一、引言
前段时间,在优雅的使用pt-archiver进行数据归档一文中介绍了pt-archiver的使用方法,也将pt-archiver部署到了生产环境,这时候问题来了~
生产环境需要做归档的任务有十几个,如果要知道每个归档任务成功与否、跑了多长时间、归档了多少数据,就得手工逐个查看日志,非常枯燥的重复劳动,那是否有办法可以统一管理呢?
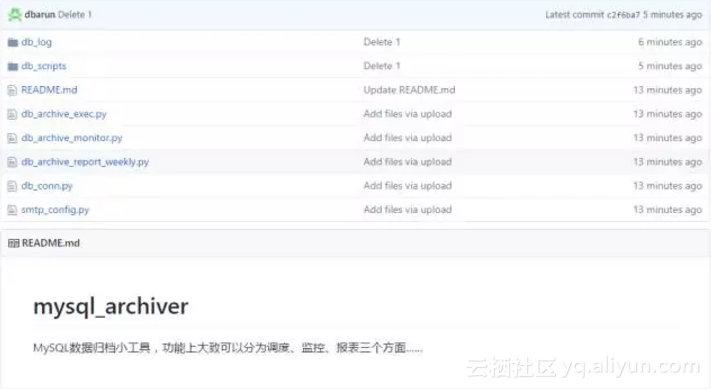
于是用python倒腾了一个小工具—mysql_archiver小工具,github地址:https://github.com/dbarun/mysql_archiver
二、mysql_archiver
2.1 归档调度
db_archive_exec.py,从数据库获取归档任务的基本信息,调用pt-archiver进行操作
2.1.1 表结构设计
表db_archive_info,主要存放归档任务的基本信息

表db_archive_log,主要存放归档任务的执行日志

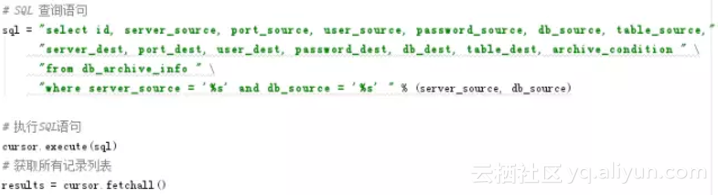
2.1.2 获取归档任务
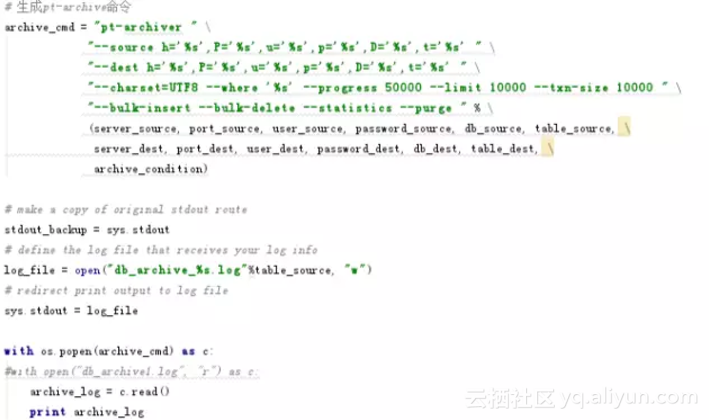
2.1.3 调用pt-archiver
2.1.4 部署crontab
执行db_archive_exec.py需要指定两个参数,
参数1:db ip/域名
参数2:db schema
如:python db_archive_exec.py 127.0.0.1 db123
![]()
2.2 归档监控
db_archive_monitor.py,监控前一次的归档任务是否执行成功,并结合zabbix进行报警

2.2.1 数据库视图设计
视图vw_db_archive_fail,汇总前一天执行失败的归档任务

2.2.2 获取归档监控信息

2.2.3 通过logger生成文本
2.3 归档报表
db_archive_report_weekly.py,生成前一周的归档情况,并以邮件方式发送
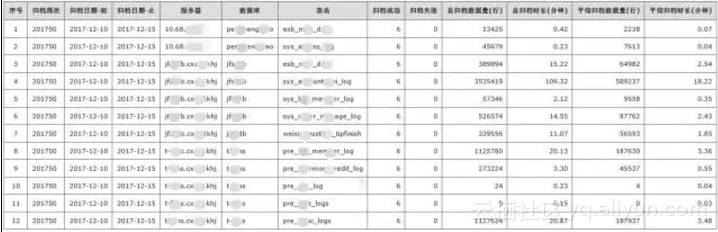
2.3.1 表结构设计
表db_archive_report_weekly,主要存放数据库归档周报数据

2.3.2 数据库视图设计
视图vw_db_archive_report_weekly,计算前一周的数据库归档情况

2.3.3 生成邮件内容

三、小结
开发运维工具,说白了,就是为了避免重复的运维工作,让运维尽可能地自动化。所以,能提高生产力的工具,我觉得都是好工具。
MySQL_archiver基本上实现了数据归档的自动运转,统一的归档任务调度管理、自动监控和预警、自动生成报表。在一定程度上节约了生产力,提高了运维效率。
MySQL_archiver也是存在很多缺点的,比如:Python代码有点臃肿,不够简洁;缺少可视化的操作界面,如果能有一套运维平台,那就完美了。
原文发布时间为:2017-12-26
本文作者:蓝剑锋


