编写hadoop任务经常需要用到partition和排序。这里记录一下几个参数。
1. 概念
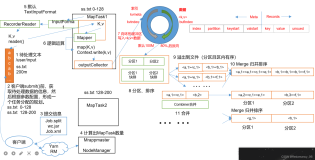
Partition:分桶过程,用户输出的key经过partition分发到不同的reduce里,因而partitioner就是分桶器,一般用平台默认的hash分桶也可以自己指定。
Key:是需要排序的字段,相同分桶&&相同key的行排序到一起。
2. 参数设置
在streaming模式默认中, hadoop会把map输出的一行中遇到的第一个设定的字段分隔符前面的部分作为key,后面的作为value,如果输出的一行中没有指定的字段分隔符,则整行作为key,value被设置为空字符串。streaming中默认字段分割符是tab。
2.1 reduce收到数据内的排序(实际上在map结果数据落时候已经排序)
我们知道,一个reduce收到的数据是经过排序的。
如下设置,reduce收到的数据如何排序: 字段分割符是'.',按照前2个字段排序。
stream.num.map.output.key.fields=2
stream.map.output.field.separator=.
2.2 map数据输出数据partition
我们知道可以指定partition参数使得符合条件的数据被后续的同一个reduce处理。
如下设置,指定字段分隔符是'.', 按照第一个字段进行pattition。
map.output.key.field.separator=.
num.key.fields.for.partition=1
参考: http://www.dreamingfish123.info/?p=1102