前言
对于上述锁其实是一个老生常谈的话题了,但是我们是否能够很明确的知道在什么情况下会存在上述各种锁类型呢,本节作为SQL Server系列末篇我们 来详细讲解下。
Range-Lock
上述关于RangeS-U、RangeS-S、RnageX-X以及还有RangeI-N这四种锁属于范围锁(Range-Lock)范畴。那么在什么情况下会存在范围锁呢,当在SERIALIZABLE最高隔离级别时范围锁将会被用到,这也就意味着直到事务开启到结束查询出的结果集是一致的以此来防止幻影。在该隔离级别中锁定的数据集合基于覆盖了所查询出的行的索引的键值范围,以此来确保锁定的范围的值不会被修改或者其他并发事务不会为相同的值范围插入新值,任何其他事务对范围内数据的修改、添加和删除都需要修改索引,所以此时将会被阻塞,因为范围锁覆盖了索引条目。下面我们一个个来分析何时出现哪种类型的范围锁。
RangeS-S
首先我们创建测试表
CREATE TABLE RangeLock (RId int NOT NULL IDENTITY (1, 1) PRIMARY KEY, Rname nvarchar (20), SName nvarchar (20))
接下来插入测试数据:
INSERT INTO [dbo].[RangeLock] ([RName]) VALUES ('anna'), ('antony'), ('angel'), ('ARLEN'), ('BENEDICT'), ('BILL'), ('BRYCE'), ('CAROL'), ('CEDRIC'), ('CLINT'), ('DARELL'), ('DAVID')

接下来我们设置最高隔离级别并开启事务查询,如下:
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE GO Begin Transaction GO SELECT RId FROM dbo.RangeLock WHERE RId = 1
我们看下此时的查询执行计划。

至于为何为聚集索引查找不用我再多讲了,此时会话Id为51接下来我们来检查锁。
sp_lock 51

什么情况怎么没有看见范围锁呢? 从上我们可以看出索引Id=1锁定的键的锁模式是正常的共享锁模式,并未出现我们所讲的在最高隔离级别下出现的范围锁更不用说RangeS-S范围锁了。别着急我们对RName建立一个非聚集索引看看。

我们再来查询RName的值,如下:
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE GO BEGIN TRAN GO SELECT RName FROM dbo.RangeLock WHERE RName = 'anna'
此时再来看看查询计划。

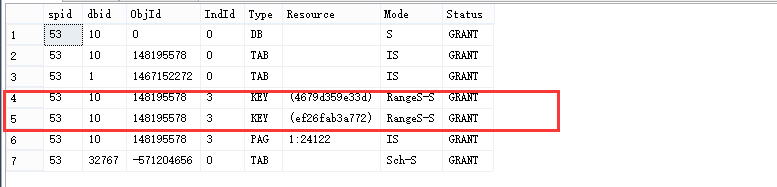
此时我们来分析分析上述图,对照我们根据默认创建的聚集索引去查询数据此时并未出现RangeS-S范围锁,而当对RName创建非聚集索引时此时出现了RangeS-S范围锁,同时上图显示此时有两个范围锁,我们明明查询一行数据为何会出现两个范围锁呢,这个时候我们要从最高级别所解决的问题讲起,SERIALIZABLE最高级别是为了解决幻影读取的问题也就是前后查询数据不一致问题,因为有了范围锁的出现,它会锁住我们所查询的那一行数据以及下一行数据,这样就确保了其他事务无法对当前事务中数据以及下一行数据进行更新、插入和删除。为了验证这一点我们在开启一个会话来删除上述查询数据的下一行数据
DELETE FROM dbo.RangeLock WHERE RName = 'antony'
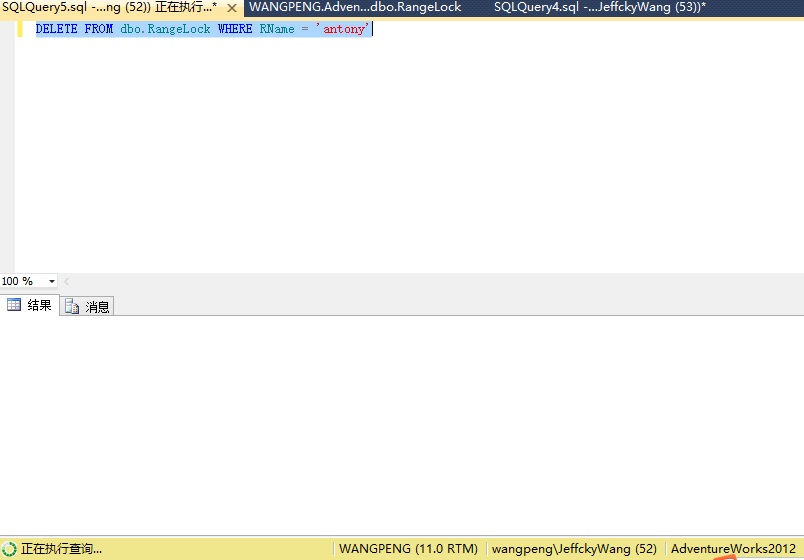
由上验证了我的观点,说了这么多范围锁肯定是有范围的,到这里我们来对范围锁下一个结论。
对于等值条件,如果所查询键存在且索引为非唯一索引此时才出现范围锁,在非唯一索引中锁定的是请求的键和该键的下一条,如果下一条数据不存在将无限扩充来进行范围限定,如果索引为聚集索引则呈现出的是常规的共享锁即使是我们设置最高隔离级别。
上述还结论还未完成,为了深刻讨论我们重新创建测试表和创建非聚集索引以便更清楚的认识到范围锁。
CREATE TABLE RangeLock (RId int NOT NULL IDENTITY (1, 1), RName nvarchar (20), SName nvarchar (20)) ALTER TABLE RangeLock ADD PRIMARY KEY (RId); CREATE NONCLUSTERED INDEX [ix_rname] ON [dbo].[RangeLock] ( [RName] ASC )
再插入上述测试表,我们再来查询该表。
SELECT * FROM dbo.RangeLock ORDER BY Rname

上述情况是查询的筛选条件即键是存在的,如果键不存在又当如何呢?
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE GO BEGIN TRAN GO SELECT RName FROM dbo.RangeLock WHERE RName = '键不存在'
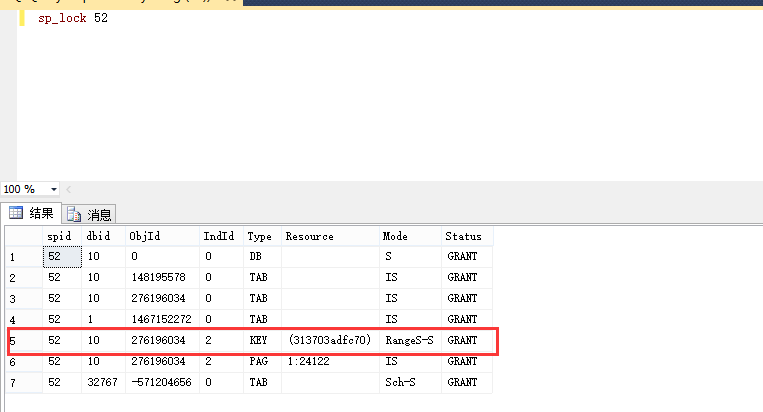
看出什么没有对于RName的索引Id等于2的情况依然存在范围锁,这种情况该如何解释呢,我们最终得出如下结论。
对于等值条件,如果所查询键存在且索引为非唯一索引此时才出现范围锁,在非唯一索引中锁定的是请求的键和该键的下一条,如果下一条数据不存在将无限扩充来进行范围限定,如果索引为聚集索引则呈现出的是常规的共享锁即使是我们设置最高隔离级别,如果查询键不存在那么无论是聚集索引还是非聚集索引,此时范围锁将锁住下一个键,如果下一个键不存在,那么将无限扩充来进行范围锁定。
RangeS-U
分析完RangeS-S接下来我们分析RangeS-U范围锁。在什么情况下会出现RangeS-U范围锁呢,要出现RangeS-U必须满足以下三个条件。
(1)事务中必须包含一条更新语句。
(2)在WHERE上指定一个筛选条件并且限制更新行数,同时条件至少有一个来自于索引,也就是说定义了来自于索引的键值范围
(3)更新列不能包含索引定义。
我们直接看上述已经创建的测试表,并作如下更新。
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE GO BEGIN TRAN GO UPDATE dbo.RangeLock SET SName ='surname' WHERE Rname BETWEEN 'anna' AND 'arlen'
此时我们来看看查询执行计划。

此时我们看到的聚集索引更新和在列RName上的非聚集索引查找,也就说定义了索引查找的范围。
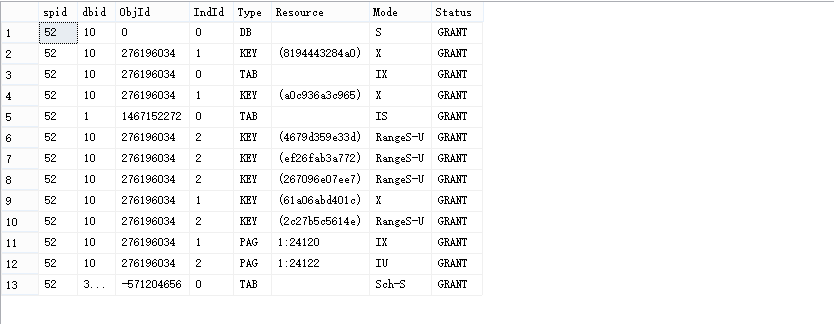
由上我们看到三行在主键上的排它锁来用于主键更新,因为我们的值在anna和arlen之间,在表中存在三行数据,但是在IndId = 2获得在ix_rname上的RangeS-U范围锁却有四行,让我们惊讶不已,但是在表中实际上只有三行,这又是为何,说明第四行锁的键在BARRY上。不行我们对第四行进行更新试试看。
begin transaction UPDATE dbo.RangeLock SET RName = 'Jeffcky' WHERE RName = 'barry'
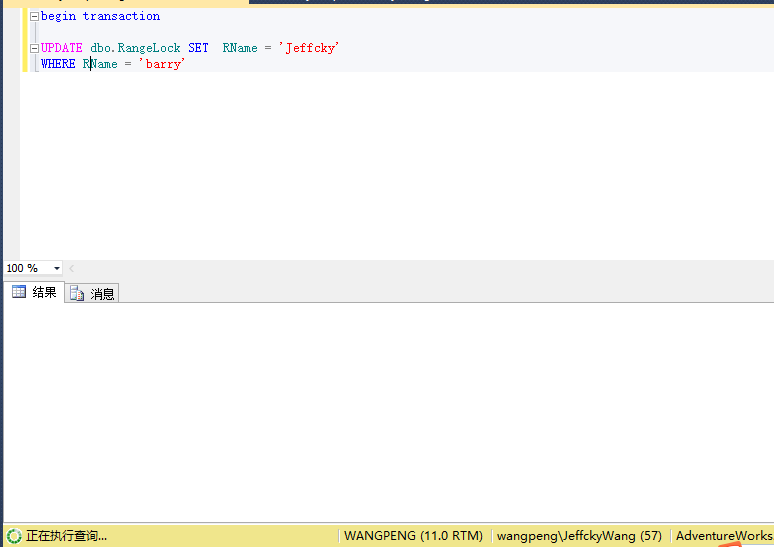
由上证明了我的观点,此时虽然查询的是三行的数据,但是实际上RangeS-U范围锁锁定的不仅仅是三行还有下一行数据。我们保持第四行阻塞,在查询中来看看二者进程中的锁情况。
sp_lock 54 GO sp_lock 57 GO
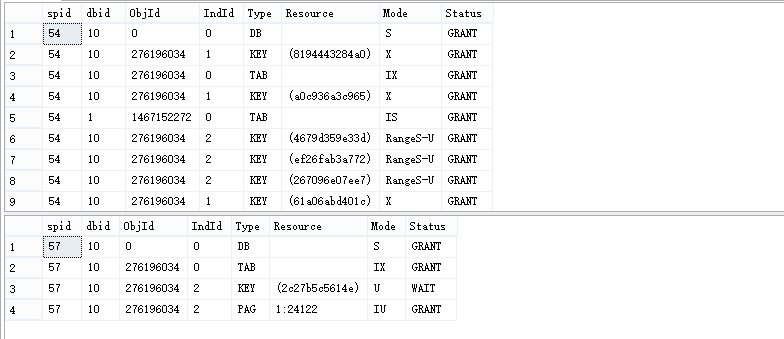
我们能够看到对于更新BARRY的第四行数据此时处于WAIT状态即阻塞。基于上述讨论我们得出如下结论:
对于范围条件,无论是聚集索引还是非聚集索引在该范围的所有键都会被范围锁锁定,同时也会锁定下一个键即超出更新或者查询范围,这样就确保了在所请求的键和下一行数据之间都不能插入新行,如果下一个键不存在则无限扩充来进行范围锁定。
对于RangeS-U范围锁意味着其他事务对于相同行的查询是被允许的,若其他事务对范围键中值进行更新则会出现阻塞,直到当前事务被提交或回滚才被允许。
RangeX-X
从字面意思理解这个就是排他范围锁了,当一个事务更新一个有索引的键时,它会获取索引键上的排他锁特定的范围,此时则意味着其他事务对该键执行的添加、删除或者修改都会被阻塞直到当前事务完成。我们看看如下例子:
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE GO BEGIN TRAN GO UPDATE dbo.RangeLock SET RName ='ana' WHERE RName = 'anna'

我们看到一个聚集索引更新和对ix_rname上的索引查找定义了对于要查找的键范围。初始一看有点像上述RangeS-U范围锁,此时我们将鼠标放在聚集索引更新上看到如下所示:
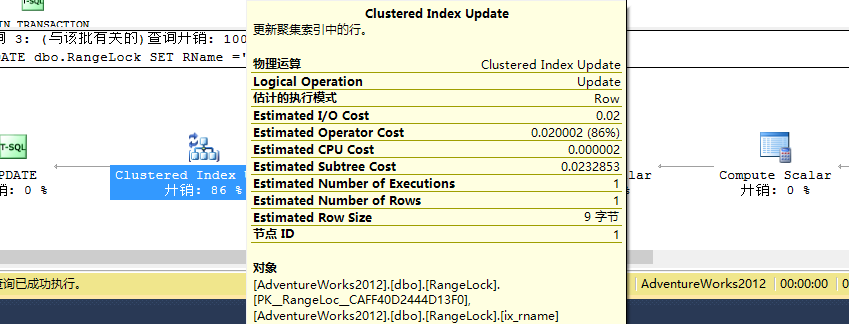
我们看到上述有两个索引,一个是主键的聚集索引,一个是ix_rname上的非聚集索引,聚集索引基于表中的主键对数据行进行排序,当然此时表中的所有数据行也可以称为叶子节点,因为聚集索引叶子节点存的就是实际数据行,而主键值包含了指向所有行的指针,所以对除主键列以外的数据行进行更新都将导致聚集索引上的叶子节点进行对应的更新。我们看看此时锁的类型:
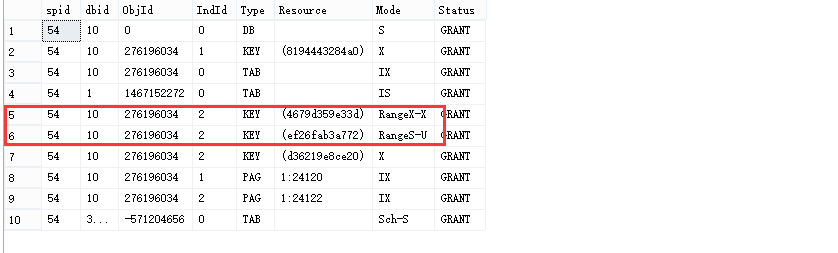
由于需要对索引进行更新此时在主键上有一个排它锁,同时呢,我们看到对于ix_rname的索引上键保持了两种范围锁,一种是RangeS-U,另外一种则是RangeX-X。由于此时对anna采取了RangeX-X排他范围锁,那么存在的RangeS-U更新范围锁根据我们之前的经验来猜测此时RangeS-U对应的是RName = anna的下一行,我们来证明下:
BEGIN TRANSACTION SELECT RName FROM dbo.RangeLock WHERE RName = 'antony'

不要惊讶上述为什么会查询出数据而不会更新,根据我们的假设此时antony对应的是RangeS-U更新范围锁的话,那么此时查询相同的行绝对不会出现阻塞,下面我们来看看在另外一个会话中来更新:
BEGIN TRANSACTION UPDATE dbo.RangeLock SET RName = 'Jeffcky' WHERE RName = 'antony'
此时我们再来对比此时两个会话中的锁情况。
sp_lock 54 GO sp_lock 56 GO

我们马上能看到对于相同的数据行,第二个会话进行数据行的更新此时将被RangeS-U更新范围锁所锁定导致等待阻塞。至此我们对RangeX-X来下个结论:
对于RangeX-X排他范围锁,它仅仅只锁定实际的修改列,对于修改的下一列将不再锁定而是利用RangeS-U更新范围锁来锁定以便在事务提交之前来维护数据的完整性直到事务提交。
总结
对于SERIALIZABLE最高隔离级别中的四种范围锁类型的分析和窥探,想必我们大概了解了为什么它会防止幻影,比如典型的当第一次查询数据行为空,而第二次查询数据行也是为空,不会出行幻影的情况则是利用RangeS-S范围锁,因为查询的键根本不存在那么将导致范围锁定进行无限扩充从而导致整个表被锁定,最终多次查询的数据行必定一致而不是幻影。至此关于SQL Server基础系列到这里接近尾声,在这里为了阅读者看起来方便列出SQL Server系列所有文章以便查阅。
http://www.cnblogs.com/CreateMyself/p/6099560.html(SQL Server-语句类别、数据库范式、系统数据库组成(一))
http://www.cnblogs.com/CreateMyself/p/6104345.html(SQL Server-数据库架构和对象、定义数据完整性(二))
http://www.cnblogs.com/CreateMyself/p/6107209.html(SQL Server-简单查询语句,疑惑篇(三))
http://www.cnblogs.com/CreateMyself/p/6115160.html(SQL Server-聚焦聚集索引对非聚集索引的影响(四))
http://www.cnblogs.com/CreateMyself/p/6115736.html(SQL Server-聚焦使用索引和查询执行计划(五))
http://www.cnblogs.com/CreateMyself/p/6123586.html(SQL Server-数据类型(七))
http://www.cnblogs.com/CreateMyself/p/6127186.html(SQL Server-分页方式、ISNULL与COALESCE性能分析(八))
http://www.cnblogs.com/CreateMyself/p/6127830.html(SQL Server-聚焦强制索引查询条件和Columnstore Index(九))
http://www.cnblogs.com/CreateMyself/p/6129924.html(SQL Server-聚焦过滤索引提高查询性能(十))
http://www.cnblogs.com/CreateMyself/p/6138996.html(SQL Server-简单查询示例(十一))
http://www.cnblogs.com/CreateMyself/p/6142275.html(SQL Server-交叉联接、内部联接基础回顾(十二))
http://www.cnblogs.com/CreateMyself/p/6146909.html(SQL Server-外部联接基础回顾(十三))
http://www.cnblogs.com/CreateMyself/p/6147883.html(SQL Server-聚焦INNER JOIN AND IN性能分析(十四))
http://www.cnblogs.com/CreateMyself/p/6154688.html(SQL Server-聚焦NOT EXISTS AND NOT IN性能分析(十五))
http://www.cnblogs.com/CreateMyself/p/6155480.html(SQL Server-聚焦EXISTS AND IN性能分析(十六))
http://www.cnblogs.com/CreateMyself/p/6165982.html(SQL Server-聚焦IN VS EXISTS VS JOIN性能分析(十九))
http://www.cnblogs.com/CreateMyself/p/6183179.html(SQL Server-聚焦计算列持久化(二十一))
http://www.cnblogs.com/CreateMyself/p/6184749.html(SQL Server-聚焦计算列或计算列持久化查询性能(二十二))
http://www.cnblogs.com/CreateMyself/p/6185286.html(SQL Server-聚焦UNIOL ALL/UNION查询(二十三))
http://www.cnblogs.com/CreateMyself/p/6188447.html(SQL Server-表表达式基础回顾(二十四))
http://www.cnblogs.com/CreateMyself/p/6189548.html(SQL Server-聚焦使用视图若干限制/建议、视图查询性能问题,你懵逼了?(二十五))
http://www.cnblogs.com/CreateMyself/p/6193163.html(SQL Server-聚焦在视图和UDF中使用SCHEMABINDING(二十六))
http://www.cnblogs.com/CreateMyself/p/6193183.html(SQL Server-聚焦APPLY运算符(二十七))
http://www.cnblogs.com/CreateMyself/p/6347895.html(SQL Server-索引故事的遥远由来,原来是这样的?(二十八))
http://www.cnblogs.com/CreateMyself/p/6352167.html(SQL Server-聚焦事务、隔离级别详解(二十九))
http://www.cnblogs.com/CreateMyself/p/6361825.html(SQL Server-聚焦SNAPSHOT基于行版本隔离级别详解(三十))
http://www.cnblogs.com/CreateMyself/p/6361825.html(SQL Server-聚焦SNAPSHOT基于行版本隔离级别详解(三十))
http://www.cnblogs.com/CreateMyself/p/6395670.html(SQL Server-聚焦事务对本地变量、临时表、表变量影响以及日志文件存满时如何收缩(三十一))
http://www.cnblogs.com/CreateMyself/p/6411676.html(SQL Server-聚焦深入理解动态SQL查询(三十二))
http://www.cnblogs.com/CreateMyself/p/6362904.html(SQL Server-聚焦深入理解死锁以及避免死锁建议(三十三))
路漫漫其修远兮,吾将上下而求索,不求一时的安逸,远离舒适,远离安逸,为可能存在的价值创造最大的可能性。
