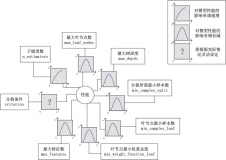
随机森林random forest的pro和con是什么?
优势是accuracy高,但缺点是速度会降低,并且解释性interpretability会差很多,也会有overfitting的现象。
为什么要最大化information gain?
从root到leaf,使得各class distribution的Entropy不断减低。如果相反的话,就会增加预测的不确定性。
熵entrophy的意义是什么?
首先信息量的大小和可能情况的对数函数取值有关系。变量的不确定情况越大,熵越大。
如何避免在随机森林中出现overfitting?
对树的深度的控制也即对模型复杂度的控制,可以在一定程度上避免overfitting,简言之就是shallow tree。此外就是prune,把模型训练比较复杂,看合并节点后的subtree能否降低generation error。随机选择训练集的subset,也可以实现避免overfitting。
Bagging的代价是什么?
Bagging的代价是不用单次决策树来做预测,具体哪个变量起到重要作用变得未知,所以bagging改进了预测准确率但损失了解释性。
Random forest和bagged tree的区别是什么?
随机森林的构建过程中,当考虑每个split时,都只从所有p个样本中选取随机的m个样本,作为split candidate。特别的m大概会取p的平方差。其核心目的是decorrelate不同的树。bagged tree和random forest的核心区别在于选择subset的大小。
什么是GBDT?
通过boosting的方法迭代性的构建week decision tree的ensemble。其优势是不需要feature normalization,feature selection可以在学习过程中自动的体现。并且可以指定不同的loss function。但是boosting是一个sequential process,并非并行化的。计算非常intensive,对高维稀疏数据的feature vector表现相当poor。
GBDT训练的步骤是什么?
使用information gain来获得最好的split。然后根据best split来partition数据。低于cut的数据分至left node,高于cut的数据分至right node。接下来进行boosting,梯度函数可以有多种形式,Gradient是下一棵树的目标。
MapReduce如何实现GBDT呢?
每一个mapper得到<feature value> 以及<residual weight>。reducer积累cuts并且sort。Split数据依据cut,并且输出到DFS。
Classification tree和Regression tree的区别是什么?
优势是accuracy高,但缺点是速度会降低,并且解释性interpretability会差很多,也会有overfitting的现象。
为什么要最大化information gain?
从root到leaf,使得各class distribution的Entropy不断减低。如果相反的话,就会增加预测的不确定性。
熵entrophy的意义是什么?
首先信息量的大小和可能情况的对数函数取值有关系。变量的不确定情况越大,熵越大。
如何避免在随机森林中出现overfitting?
对树的深度的控制也即对模型复杂度的控制,可以在一定程度上避免overfitting,简言之就是shallow tree。此外就是prune,把模型训练比较复杂,看合并节点后的subtree能否降低generation error。随机选择训练集的subset,也可以实现避免overfitting。
Bagging的代价是什么?
Bagging的代价是不用单次决策树来做预测,具体哪个变量起到重要作用变得未知,所以bagging改进了预测准确率但损失了解释性。
Random forest和bagged tree的区别是什么?
随机森林的构建过程中,当考虑每个split时,都只从所有p个样本中选取随机的m个样本,作为split candidate。特别的m大概会取p的平方差。其核心目的是decorrelate不同的树。bagged tree和random forest的核心区别在于选择subset的大小。
什么是GBDT?
通过boosting的方法迭代性的构建week decision tree的ensemble。其优势是不需要feature normalization,feature selection可以在学习过程中自动的体现。并且可以指定不同的loss function。但是boosting是一个sequential process,并非并行化的。计算非常intensive,对高维稀疏数据的feature vector表现相当poor。
GBDT训练的步骤是什么?
使用information gain来获得最好的split。然后根据best split来partition数据。低于cut的数据分至left node,高于cut的数据分至right node。接下来进行boosting,梯度函数可以有多种形式,Gradient是下一棵树的目标。
MapReduce如何实现GBDT呢?
每一个mapper得到<feature value> 以及<residual weight>。reducer积累cuts并且sort。Split数据依据cut,并且输出到DFS。
Classification tree和Regression tree的区别是什么?
回归树的output label是continnuous,而分类树的output label是离散的。因此目标函数也要做相应的调整。特别的regression tree所给出的是probabilistic, non-linear regression,regression tree可以associate未知的独立的测试数据和dependent,continuous的预测。
本文转自博客园知识天地的博客,原文链接:随机森林和GBDT的几个核心问题,如需转载请自行联系原博主。