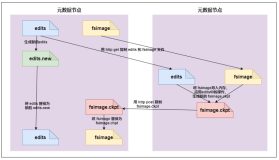
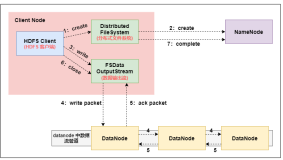
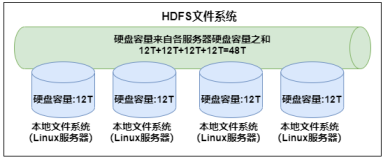
hadoop借鉴了Linux虚拟文件系统的概念,引入了hadoop抽象文件系统,并在此基础上,提供了大量的具体文件系统的实现,满足构建于hadoop上应用的各种数据访问需求
hadoop文件系统API
hadoop提供一个抽象的文件系统,HDFS只是这个抽象文件系统的一个具体的实现。hadoop文件系统的抽象类org.apache.hadoop.fs.FileSystem
hadoop抽象文件系统的方法可以分为两部分:
1、用于处理文件和目录的相关事务
2、用于读写文件数据
hadoop抽象文件系统的操作
| Hadoop的FileSystem |
Java操作 |
Linux操作 |
描述 |
| URL.openSteam FileSystem.open FileSystem.create FileSystem.append |
URL.openStream |
open |
打开一个文件 |
| FSDataInputStream.read |
InputSteam.read |
read |
读取文件中的数据 |
| FSDataOutputStream.write |
OutputSteam.write |
write |
向文件写入数据 |
| FSDataInputStream.close FSDataOutputStream.close |
InputSteam.close OutputSteam.close |
close |
关闭一个文件 |
| FSDataInputStream.seek |
RandomAccessFile.seek |
lseek |
改变文件读写位置 |
| FileSystem.getFileStatus FileSystem.get* |
File.get* |
stat |
获取文件/目录的属性 |
| FileSystem.set* |
File.set* |
Chmod等 |
改变文件的属性 |
| FileSystem.createNewFile |
File.createNewFile |
create |
创建一个文件 |
| FileSystem.delete |
File.delete |
remove |
从文件系统中删除一个文件 |
| FileSystem.rename |
File.renameTo |
rename |
更改文件/目录名 |
| FileSystem.mkdirs |
File.mkdir |
mkdir |
在给定目录下创建一个子目录 |
| FileSystem.delete |
File.delete |
rmdir |
从一个目录中删除一个空的子目录 |
| FileSystem.listStatus |
File.list |
readdir |
读取一个目录下的项目 |
| FileSystem.getWorkingDirectory |
|
getcwd/getwd |
返回当前工作目录 |
| FileSystem.setWorkingDirectory |
|
chdir |
更改当前工作目录 |
通过FileSystem.getFileStatus()方法,Hadoop抽象文件系统可以一次获得文件/目录的所有属性,这些属性被保存在类FileStatus中
public class FileStatus implements Writable, Comparable { private Path path; //文件路径 private long length; //文件长度 private boolean isdir; //是否是目录 private short block_replication; //副本数(为HDFS而准的特殊参数) private long blocksize; //块大小(为HDFS而准的特殊参数) private long modification_time; //最后修改时间 private long access_time; //最后访问时间 private FsPermission permission; //许可信息 private String owner; //文件所有者 private String group; //用户组 …… }
FileStatus实现了Writable接口,也就是说,FileStatus可以被序列化后在网络上传输,同时一次性将文件的所有属性读出并返回到客户端,可以减少在分布式系统中进行网络传输的次数
完整的FileStatus类的源代码如下:
 FileStatus
FileStatus
出现在FileSystem中的,但在java文件API中找不到对应的方法有:setReplication()、getReplication()、getContentSummary(),其声明如下:
public boolean setReplication(Path src, short replication) throws IOException { return true; } public short getReplication(Path src) throws IOException { return getFileStatus(src).getReplication(); } public ContentSummary getContentSummary(Path f) throws IOException { FileStatus status = getFileStatus(f); if (!status.isDir()) { // f is a file return new ContentSummary(status.getLen(), 1, 0); } // f is a directory long[] summary = {0, 0, 1}; for(FileStatus s : listStatus(f)) { ContentSummary c = s.isDir() ? getContentSummary(s.getPath()) : new ContentSummary(s.getLen(), 1, 0); summary[0] += c.getLength(); summary[1] += c.getFileCount(); summary[2] += c.getDirectoryCount(); } return new ContentSummary(summary[0], summary[1], summary[2]); }
实现一个Hadoop具体文件系统,需要实现的功能有哪些?下面整理org.apache.hadoop.fs.FileSystem中的抽象方法:
//获取文件系统URI public abstract URI getUri(); //为读打开一个文件,并返回一个输入流 public abstract FSDataInputStream open(Path f, int bufferSize) throws IOException; //创建一个文件,并返回一个输出流 public abstract FSDataOutputStream create(Path f, FsPermission permission, boolean overwrite, int bufferSize, short replication, long blockSize, Progressable progress) throws IOException; //在一个已经存在的文件中追加数据 public abstract FSDataOutputStream append(Path f, int bufferSize, Progressable progress) throws IOException; //修改文件名或目录名 public abstract boolean rename(Path src, Path dst) throws IOException; //删除文件 public abstract boolean delete(Path f) throws IOException; public abstract boolean delete(Path f, boolean recursive) throws IOException; //如果Path是一个目录,读取一个目录下的所有项目和项目属性 //如果Path是一个文件,获取文件属性 public abstract FileStatus[] listStatus(Path f) throws IOException; //设置当前的工作目录 public abstract void setWorkingDirectory(Path new_dir); //获取当前的工作目录 public abstract Path getWorkingDirectory(); //如果Path是一个文件,获取文件属性 public abstract boolean mkdirs(Path f, FsPermission permission ) throws IOException; //获取文件或目录的属性 public abstract FileStatus getFileStatus(Path f) throws IOException;
实现一个具体的文件系统,至少需要实现上面的这些抽象方法
hadoop完整的FileSystem类的源代码如下:
FileSystem
Hadoop 输入/输出流
Hadoop抽象文件系统和java类似,也是使用流机制进行文件的读写,用于读文件数据流和写文件的抽象类分别是:FSDataInputStream和FSDataOutputStream
1、FSDataInputStream
public class FSDataInputStream extends DataInputStream implements Seekable, PositionedReadable { …… }
可以看到,FSDataInputStream继承自DataInputStream类,实现了Seekable和PositionedReadable接口
Seekable接口提供在(文件)流中进行随机存取的方法,其功能类似于RandomAccessFile中的getFilePointer()和seek()方法,它提供了某种随机定位文件读取位置的能力
Seekable接口代码以及相关注释如下:
/** 接口,用于支持在流中定位. */ public interface Seekable { /** * 将当前偏移量设置到参数位置,下次读取数据将从该位置开始 */ void seek(long pos) throws IOException; /**得到当前偏移量 */ long getPos() throws IOException; /**重新选择一个副本 */ boolean seekToNewSource(long targetPos) throws IOException; }
完整的FSDataInputStream类源代码如下:
FSDataInputStream
FSDataInputStream实现的另一个接口是PositionedReadable,它提供了从流中某一个位置开始读数据的一系列方法:
//接口,用于在流中进行定位读 public interface PositionedReadable { //从指定位置开始,读最多指定长度的数据到buffer中offset开始的缓冲区中 //注意,该函数不改变读流的当前位置,同时,它是线程安全的 public int read(long position, byte[] buffer, int offset, int length) throws IOException; //从指定位置开始,读指定长度的数据到buffer中offset开始的缓冲区中 public void readFully(long position, byte[] buffer, int offset, int length) throws IOException; public void readFully(long position, byte[] buffer) throws IOException; }
PositionedReadable中的3个读方法,都不会改变流的当前位置,而且还是线程安全的
2、FSInputStream
org.apache.hadoop.fs包中还包含抽象类FSInputStream。Seekable接口和PositionedReadable中的方法都成为这个类的抽象方法
在FSInputStream类中,通过Seekable接口的seek()方法实现了PositionedReadable接口中的read()方法
//实现PositionedReadable.read()方法 public int read(long position, byte[] buffer, int offset, int length) throws IOException { /** * 由于PositionedReadable.read()是线程安全的,所以此处要借助synchronized (this) * 来保证方法被调用的时候其他方法不会被调用,也保证不会有其他线程改变Seekable.getPos()保存的 * 当前读位置 */ synchronized (this) { long oldPos = getPos(); //保存当前读的位置,调用 Seekable.getPos() int nread = -1; try { seek(position); //移动读数据的位置,调用Seekable.seek() nread = read(buffer, offset, length); //调用InputStream.read()读取数据 } finally { seek(oldPos); //调用Seekable.seek()恢复InputStream.read()前的位置 } return nread; } }
完整的FSInputStream源代码如下:
FSInputStream
注意:hadoop中没有相对应的FSOutputStream类
3、FSDataOutputStream
FSDataOutputStream用于写数据,和FSDataInputStream类似,继承自DataOutputStream,提供 writeInt()和writeChar()等方法,但是FSDataOutputStream更加的简单,没有实现Seekable接口,也就是说,Hadoop文件系统不支持随机写,用户不能在文件中重新定位写位置,并通过写数据来覆盖文件原有的内容。 单用户可以通过getPos()方法获得当前流的写位置,为了实现getPos()方法,FSDataOutputStream定义了内部类 PositionCache,该类继承自FilterOutputStream,并通过重载write()方法跟踪目前流的写位置.
PositionCache是一个典型的过滤流,在基础的流功能上添加了getPos()方法,同时利用FileSystem.Statistics实现了文件系统读写的一些统计。
public class FSDataOutputStream extends DataOutputStream implements Syncable { private OutputStream wrappedStream; private static class PositionCache extends FilterOutputStream { private FileSystem.Statistics statistics; long position; //当前流的写位置 public PositionCache(OutputStream out, FileSystem.Statistics stats, long pos) throws IOException { super(out); statistics = stats; position = pos; } public void write(int b) throws IOException { out.write(b); position++; //跟新当前位置 if (statistics != null) { statistics.incrementBytesWritten(1); //跟新文件统计值 } } public void write(byte b[], int off, int len) throws IOException { out.write(b, off, len); position += len; // update position if (statistics != null) { statistics.incrementBytesWritten(len); } } public long getPos() throws IOException { return position; //返回当前流的写位置 } public void close() throws IOException { out.close(); } } @Deprecated public FSDataOutputStream(OutputStream out) throws IOException { this(out, null); } public FSDataOutputStream(OutputStream out, FileSystem.Statistics stats) throws IOException { this(out, stats, 0); } public FSDataOutputStream(OutputStream out, FileSystem.Statistics stats, long startPosition) throws IOException { super(new PositionCache(out, stats, startPosition)); //直接生成PositionCache对象并调用父类构造方法 wrappedStream = out; } public long getPos() throws IOException { return ((PositionCache)out).getPos(); } public void close() throws IOException { out.close(); // This invokes PositionCache.close() } // Returns the underlying output stream. This is used by unit tests. public OutputStream getWrappedStream() { return wrappedStream; } /** {@inheritDoc} */ public void sync() throws IOException { if (wrappedStream instanceof Syncable) { ((Syncable)wrappedStream).sync(); } } }
FSDataOutputStream实现了Syncable接口,该接口只有一个函数sync(),其目的和Linux中系统调用sync()类似,用于将流中保存的数据同步到设备中
/** This interface declare the sync() operation. */ public interface Syncable { /** * Synchronize all buffer with the underlying devices. * @throws IOException */ public void sync() throws IOException; }