优化html报告
为了满足小伙伴的各种变态需求,为了装逼提升逼格,为了让报告更加高大上,测试报告做了以下优化:
- 测试报告中文显示,优化一些断言失败正文乱码问题
- 新增错误和失败截图,展示到html报告里
- 优化点击截图放大不清晰问题
- 增加饼图统计
- 失败后重试功能
- 兼容python2.x 和3.x
报告效果
1.生成的测试报告效果如下图,默认展示报错和异常的用例,失败重试的用例结果也会统计进去。
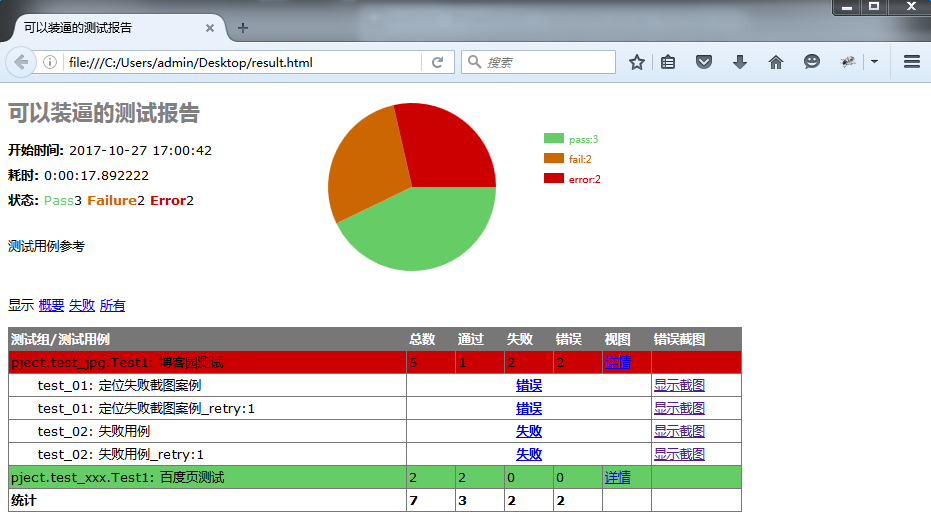
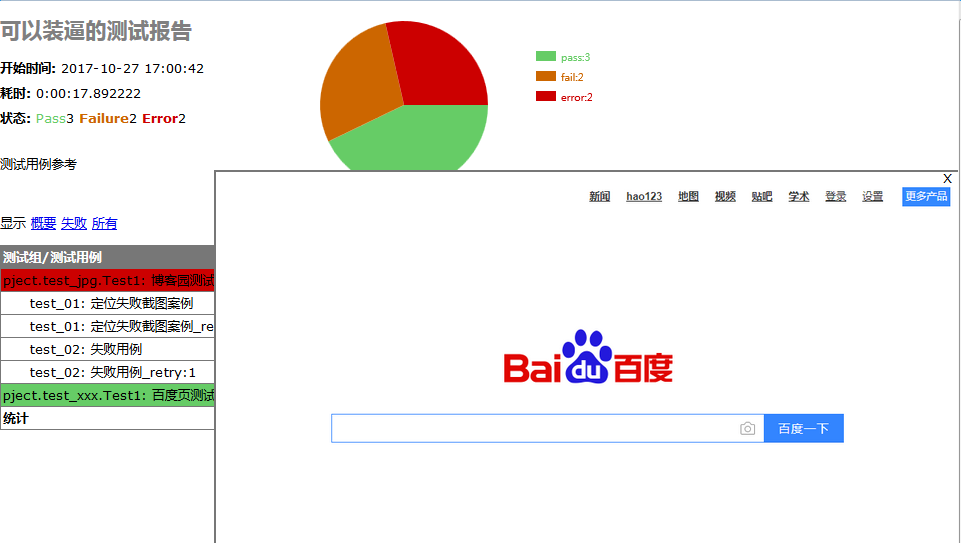
2.点击显示截图,可以直接显示截取的图片,无需保存到本地
table表格
1.修改表格的td后面内容,可以自定义表格名称
2.drawCircle这个后面是生成饼图功能
<tr id='header_row'>
<td>测试组/测试用例</td>
<td>总数</td>
<td>通过</td>
<td>失败</td>
<td>错误</td>
<td>视图</td>
<td>错误截图</td>
</tr>
%(test_list)s
<tr id='total_row'>
<td>统计</td>
<td>%(count)s</td>
<td>%(Pass)s</td>
<td>%(fail)s</td>
<td>%(error)s</td>
<td> </td>
<td> </td>
</tr>
</table>
<script>
drawCircle(%(Pass)s, %(fail)s, %(error)s)
</script>异常截图
1.这个是用例跑失败后,会自动截图的,图片以base64方式存储到html报告里面,无需保存到本地
driver.get_screenshot_as_base64()
def addError(self, test, err):
self.error_count += 1
self.status = 1
TestResult.addError(self, test, err)
_, _exc_str = self.errors[-1]
output = self.complete_output()
self.result.append((2, test, output, _exc_str))
try:
driver = getattr(test, "driver")
test.img = driver.get_screenshot_as_base64()
except AttributeError:
test.img = ""
if self.verbosity > 1:
sys.stderr.write('E ')
sys.stderr.write(str(test))
sys.stderr.write('\n')
else:
sys.stderr.write('E')2.测试用例一定要定义driver参数,如:
driver = webdriver.Firefox()
失败重试
1.生成报告的参数里面加了一个参数retry=1,这个表示用例失败后,会重新跑一次。
# coding:utf-8
import HTMLTestRunner_jpg
import unittest
if __name__ == "__main__":
discover = unittest.defaultTestLoader.discover("case","test*.py")
print(discover)
run = HTMLTestRunner_jpg.HTMLTestRunner(title="可以装逼的测试报告",
description="测试结果",
stream=open("result.html","wb"),
verbosity=2,
retry=1)
run.run(discover)2.verbosity=2这个参数是控制台显示测试结果风格,如下这种:
E test_01 (pject.test_jpg.Test1)
retesting... 1
E test_01 (pject.test_jpg.Test1)
F test_02 (pject.test_jpg.Test1)
retesting... 1
F test_02 (pject.test_jpg.Test1)
ok test_03 (pject.test_jpg.Test1)
ok test_01 (pject.test_xxx.Test1)
ok test_02 (pject.test_xxx.Test1)
Time Elapsed: 0:00:17.892222执行用例
1.这是参考的测试用例,我没在用例里面生成测试报告,生成测试报告采用的是上面的批量执行,单独建个脚本执行
# coding:utf-8
from selenium import webdriver
import unittest
class Test1(unittest.TestCase):
u'''博客园测试'''
@classmethod
def setUpClass(cls):
cls.driver = webdriver.Firefox()
@classmethod
def tearDownClass(cls):
cls.driver.quit()
def test_01(self):
u"""定位失败截图案例"""
self.driver.get("https://www.baidu.com")
self.driver.find_element_by_id('xxxxx').send_keys(u'百度一下')
self.driver.find_element_by_id('su').click()
self.assertTrue(True)
def test_02(self):
u'''失败用例'''
self.driver.get("http://www.cnblogs.com/yoyoketang/")
t = self.driver.title
self.assertIn(u"失败用例",t)
def test_03(self):
u'''通过用例'''
self.driver.get("http://www.cnblogs.com/yoyoketang/")
self.assertIn(u"上海",self.driver.title)
if __name__ == "__main__":
unittest.main()参考大神github
优化后源码
1.这个是在大神的基础上稍微做了一点点图片显示的优化,之前的图片太小,显示模糊,放大了下
2.然后重新整理了下,采用批量执行用例的方式
seleniumQQ群:646645429
3.参考代码从github下载吧
https://github.com/yoyoketang/selenium_report/
学习过程中有遇到疑问的,可以加selenium(python+java) QQ群交流:646645429
《selenium webdriver基于python源码案例》已出书:selenium webdriver基于Python源码案例(购买此书送对应PDF版本)
