前言
上一篇Selenium2+python自动化23-富文本(自动发帖)解决了富文本上iframe问题,其实没什么特别之处,主要是iframe的切换,本篇讲解通过js的方法处理富文本上iframe的问题
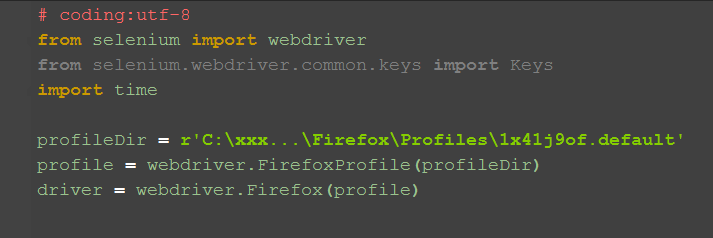
一、加载配置
1.打开博客园写随笔,首先需要登录,这里为了避免透露个人账户信息,我直接加载配置文件,免登录了。
不懂如何加载配置文件的,看这篇Selenium2+python自动化18-加载Firefox配置
二、打开编辑界面
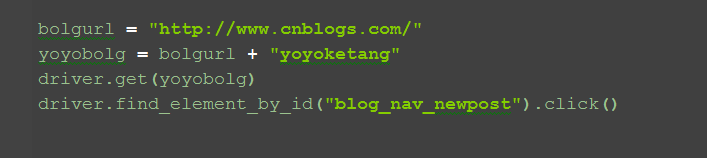
1.博客首页地址:bolgurl = "http://www.cnblogs.com/"
2.我的博客园地址:yoyobolg = bolgurl + "yoyoketang"
3.点击“新随笔”按钮,id=blog_nav_newpost
三、定位iframe
1.打开编辑界面后先不要急着输入内容,先sleep几秒钟
2.输入标题,这里直接通过id就可以定位到,没什么难点
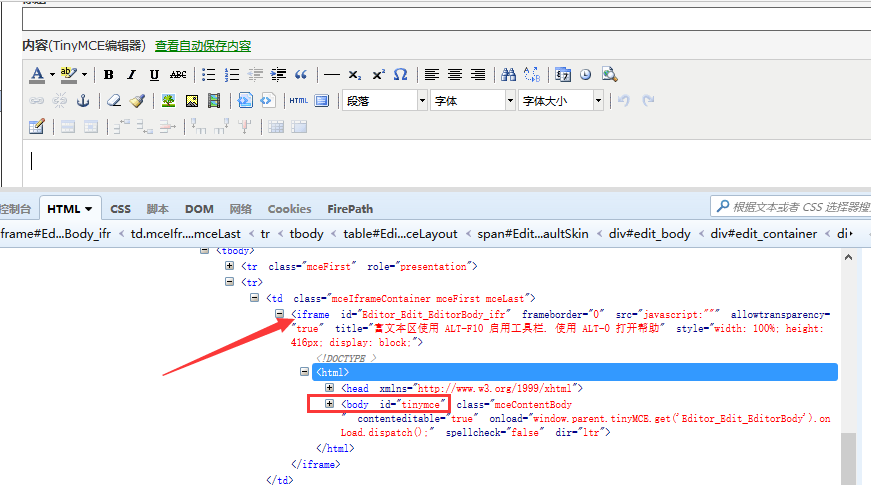
3.接下来就是重点要讲的富文本的编辑,这里编辑框有个iframe,所以需要先切换
(关于iframe不懂的可以看前面这篇:Selenium2+python自动化14-iframe)
四、js输入中文
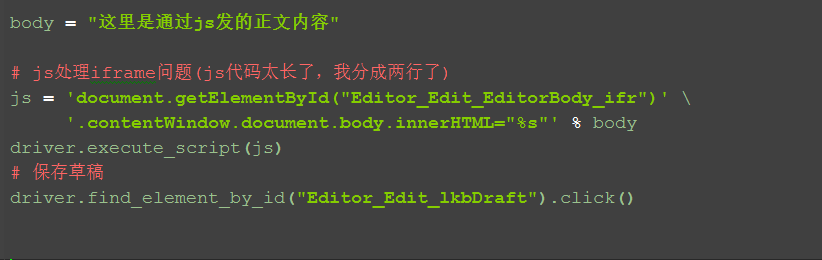
1.这里定位编辑正文是定位上图的红色框框位置body部分,也就是id=tinymce
2.定位到之后,用js的方法直接输入,无需切换iframe
3.直接点保存按钮,无需再切回来
五、参考代码:
# coding:utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
# profileDir路径对应直接电脑的配置路径
profileDir = r'C:\xxx\xxx\AppData\Roaming\Mozilla\Firefox\Profiles\1x41j9of.default'
profile = webdriver.FirefoxProfile(profileDir)
driver = webdriver.Firefox(profile)
bolgurl = "http://www.cnblogs.com/"
yoyobolg = bolgurl + "yoyoketang"
driver.get(yoyobolg)
driver.find_element_by_id("blog_nav_newpost").click()
time.sleep(5)
edittile = u"Selenium2+python自动化23-富文本"
editbody = u"这里是发帖的正文"
driver.find_element_by_id("Editor_Edit_txbTitle").send_keys(edittile)
body = "这里是通过js发的正文内容"
# js处理iframe问题(js代码太长了,我分成两行了)
js = 'document.getElementById("Editor_Edit_EditorBody_ifr")' \
'.contentWindow.document.body.innerHTML="%s"' % body
driver.execute_script(js)
# 保存草稿
driver.find_element_by_id("Editor_Edit_lkbDraft").click()
在学习过程中有遇到疑问的,可以加selenium(python+java) QQ群交流:646645429
《selenium+python高级教程》已出书:selenium webdriver基于Python源码案例
(购买此书送对应PDF版本)

