利用大数据来做BI分析的时候,必不可少需要设置一些调度任务。
本篇就讲述一下如何利用hue来编辑shell操作,这里面的很多操作在其他的调度操作里面也是可以借鉴的。
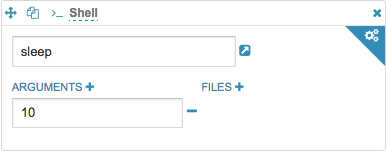
如果是linux里面可以直接执行的脚本,那么可以直接在hue里面使用,比如:

如果有参数,可以点击Arguments添加
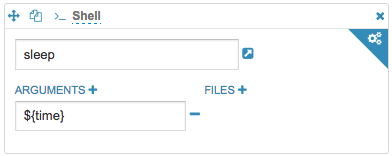
如果你使用了${value}变量,那么在执行任务的时候,就需要指定value参数
点击启动时:

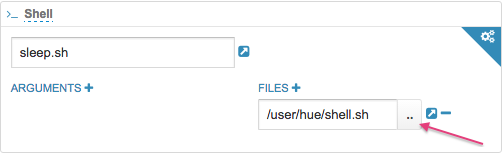
如果想要调用一个可执行的脚本,那么就需要把这个脚本拷贝到Hdfs上,然后选择Choose in files指定该文件,并且填写相应的名字
其他的一些属性,可以通过点击右上角的配置按钮来设置。
在下一个版本,hue会支持标准的unix命令,而不是简简单单的一个命令。
本文转自博客园xingoo的博客,原文链接:图文并茂 —— 基于Oozie调度Sqoop,如需转载请自行联系原博主。