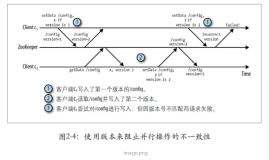
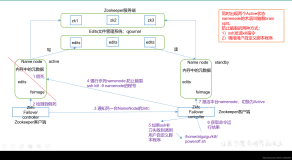
在互联网世界里,算法无处不在。例如:当你打开TweetBook时,是算法决定你会看到什么内容。当你在相册中搜索照片时,也是算法帮你查找,甚至可以为你制作成小视频。当你购买东西时,还是算法标出价格,并且还在你的银行账户中识别诈骗交易。
股票市场也充斥着大量算法交易。出于好奇心,你可能想要了解这些简单算法机器人是如何在你的工作领域工作的。在过去,我们通过给予可以解释的指令来构建算法机器人,例如“if then”语句。但是对一个人类来说,为算法机器人写出简单指令的任务太艰巨、太困难了。比如,一秒内会有大量的金融交易,哪些是诈骗的?在NetMeTube上有无法计算数量的视频,那应该推荐哪八个视频给用户观看呢?哪些视频应该在本网站完全禁止?对这个航空公司的座位,此时用户愿意支付的最高价格是多少?对于这些问题,算法机器人都能给出答案。虽然不是完美答案,但是比人类能做到的要好得多。这些机器人是如何工作的越来越精准的,没有人知道,即使是建造它们的人也不知道。
机器人的大脑构建是一个严格保守的商业机密,而且现在的大脑一般都处于低智商阶段,不能完全理解人们的意思。例如:现在问任何一个网站上的机器人:“我希望你喜欢线性代数”,它们的回答都是“我不知道”。
接下来我们讨论一种可以理解的方法:机器人是否可以被“构建”?假设你想要一个能识别图片的机器人,识别图片中是一个蜜蜂还是一个数字三?这对人类来说非常容易,但是我们无法用机器语言告诉机器人它是什么,因为我们只知道这是一只蜜蜂,那是一个数字“三”。我们能通过说话来描述区分他们,但是机器人不理解我们所说的。那是在我们大脑中的印象轮廓使我们能够识别的出来。虽然个别的神经元可以被了解,神经元的综合行动集合也被大概地掌握,但整体是超越性的。 所以,要得到一个可以进行分类的机器人,只需要建一个机器人去制造机器人,再建一个机器人来教授机器人。制造型机器人制造机器人,尽管他们也不太擅长这个。起初,建造型机器人几乎都是随机的连接这些机器人大脑中的线路和模块,这导致了一些非常“特殊”的机器人被送到教师型机器人那里去教机器人。
当然,教师型机器人也无法分辨蜜蜂和数字“三”,如果人类能够制造出那样的教师型机器人,问题就解决了。教师型机器人不会教,但是能够测试。呆萌的学生机器人非常的努力,但是它们做的却非常糟糕。最后,那些做的好的机器人被放到一边,其他的被回收。制造者机器人仍然不擅长制造机器人,但是现在它将剩下的机器人在重组和改变之后再复制出多个。
现在,制造者机器人随机的制造,教师机器人不教只是测试,学生机器人不会学,理论上是不会出现现在这样的机器人,但是实际中,确实实现了。部分原因在于,在每一次迭代中,制造者机器人都会保留最好的机器人,丢弃其余的,另外部分原因是,教师型机器人并不是只教十几个,而是上千个。考试也不是就十个问题,而是一百万个问题。
幸存的学生型机器人仅仅是因为幸运,但是通过结合足够多的幸运机器人,并且只保留那些有用的,随机的整合新的机器人,最终产生了一个几乎可以分辨蜜蜂和数字三的机器人。随着这个机器人被不断的复制和改进,平均测试分数会慢慢上升,因此,在接下来的一轮中生存下来机器人需要的测试分数也越来越高。一直持续如此,定会出现一个机器人,它能超越之前所有机器人,完美的分辨出一张照片上是一只蜜蜂还是数字“三”。
但是学生型机器人是如何做到的呢?在保留了这么多有用的随机变化之后,它的头部的线路变得异常复杂,它可能理解单个代码行,模糊地理解代码集合的一般用途,然后整体结果是超越的。但这是令人沮丧的,特别是因为学生机器人完全只擅长处理被教给的那些类的问题。
它对识别照片非常有用,但对视频或者颠倒的照片,或者明显不是蜜蜂的照片就毫无用处了。业内公认,足够多的训练数据能够让学生型机器人学的更好,这也是为什么公司痴迷于收集数据的原因:更多的数据等于更长测试时间等于更好的机器人。
所以,当你在网站上回答“你是人类吗?”你不仅证明了你是人类,还帮忙进行了测试,使机器人能够阅读、或者计数、或者分辨山和湖、人和马。
但是机器人真正的想法,或者说它是如何思考的,是不可知的。可以知道的是,这个学生型机器人逐渐变成了算法,因为它与之前的机器人相比,在完成人类设计的测试任务时要高出1%。所以无论在互联网上,还是在幕后,都有一些测试来增加与用户的互动,或者设定最高价格来获取最大化收益,或者从你所有的朋友那里挑出你最喜欢的帖子,或者被其他人分享最多的文章。如果这些东西是可测试的或可教的。“可教的”,一个学生机器人将从数据库中毕业成为该领域的算法程序。我们习惯了使用那些即使我们不了解的工具,有的人能了解,但用这些机器去学习我们越来越多的使用工具或者被工具使用的岗位,然而没有人哪怕是它们的创造者了解它们。我们只能寄希望于通过制定的测试来指导它们,我们需要适应这种情况,毕竟算法机器人到处都是,它在无时无刻的从你身上学习知识。
视频教程网址:
https://weibo.com/tv/v/FApvDjKQ6?fid=1034:49a6ec8e7247924c9ea0cdec9d47271f
本文由北邮@爱可可-爱生活 老师推荐,阿里云云栖社区组织翻译。
文章原标题《How Machines Learn - YouTube》
作者:Lilian Weng
译者:奥特曼,审校:袁虎。