView
voice
=
null
;
private
TextView
result
=
null
;
private
Toast
mToast
=
null
;
//语音识别
private
final
String
APP_ID
=
"514fb8d7"
;
private
final
static
String
KEY_GRAMMAR_ID
=
"grammar_id"
;
private
RecognizerDialog
recognizerDialog
=
null
;
private
String
grammarText
=
null
;
private
String
grammarID
=
null
;
@Override
protected
void
onCreate
(
Bundle
savedInstanceState
)
{
super
.
onCreate
(
savedInstanceState
)
;
super
.
setContentView
(
R
.
layout
.
activity_main
)
;
this
.
voice
=
(
ImageView
)
super
.
findViewById
(
R
.
id
.
voice
)
;
this
.
result
=
(
TextView
)
super
.
findViewById
(
R
.
id
.
result
)
;
//初始化识别
mToast
=
Toast
.
makeText
(
this
,
""
,
Toast
.
LENGTH_SHORT
)
;
mToast
.
setMargin
(
0f
,
0.2f
)
;
recognizerDialog
=
new
RecognizerDialog
(
this
,
"appid="
+
APP_ID
)
;
SpeechUser
.
getUser
(
)
.
login
(
this
,
null
,
null
,
"appid="
+
APP_ID
,
loginListener
)
;
// 读取保存的语法ID
SharedPreferences
preference
=
this
.
getSharedPreferences
(
"abnf"
,
MODE_PRIVATE
)
;
grammarID
=
preference
.
getString
(
KEY_GRAMMAR_ID
,
null
)
;
grammarText
=
readAbnfFile
(
)
;
this
.
voice
.
setOnClickListener
(
new
Voice
(
)
)
;
}
private
class
Voice
implements
OnClickListener
{
@Override
public
void
onClick
(
View
v
)
{
MainActivity
.
this
.
voice
.
setImageResource
(
R
.
drawable
.
voicelight
)
;
recognizerDialog
.
setListener
(
mRecoListener
)
;
recognizerDialog
.
setEngine
(
null
,
"grammar_type=abnf"
,
grammarText
)
;
recognizerDialog
.
show
(
)
;
}
}
//语音识别用户登录监听器
private
SpeechListener
loginListener
=
new
SpeechListener
(
)
{
@Override
public
void
onData
(
byte
[
]
arg0
)
{
}
@Override
public
void
onEnd
(
SpeechError
error
)
{
if
(
error
!=
null
)
{
mToast
.
setText
(
"登录失败"
)
;
mToast
.
show
(
)
;
}
else
{
mToast
.
setText
(
"登录成功"
)
;
mToast
.
show
(
)
;
}
}
@Override
public
void
onEvent
(
int
arg0
,
Bundle
arg1
)
{
}
}
;
//读取语音识别语法
private
String
readAbnfFile
(
)
{
int
len
=
0
;
byte
[
]
buf
=
null
;
String
grammar
=
""
;
try
{
InputStream
in
=
getAssets
(
)
.
open
(
"gm_continuous_digit.abnf"
)
;
len
=
in
.
available
(
)
;
buf
=
new
byte
[
len
]
;
in
.
read
(
buf
,
0
,
len
)
;
grammar
=
new
String
(
buf
,
"gb2312"
)
;
}
catch
(
Exception
e1
)
{
e1
.
printStackTrace
(
)
;
}
return
grammar
;
}
//识别结果回调
private
RecognizerDialogListener
mRecoListener
=
new
RecognizerDialogListener
(
)
{
@Override
public
void
onResults
(
ArrayList
<RecognizerResult>
results
,
boolean
isLast
)
{
String
text
=
""
;
text
=
results
.
get
(
0
)
.
text
;
mToast
.
setText
(
"识别结果为:"
+
text
)
;
mToast
.
show
(
)
;
result
.
setText
(
"识别结果为:"
+
text
)
;
}
@Override
public
void
onEnd
(
SpeechError
error
)
{
MainActivity
.
this
.
voice
.
setImageResource
(
R
.
drawable
.
voice
)
;
}
}
;
}
|
5、给程序相应的权限
|
1
2
3
4
5
6
|
<uses-permission android
:
name
=
"android.permission.RECORD_AUDIO"
/>
<uses-permission android
:
name
=
"android.permission.INTERNET"
/>
<uses-permission android
:
name
=
"android.permission.ACCESS_NETWORK_STATE"
/>
<uses-permission android
:
name
=
"android.permission.ACCESS_WIFI_STATE"
/>
<uses-permission android
:
name
=
"android.permission.CHANGE_NETWORK_STATE"
/>
<uses-permission android
:
name
=
"android.permission.READ_PHONE_STATE"
/>
|
由于本程序用到了网络、麦克风等,需要给定一下权限
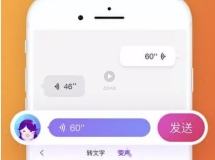
6、结果截图


四、项目文件及android程序下载
项目源文件及android程序安装包
下载地址:http://pan.baidu.com/share/link?shareid=494903&uk=3087605183
本站统一解压密码:www.52wulian.org