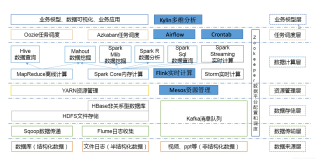
设想一下,当你的系统引入了spark或者hadoop以后,基于Spark和Hadoop已经做了一些任务,比如一连串的Map Reduce任务,但是他们之间彼此右前后依赖的顺序,因此你必须要等一个任务执行成功后,再手动执行第二个任务。是不是很烦! 这个时候Oozie(驯象人,典故来自评论一楼)就派上用场了,它可以把多个任务组成一个工作流,自动完成任务的调用。
简介
Oozie是一个基于工作流引擎的服务器,可以在上面运行Hadoop的Map Reduce和Pig任务。它其实就是一个运行在Java Servlet容器(比如Tomcat)中的Javas Web应用。
对于Oozie来说,工作流就是一系列的操作(比如Hadoop的MR,以及Pig的任务),这些操作通过有向无环图的机制控制。这种控制依赖是说,一个操作的输入依赖于前一个任务的输出,只有前一个操作完全完成后,才能开始第二个。
Oozie工作流通过hPDL定义(hPDL是一种XML的流程定义语言)。工作流操作通过远程系统启动任务。当任务完成后,远程系统会进行回调来通知任务已经结束,然后再开始下一个操作。
Oozie工作流包含控制流节点以及操作节点
控制流节点定义了工作流的开始和结束(start,end以及fail的节点),并控制工作流执行路径(decision,fork,join节点)。操作节点是工作流触发计算\处理任务的执行,Oozie支持不同的任务类型——hadoop map reduce任务,hdfs,Pig,SSH,eMail,Oozie子工作流等等。Oozie可以自定义扩展任务类型。
Oozie工作流可以参数化的方式执行(使用变量${inputDir}定义)。当提交工作流任务的时候就需要同时提供参数。如果参数合适的话(使用不同的目录)就可以定义并行的工作流任务。
总结来说
- Oozie是管理Hadoop作业的工作流调度系统
- Oozie的工作流是一系列的操作图
- Oozie协调作业是通过时间(频率)以及有效数据触发当前的Oozie工作流程
- Oozie是针对Hadoop开发的开源工作流引擎,专门针对大规模复杂工作流程和数据管道设计
- Oozie围绕两个核心:工作流和协调器,前者定义任务的拓扑和执行逻辑,后者负责工作流的依赖和触发。
WordCount工作流例子
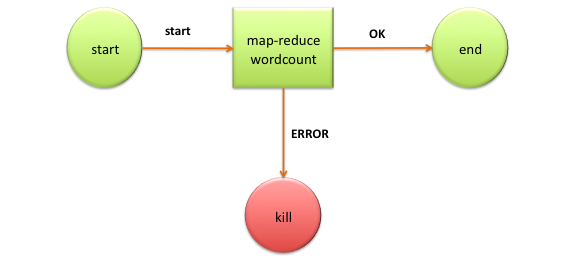
hPDL流程的定义:
<workflow-app name='wordcount-wf' xmlns="uri:oozie:workflow:0.1">
<start to='wordcount'/>
<action name='wordcount'>
<map-reduce>
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.mapper.class</name>
<value>org.myorg.WordCount.Map</value>
</property>
<property>
<name>mapred.reducer.class</name>
<value>org.myorg.WordCount.Reduce</value>
</property>
<property>
<name>mapred.input.dir</name>
<value>${inputDir}</value>
</property>
<property>
<name>mapred.output.dir</name>
<value>${outputDir}</value>
</property>
</configuration>
</map-reduce>
<ok to='end'/>
<error to='end'/>
</action>
<kill name='kill'>
<message>Something went wrong: ${wf:errorCode('wordcount')}</message>
</kill/>
<end name='end'/>
</workflow-app>