前言
验证码这种问题是比较头疼的,对于验证码的处理,不要去想破解方法,这个验证码本来就是为了防止别人自动化登录的。如果你能破解,说明你们公司的验证码吗安全级别不高,那就需要提高级别了。
对于验证码,要么是让开发在测试环境弄个万能的验证码,如:1234,要么就是尽量绕过去,如本篇介绍的添加cookie的方法。
一、fiddler抓包
1.前一篇讲到,登录后会生成一个已登录状态的cookie,那么只需要直接把这个值添加到cookies里面就可以了。
2.可以先手动登录一次,然后抓取这个cookie,这里就需要用抓包工具fiddler了
3.先打开博客园登录界面,手动输入账号和密码(不要点登录按钮)
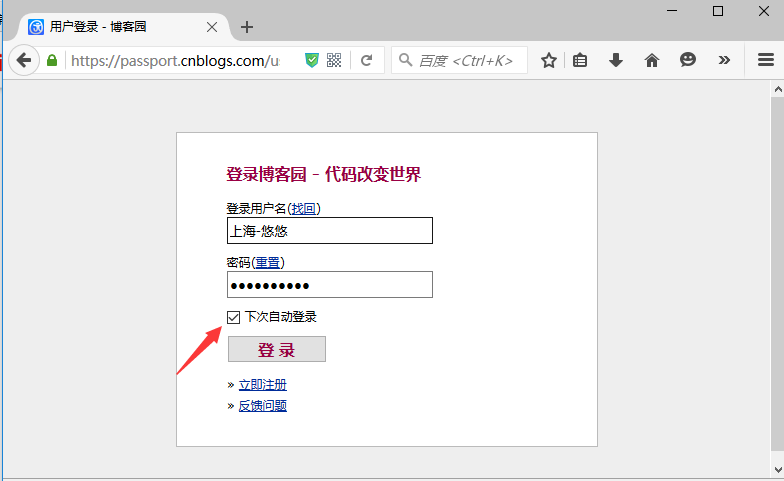
4.打开fiddler抓包工具,此时再点博客园登录按钮
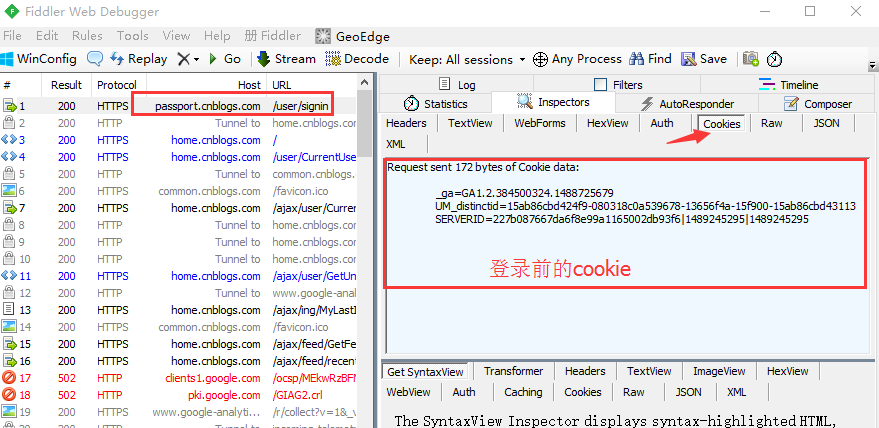
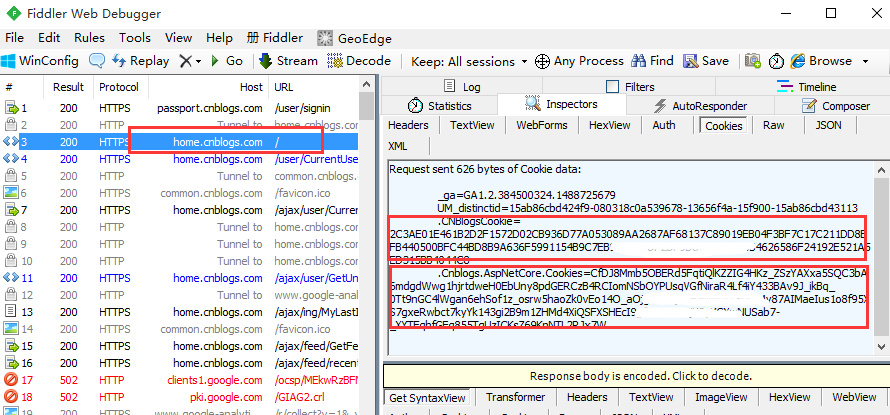
5.登录成功后,再查看cookie变化,发现多了两组参数,多的这两组参数就是我们想要的,copy出来,一会有用
二、添加cookie方法:driver.add_cookie()
1.add_cookie(cookie_dict)方法里面参数是cookie_dict,说明里面参数是字典类型。
2.源码官方文档介绍:
add_cookie(self, cookie_dict)
Adds a cookie to your current session.
:Args:
- cookie_dict: A dictionary object, with required keys - "name" and "value";
optional keys - "path", "domain", "secure", "expiry"
Usage:
driver.add_cookie({'name' : 'foo', 'value' : 'bar'})
driver.add_cookie({'name' : 'foo', 'value' : 'bar', 'path' : '/'})
driver.add_cookie({'name' : 'foo', 'value' : 'bar', 'path' : '/', 'secure':True})
3.从官方的文档里面可以看出,添加cookie时候传入字典类型就可以了,等号左边的是name,等号左边的是value。
4.把前面抓到的两组数据(参数不仅仅只有name和value),写成字典类型:
{'name':'.CNBlogsCookie','value':'2C3AE01E461B2D2F1572D02CB936D77A053089AA2xxxx...'}
{'name':'.Cnblogs.AspNetCore.Cookies','value':'CfDJ8Mmb5OBERd5FqtiQlKZZIG4HKz_Zxxx...'}
三、cookie组成结构
1.用抓包工具fidller只能看到cookie的name和value两个参数,实际上cookie还有其它参数
2.cookie参数组成,以下参数是我通过get_cookie(name)获取到的,
参考上一篇:Selenium2+python自动化40-cookie相关操作
cookie ={u'domain': u'.cnblogs.com',
u'name': u'.CNBlogsCookie',
u'value': u'xxxx',
u'expiry': 1491887887,
u'path': u'/',
u'httpOnly': True,
u'secure': False}
name:cookie的名称
value:cookie对应的值,动态生成的
domain:服务器域名
expiry:Cookie有效终止日期
path:Path属性定义了Web服务器上哪些路径下的页面可获取服务器设置的Cookie
httpOnly:防脚本攻击
secure:在Cookie中标记该变量,表明只有当浏览器和Web Server之间的通信协议为加密认证协议时,
浏览器才向服务器提交相应的Cookie。当前这种协议只有一种,即为HTTPS。
四、添加cookie
1.这里需要添加两个cookie,一个是.CNBlogsCookie,另外一个是.Cnblogs.AspNetCore.Cookies。
2.我这里打开的网页是博客的主页:http://www.cnblogs.com/yoyoketang,没进入登录页。
3.添加cookie后刷新页面,接下来就是见证奇迹的时刻了。
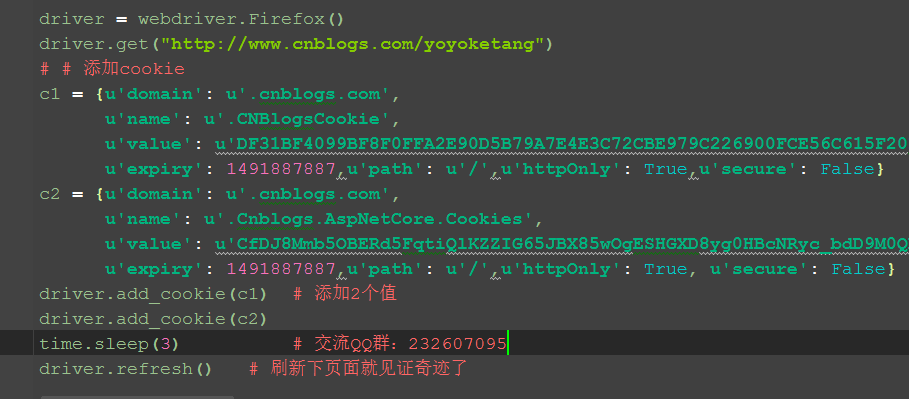
五、参考代码:
# coding:utf-8
from selenium import webdriver
import time
driver = webdriver.Firefox()
driver.get("http://www.cnblogs.com/yoyoketang")
# # 添加cookie
c1 = {u'domain': u'.cnblogs.com',
u'name': u'.CNBlogsCookie',
u'value': u'xxxx',
u'expiry': 1491887887,
u'path': u'/',
u'httpOnly': True,
u'secure': False}
c2 = {u'domain': u'.cnblogs.com',
u'name': u'.Cnblogs.AspNetCore.Cookies',
u'value': u'xxxx',
u'expiry': 1491887887,
u'path': u'/',
u'httpOnly': True,
u'secure': False}
driver.add_cookie(c1) # 添加2个值
driver.add_cookie(c2)
time.sleep(3) # 交流QQ群:232607095
# 刷新下页面就见证奇迹了
driver.refresh()
有几点需要注意:
1.登录时候要勾选下次自动登录按钮。
2.add_cookie()只添加name和value,对于博客园的登录是不成功。
3.本方法并不适合所有的网站,一般像博客园这种记住登录状态的才会适合。
学习过程中有遇到疑问的,可以加selenium(python+java) QQ群交流:646645429
另外成立了python接口自动化QQ群:226296743
selenium+python高级教程》已出书:selenium webdriver基于Python源码案例
(购买此书送对应PDF版本)

